
Abstract
Since computing semantic similarity tends to simulate the thinking process of humans, semantic dissimilarity must play a part in this process. In this paper, we present a new approach for semantic similarity measuring by taking consideration of dissimilarity into the process of computation. Specifically, the proposed measures explore the potential antonymy in the hierarchical structure of WordNet to represent the dissimilarity between concepts and then combine the dissimilarity with the results of existing methods to achieve semantic similarity results. The relation between parameters and the correlation value is discussed in detail. The proposed model is then applied to different text granularity levels to validate the correctness on similarity measurement. Experimental results show that the proposed approach not only achieves high correlation value against human ratings but also has effective improvement to existing path-distance based methods on the word similarity level, in the meanwhile effectively correct existing sentence similarity method in some cases in Microsoft Research Paraphrase Corpus and SemEval-2014 date set.
Introduction
As one of the most important components of big data, the scale of texts grows with people’s life. Meanwhile, it brings more challenges for text processing such as automatic text understanding and word spelling error detection and correction [1]. To solve this problem, semantic similarity measuring is used to determine the semantic association of words and measure the hidden similarity of lexical meanings under the surface form similarity of concepts [2]. The methods have been improved with the continuous effort of researchers. In the beginning, there are only methods [3, 4, 5, 6, 7] measuring semantic similarity through “is-a” relation between words. Now more multiple semantic relation-based approaches [8, 9, 10, 11, 12, 13] have been proposed by considering more relations such as “part-of”.
Comparing with the high degree of dependence on the corpus and the high computational complexity of corpus-based measures, knowledge-based measures are more suitable for the similarity computation issues. Most state-of-the-art approaches based on the lexical knowledge database WordNet [15] are proposed to measure concept semantic similarity [4, 7, 11, 14, 16]. WordNet is a large English semantic dictionary. Nouns, verbs, adjectives, and adverbs in WordNet are grouped into sets of cognitive synonyms (synsets) with each expressing a distinct concept. Synsets are interconnected through conceptual-semantic and lexical relations. At first, researchers only use “is-a” relation to compute the semantic similarity and apply this relation to generate three major attributes of concepts, path distance, information content (IC), and feature with each attribute representing a calculative strategy. Path-distance based approaches [3, 4, 17, 18, 19] regard all the edges between any two synsets are equal to 1 and count the least edges connecting the compared concepts. The less the value of the semantic distance between two concepts, the more similar they are. Thus, the semantic distance between the same concepts is 0. While the approaches based on IC [20, 21, 22, 23, 24] assume that each synset is unique due to their different structures which concludes the scale of ancestor nodes, hypernyms, hyponyms and so on. Therefore, IC-based approaches use IC value to represent concepts’ structure, abstract quantity, and IC of concepts. A concept’s IC value will rise with its abstract quantity. For two given concepts, the similarity between them not only depends on the information on their own but also depends on what they have in common. In the feature-based approaches [25, 26, 27, 28, 29, 30], a concept is represented as a feature vector in which the features are derived from WordNet such as gloss, hypernyms, and hyponyms. If two concepts have more features in common, they are more similar.
According to the research of paper [31] and our observation, most of the WordNet-based measures don’t use the structures of WordNet to their full potential. For example, methods that neglect the antonymy may lead to higher similarity results. Therefore, the main motivation for this work is to find a structure which can make full use of antonymy and correct the over-similar situations. Our main hypothesis is that antonymy between words can support a negative effect on the semantic similarity values of concepts. It is just like the effect in which we should consider the similarity between “boy” and “girl” while computing the similarity between “boy” and “nun”.
The aim of this paper is to answer two research problems:
RQ1: What kind of structure can make full use of the antonymy? RQ2: How effective is antonymy during similarity computation?
Our approach mainly contributes to:
An implementation and comparison of existing representative approaches with their calculation factors. An model to introduce the antonymy as dissimilarity between concepts into the process of similarity computation. A conducted experiment showing that the proposed model performs well in terms of correlation value on WordNet-based models.
The rest of this paper is organized as follows. Section 2 introduces the main WordNet-based similarity measures. Section 3 presents the new factor for semantic similarity measuring. Applications on different text granularity levels and experiment results of the proposed model are shown in Section 4. Section 5 discusses the results obtained by different approaches. In Section 6, conclusions and future researches are presented.
In this section, we take an overview of the WordNet-based semantic similarity methods. According to the number of relations being used, methods can be roughly divided into “is-a” relation-based methods, multiple semantic relation-based methods, and feature-based methods.
“Is-a” relation-based methods
The “is-a” relation accounts for nearly 80% of all link types in WordNet, and it shows the hypotaxis between synsets. So it commonly is the first-choice or even the only-choice in the process. According to the different ways of using this relation, the “is-a” relation-based methods can be divided into path-based measures and IC-based measures.
Path-distance based
The main idea of path-based measures lies in the fact that the similarity between two concepts is a function of the path distance linking the concepts and their positions in the taxonomy.
Rada et al. [3] proposed that ontologies can be treated as a directed graph which is composed of concepts linked by multiple semantic relationships such as by taxonomic (“is-a”) links. Therefore, for two given concepts
However, Rada’s method has a flaw that the similarities of concept pairs with equal path distance are the same. But in some cases, the concept pairs are not similar at all under human judgment, which is the limitation of path-only based methods.
Wu [17] improved Rada’s work by introducing the depth of concepts and the Least Common Ancestor (LCA) of concepts. Based on the depth of LCA and the relative location of
Through path distance, Li [4] exploited two more structure factors of concepts to calculate semantic similarity, which are local density and the depth of LCA. The authors used these factors through a variety of combinations to form multiple formulas. After tuning parameters on the training dataset, they seek out a nonlinear formula containing path distance and the depth of LCA. The result of the training set is similar to human judgment. Moreover, Hao [32] proposed a new model to combine path distance and depth of LCA through imitating the thought process of humans.
Although the path-based measures have developed two more factors, depth and density, their defect is the neglect of most of the structure of WordNet. So they may produce unreliable results.
Information content-based
The initial IC-based measure is proposed by Resnik [20] in which the IC of LCA represents the information shared by two concepts. However, there are two flaws in Resink’s method. One is all the pairs of concepts hold the same similarity while they have the same LCA. The other is the similarity between a concept and itself is not equal to one.
Jiang [21] improved Resnik’s method by combining path distance and IC. He assumed that IC can be employed to qualify the path distance linking every two concepts. The IC of the LCA is subtracted from the sum of the IC of the individual compared concept. Therefore, their method presents the dissimilarity rather than the similarity.
Lin [22] has also improved Resnik’s approach by using the ratio of the commonalities between concepts
Resnik [20] was the first to propose the IC computation method who assumed IC values of concepts were mainly affected by their frequency of appearance in the corpus. In line with Resnik’s model, the IC a concept contains increases with the growth of its appearance in the corpus, which indicates that the more abstract a concept is the less IC a concept contains.
Nevertheless, corpora-based IC computation depends on corpora availability and the size of the corpus. The IC of each concept tends to be the same constant when the size of a corpus is large enough, and it requires manual judgment for word sense disambiguation.
Seco [34] put forward an IC intrinsic method that utilized the intrinsic of ontologies to measure IC of concepts. In their approach, the number of hyponyms in WordNet is used as the occurrences of the given concept. Meng [7] introduced the depth of concepts into the IC-based similarity measure and proposed an IC computation formula combined with the hyponyms of concept. Experiments showed that the correlation value between similarities measured by the proposed IC computation formula and human judgments was improved.
It can be concluded from Section 2.1.2 that the differences among IC-based measures are the ways of IC computation and the combinations of IC concepts. The IC-based measures are highly dependent on the IC computation because the results and computing time in IC-based measures may be quite different when different IC computation ways are used. Another defect of the corpora-based IC computation is that it needs an additional large text corpus to compute word frequency. Besides, IC-based measures ignore part or all of the structure of the taxonomy, so it normally generates a coarse result for comparison of concepts [33].
Hybrid “is-a” relation measures
Based on the “is-a” relation, hybrid measures combine the structural characteristics in WordNet, such as path length, depth, and local density, and some of the approaches presented above.
Zhou [16] proposed a measure that takes IC measures and path-based measures as parameters. They used a tuning factor to control the contribution of each point (in their experiment
Feature-based
Feature-based approaches make use of the properties of the ontology to obtain similarity between concepts. A concept can be described by a set of words indicating its properties or features, such as their “glosses” and related terms. When two concepts have more common characteristics and less non-common characteristics, they are more similar.
Tversky [25] holds that the similarity between concepts is asymmetric. Features between a subclass and its superclass have a larger contribution to the similarity evaluation than those in the inverse direction. In Rodríguez and Egenhofer [26]’s approach, the similarity is computed based on synsets, neighbor concepts (those linked via semantic relations) and features which linearly combined by weighting parameters.
Feature-based measures rely on a complete attribute or WordNet gloss set. However, most of them ignore the role of “is-a” relation, which may cause inaccurate similarity results.
Multiple relation-based measures
Different from all the methods above, multiple semantic relation-based measures tend to search similarity factors from non-taxonomic relationships, such as meronymy, holonymy in WordNet.
Graph-based measures
Graph-based measures aimed to use the graph structure to organize multiple relations. One of the recent approaches is a new method for building WordNet graphs using multiple relations, such as synonymy, hypernym and hyponym (“is-a” link), holonym and meronym (“part-of” link). Stanchev [11] considered concepts’ definition and examples in WordNet as evidence of the relationships between concepts. Nodes in the WordNet graph are connected with asymmetric directed edges whose weight is affected by their link types. For instance, the weight of the hyponym-type edge is equal to the ratio that 0.9 multiplied by the number of all the hyponym senses of the initial sense. Hypernym-type edges’ weights will be the same and equal to the value 0.3. The weight of a meronym-type edge is set to 0.6/n, where
Multiple relation path-based methods
Hirst and St-Onge [36] determine the relatedness using the path distance between concepts via semantic relations such as hypernymy, hyponymy, and antonymy. Sussna [37] used the sum of weighting shortest path length in WordNet to calculate the relatedness of two concepts, where the edges come from different semantic relations including hypernymy, hyponymy, holonymy, meronymy, and antonymy.
Multiple relation-based measure is one of the future ways to compute semantic similarity. Because it conforms to the fact that the process of computation should simulate the thinking process of humans, and the computation should consider a variety of relations between concepts. However, few multiple relation-based measures introduce the effect of antonymy or just simply apply the direct antonymy of concepts. The amount of direct antonymy of concepts is much less than that of “is-a” relation, which will lead to less inaccurate results. In this paper we aim to explore the potential use of antonymy during the similarity computation. An approach to mine the potential antonymy is proposed and then applied in existing similarity measures to improve their computation accuracy.
Proposed model
In most cases, people may consider what have in common for concepts while using the inherent structure of WordNet to compute the similarity between them, such as the concepts’ domain, category, and species. However, dissimilarity among them was ignored. In this paper, we proposed an antisense similarity model to measure the similarity of concepts that can explore the effectiveness of antonym relation under the surface. Based on the existing path-distance based similarity approaches [4, 17, 32, 38, 39], we introduced a new calculation factor called the Antisense Coefficient (AC) in similarity computation by taking account of the antonymy between concepts. Different from other multiple semantic relation-based measures [36, 37] that simply apply the direct antonyms of concepts, our method proposed a model named Node to Least Common Ancestor Antisense Path (NLAP) by taking consideration of the negative effect of the antonyms of the concepts’ ancestor and the positive effect of concepts’ ancestors while computing the concepts’ similarity value in WordNet. To quantify the introduced factor AC of the compared concepts, the model computes the similarity between concepts and the nodes on their NLAPs. Based on AC, we can get a more accurate result which is closer to human judgment.
An antonymy-based similarity model
Considering that WordNet only provides antonyms of concepts’ lemmas in Natural Language Toolkit (NLTK) which may cause concepts’ antonyms only be tracked by antisense lemmas’ concepts, we propose the following expression:
where lemma refers to the lemmas of concept
Antonyms are the basis of our model, and the proposed factor AC is derived from antonymy between the compared concepts and is represented by the similarity between the concepts and their antonyms. AC plays a corrective role in the process of similarity measuring when it is used to represent the dissimilarity between concepts, which means AC can correct some excessive similar situations by using dissimilarity. In this study, AC is linearly combined with the results of existing path-distance based methods to express the similarity between concepts.
According to the different ways of introducing AC, four strategies are proposed to calculate the similarity between concepts.
where
where
whereas, the numbers of concepts that appear antonymy in datasets like RG65, MC30 are only two and the antonyms are the same. The two concepts are “boy” and “brother”. The fact that there are few antonyms of concepts in WordNet means AC in strategy 1 doesn’t work if there are no antonyms for the compared concepts.
The detail of word pairs in datasets RG65 and MC30 with antonymy is shown in Table 1, column AC(Wu) represents the AC computed by Wu’s method, column simWu shows the similarity results of Wu’s method, column antisimWu refers to the results of the model combined strategy 1 with Wu’s method, and columns MC30 and RG65 represent the similarity results of human judgment between the compared concepts. It can be observed from Table 1 that the similarity between “brother” and “lad” is 0.78 (the range is from 0 to 1) in Wu’s method, which is higher than the human judgment values 1.66 (the range is from 0 to 4) in MC30 and 2.41 (the range is from 0 to 4) in RG65. After improved by strategy 1, the similarity decreased from 0.78 to 0.71 (the range is from 0 to 1), which is closer to human judgment.
The direct antonyms in MC30 and RG65
The key idea of Resnik’s method [20] is that one criterion of similarity between two concepts is “the extent to which they share information in common”, which can be determined by inspecting the relative position of the most-specific concept that subsumes them both in an IS-A taxonomy. Based on Resnik’s method, Least Common Ancestor (LCA) is used to represent the most-specific subsumer and to explore hidden antonymy between concepts. An example of LCA is, in Fig. 1 the LCA of school boy#1#1 and monk#1#2 is person#1#3.
The concepts are related to their ancestors in the lexical hierarchy of WordNet cause they inherit part of the characters from their ancestors via “is-a” relation. As a member of ancestors, LCA is used to set the range of ancestors. That means ancestors of the compared concepts whose hierarchy is deeper than LCA can be seen as the extension of the compared concepts and used to find antonymy of the compared concepts. Based on their affiliation, the chosen ancestors can be grouped as
As NLAP is used to compute AC and linearly combined with the similarity results of existing path-distance based methods, the similarity measure with NLAP is formalized as follows:
Where
where
Comparison of using different methods to compute AC in strategy 2
“is-a” relation taxonomy fragment in WordNet.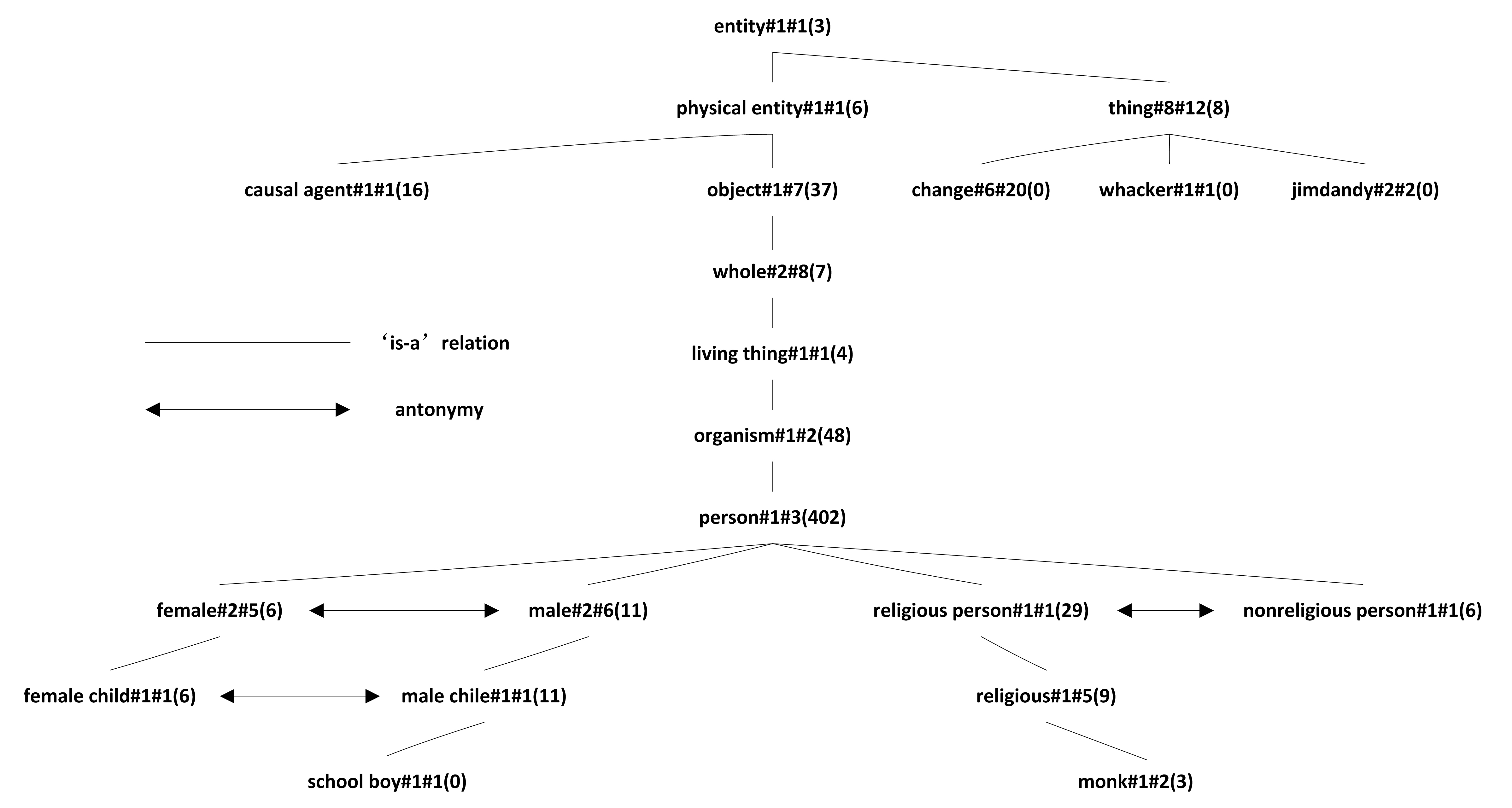
Experiment results showed that AC computed by more precise existing models behaved better on correlation values. For instance, in Table 2
where
where Number represents the computation times of similarity measuring between nodes in the process of calculating NLAPSim,
As NLAPSim is introduced in the process of computing AC, the effect of ancestors’ antonyms can be considered in similarity computation. Thus, AC in strategy 4 is calculated by combined NLAPSim with NLAP and then strategy 2 is improved as:
where
Datasets
In this study, words from widely used datasets in the existing researches have been chosen to conduct the experiments and the results have been compared against human ratings performed in the same settings. At present, many related approaches [4, 16, 17, 22, 32, 38, 39] have used Miller and Charles (MC30) [40] and Rubenstein and Goodenough (RG65) [41] benchmarks as their test datasets. RG65 includes 65 pairs of words whose rating is on a scale from 0 to 4 for semantically unrelated to highly synonymous given by 51 human subjects in 1965. Another dataset MC30 contains 30 word pairs derived from dataset RG65MC30 has an obvious hierarchy on similarity (10 highlevel word pairs, 10 intermediatelevel word pairs, and 10 lowlevel word pairs) with the scores from 0 to 4 for no similarity to perfect. MC30 dataset derives from a duplicate of the original experiment with re-rating carried out 25 years later than RG65.
The process of using strategy 4 to compute similarity.
In this paper, the noun taxonomy of WordNet 3.0 was used as the taxonomic ontology for the MC30 and RG65 datasets. Natural Language Toolkit (NLTK) interface is used for WordNet to acquire data in WordNet 3.0. The maximum depth and maximum nodes of the WordNet structure are equal to 20 and 82115, respectively.
Results compared with existing path-based methods
Results compared with existing path-based methods
Results compared with various existing methods
The detailed experimental and measuring process is as follows:
Each word in the word pairs on MC30 and RG65 datasets is regarded as an index word to query WordNet 3.0 and one or more meanings (concepts or synsets) for them can be obtained. Because an index word may get more than one meanings, the following formula is used to calculate the similarity of words:
where While using AC to calculate the similarity between words a word may have more than one antonym due to its many senses. In this case, the sense and antonym which can gain the maximum similarity are used in the experiment. Pearson correlation coefficient is used to compare the results of the experiment and judgments provided by humans in datasets. Pearson’s
where
A series of comparisons were made with various methods to validate the effectiveness of the proposed model.
First, we compared the existing approaches using path length, depth, and density factors with the same approaches combined with our AC model on the measurement of the same datasets. This comparison would reveal the ability of our model to enhance the measurement accuracy of the “is-a” based similarity approaches. Then comparisons between the results of strategy 3 and strategy 4 with the popular similarity algorithms, including IC-based approaches, feature-based approaches, and the hybrid approaches, were made to evaluate whether the edge-based similarity approaches combined with our path model reach a level of excellence.
Table 3 shows the correlations of different similarity methods on the MC30 and RG65 datasets. Firstly, we reproduced some classic approaches [4, 17, 32, 38, 39], such as path distance, depth, and density, and a different path-weighting approach [14]. Then we combined the approaches above with strategy 3 and strategy 4. Table 4 provides a comparison of strategy 4 and strategy 3 with other current mainstream similarity algorithms on the MC30 and RG65 datasets.
Analysis of the parameters in the metrics
Since the parameter settings of
Considering that AC plays a corrective role in our model and have a significant influence on the result, we can conclude that the main function of parameters in the formulas is to weight the corrective function of AC. The following shows the detailed analysis of parameters in the formulas according to Eqs (8) and (10).
To better understand the influence of parameter
Comparison of five existing path-distance based methods improved by strategy 4.
We can learn from Eq. (8) that there are two times of similarity measuring on compared concepts while using strategy 3 to compute the similarity between concepts, and each time of measuring has a parameter,
Results of combined Li’s method with strategy 3.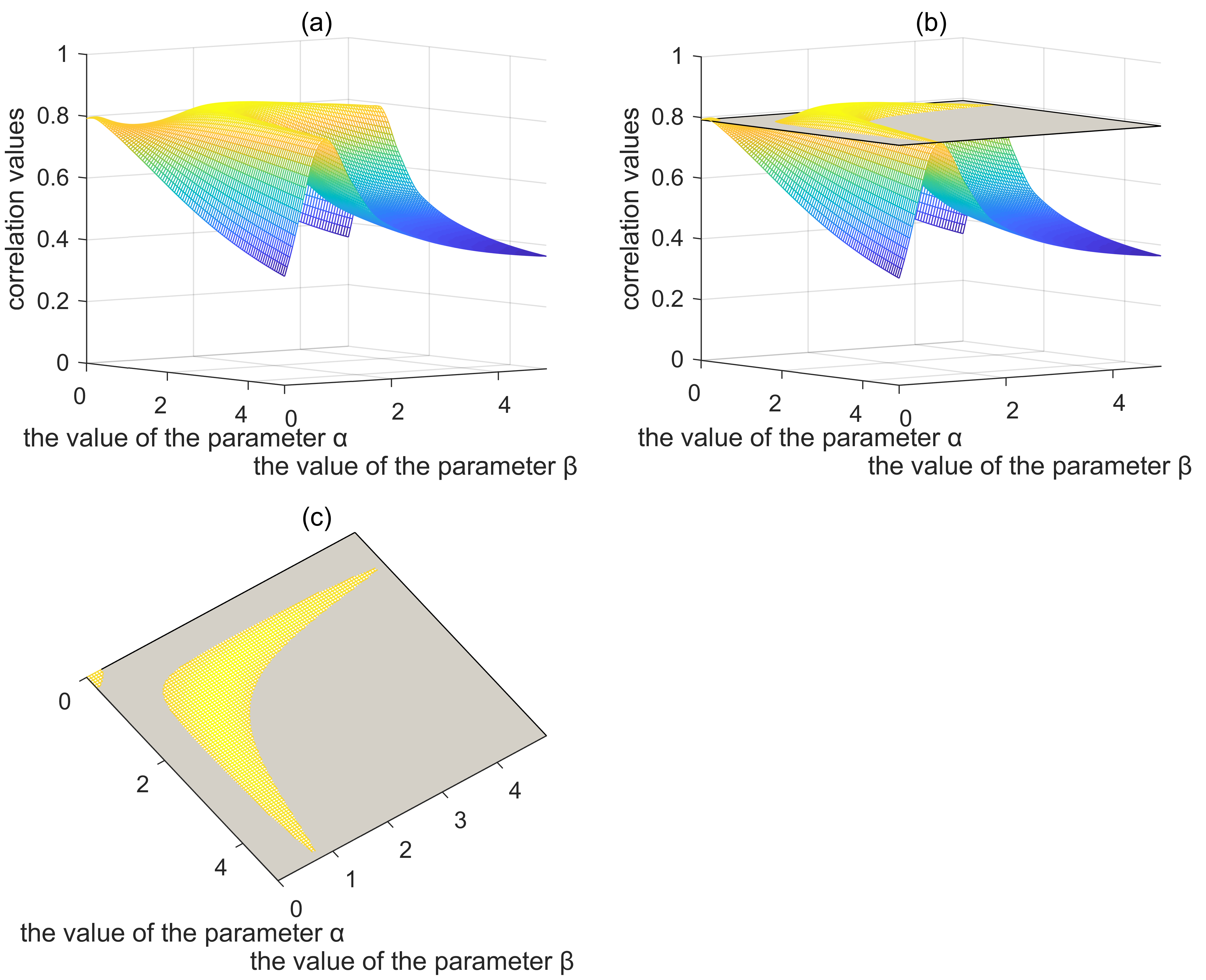
After comparing the results with human judgment in MC30, we get the correlation values. The correlation value is the original correlation value of Li’s method [4] when
We can learn from Fig. 4c that when the value of
From the above analysis, it can be observed that the proposed method can improve other path-based methods and achieve higher correlation values with standard benchmarks (e.g. strategy 4 obtains the highest correlation of 0.887 with MC30 dataset and 0.857 with RG65 dataset. For strategy 3, the corresponding values are 0.883 and 0.864, respectively). With all these characteristics, the proposed method is suitable for engineering applications, especially the field of knowledge reuse and information management.
To further observe the performance of our proposed model on text processing tasks, we conducted comparative tests on the Microsoft Research Paraphrase Corpus (MSRP) [42] for sentence similarity in which 1725 test pairs were used to perform the paraphrase recognition task. For each sentence pair, human subjects have judged whether any of the two sentences in the pair contains a paraphrase of the other. The sentence pair will be marked as 1 if it contains any paraphrase of the other, and marked as 0 in case of no containment. We utilize Rada [43]’s method to calculate the semantic similarity between sentences.
where
The threshold is set to 0.5 according to Rada [43]. When the similarity between two sentences is higher or equal to 0.5, any of the two sentences contains a paraphrase of the other. By combining different WordNet-based word similarity methods [4, 17, 39], we obtained the comparison results as shown in Table 5.
Performance of various combined word similarity methods on the Microsoft Research Paraphrase Corpus (MSRP)
Take the 1248th item in MSRP for example, the compared sentences are:
sentence1: ‘His lawyer, Pamela MacKey, said Bryant expects to be completely exonerated.’ sentence2: “‘ Mr. Bryant is innocent and expects to be completely exonerated,” Mackey said in a statement.’.
These sentences are marked as 0 in MSRP. However, two noun synset sets are obtained after picking up the nouns as the guide word to query synsets from WordNet and the results are shown as follows:
{‘lawyer’: Synset(‘lawyer.n.01’), Synset(‘beryllium.n.01’)} {‘Mr.’:Synset(‘mister.n.01’), ‘innocent’:Synset(‘innocent.n.01’), ‘be’:Synset(‘beryllium.n.01’), ‘in’: Synset(‘inch.n.01’), Synset(‘indium.n.01’), Synset(‘indiana.n.01’), ‘a’: Synset(‘angstrom.n.01’), Synset(‘vitamin_a.n.01’), Synset(‘deoxyadenosine_monophosphate.n.01’), Synset(‘adenine.n.01’), Synset(‘ampere.n.02’), Synset(‘a.n.06’), Synset(‘a.n.07’), ‘statement’: Synset(‘statement.n.01’), Synset(‘argument.n.01’), Synset(‘statement.n.03’), Synset(‘statement.n.04’), Synset(‘affirmation.n.02’), Synset(‘instruction.n.04’), Synset(‘statement.n.07’)}
Based on these word pairs, the following is the process of sentence similarity computation when using Eq. (13) and Li’s method [4].
A similar computation is conducted to these word pairs when using Eq. (13) and our strategy 4 (
The results show that the similarity between the sentences decreased from 0.51 to 0.42 when using strategy 4 to improve Li’s word similarity method, which is lower than the threshold 0.5 and closer to the human judgment value 0.
The same situation happened on the 1295th item in MSRP, the compared sentences are:
sentence1: ‘Chante Jawan Mallard, 27, went on trial Monday, charged with first-degree murder.’ sentence2: ‘Chante Jawaon Mallard, 27, is charged with murder and tampering with evidence.’.
These sentences are also marked as 0 in MSRP. The results after disposing of are shown as follows:
{‘Jawan’: Synset(‘jawan.n.01’), ‘Mallard’: Synset(‘mallard.n.01’), ‘trial’: Synset(‘test.n.05’), Synset(‘trial.n.02’), Synset(‘test.n.04’), Synset(‘trial.n.04’), Synset(‘trial.n.05’), Synset(‘trial.n.06’), ‘Monday’: Synset(‘monday.n.01’), ‘first’: Synset(‘first.n.01’), Synset(‘first.n.02’), Synset(‘beginning.n.02’), Synset(‘first_base.n.02’), Synset(‘first.n.05’), Synset(‘first_gear.n.01’), ‘degree’: Synset(‘degree.n.01’), Synset(‘degree.n.02’), Synset(‘academic_degree.n.01’), Synset(‘degree.n.04’), Synset(‘degree.n.05’), Synset(‘degree.n.06’), Synset(‘degree.n.07’), ‘murder’: Synset(‘murder.n.01’)} {‘Mallard’: Synset(‘mallard.n.01’), ‘murder’: Synset(‘murder.n.01’), ‘tampering’: Synset(‘meddling.n.01’), ‘evidence’: Synset(‘evidence.n.01’), Synset(‘evidence.n.02’), Synset(‘evidence.n.03’)}
The process of sentence similarity computation when using Eq. (13) and Li ’s method [4] is shown as:
The similar computation using Eq. (13) and our strategy 4 is shown as:
Despite the examples demonstrate that our strategy 4 behaves better, experiment results in Table 5 showed that the accuracy, recall rate, and F1-measure of exist path-based methods have little improvement when switching to strategy 4. That means few items in MSRP changed their mark in that situation. The reason is that the preprocessing of sentences is imperfect. Situations that words like ‘a’ and someone’s names have some noun senses doesn’t help but make some redundant senses when computing word similarities and finding possible antonyms. Especially we only pick up nouns in sentences during the process of computing the similarity between sentences. In the future work, we should divide the sentences by part of speech properly, and combined the word similarity with string similarity to compute the similarity between each part of sentences. After dividing, we can give different weight to the word similarity and the string similarity according to the words’ part of speech. For example, when computing the part of sentences which include names, the weight of string similarity will be much higher than that of word similarity.
SemEval (Semantic Evaluation) is an ongoing series of evaluations of computational semantic analysis systems, organized under the umbrella of SIGLEX, the Special Interest Group on the Lexicon of the Association for Computational Linguistics. SemEval-2014 was the 8th workshop on semantic evaluation. The Cross-Level Semantic Similarity is one of the SemEval-2014’s tasks, and it contains the task that computing semantic similarity between paragraph and sentence or so-called ‘short text’. After using Eq. (13) to compute the similarity between sentences, the following formula is used to combine sentence similarity to obtain the short text similarity.
where
Experiment results show that our proposed model also works in some short text similarity cases in SemEval-2014. Take the 343rd item in the training set as an example, the compared texts are:
Text1: ‘At what are obviously busy times on the net. I use Firefox via Orange. Anybody else had a problem please?’ Text2: ‘My internet is slowing to a crawl.’
The disposed of results of texts on the basis of sentences are shown in Table 6.
Synsets of concepts in Text1 and Text2
Antonyms in the NLAP of compared concepts
Part of the set that contains the antonyms appear in the NLAP of two compared concepts in the computational process when using our model is listed in Table 7.
The similarity between two short texts is marked as 0.75 (the range is from 0 to 4) under human judgment. The computational process of short text when using Li [4]’s method is:
The similarity between texts decreased to 0.42 (the range is from 0 to 1) when using our strategy 4, which is closer to human judgment. Its detail is shown as:
Another example is the 347th item in the training set, its compared texts are:
Text3: ‘What do you all the think the impact on the British internet providers has been since the release of online media streaming, not so much youtube but more BBCi player, they allow streamed content of HD and it is hugely popular …surely this has put a lot of strain on the providers servers. Have they had to spend a fortune to upgrade?’ Text4: ‘HD video accounts for over 50% of the bandwidth consumed in Britain on an average weeknight.’
The words in the above texts that have antonyms are shown in Table 7.
The similarity between the above two short texts is marked as 0 (the range is from 0 to 4) under human judgment. However, the similarity result is 0.31 (the range is from 0 to 1) when using Li’s method [4] and Eq. (13), its detail is shown as:
The similarity between texts decreased to 0.3 (the range is from 0 to 1) when using our strategy 4 and Eq. (13). Its detail is shown as:
Sentence similarity can also be applied to the field of text classification by computing the similarity between texts since texts that have the same topic can get higher similarity score. Quora [44] is an American question-and-answer website where questions are asked, answered, followed, and edited by Internet users, either factually or in the form of opinions. Each question has at least one topic, and the answers to a question should have the same topics. To validate the effectiveness of the proposed model on text classification, we choose two questions which have different topics and cut out some short texts from answers of the questions. Then we use Eqs (10) and (13) to compute the similarities between these short texts. Our model will play a role if there are differences between the similarities of short texts with the same and different topics.
The similarity of short texts has been shown in Table 9. The ‘A’, ‘B’, ‘C’, ‘D’, ‘E’ represent part of the answers of the question ‘What do you think about the cryptocurrency Ripple?’, and the ‘F’, ‘G’, ‘H’, ‘I’ are the short texts cut out from the answers of the question ‘What do you think about cooking?’. The details of the short texts have been given in Table 8.
The short texts from answers in Quora
The short texts from answers in Quora
The similarities between answers
We can know from Table 9 that there are boundaries between different short texts with different topics. Values in the upper left corner and the lower right corner are the similarities of the short texts with the same topic. We can see that most of the similarity values of the same-topic short text are around 1 and fewer are lower than 0.7. Values in the upper right corner are the similarities of the short texts with different topics in which fewer of the different-topics similarities are higher than 0.7. In this case, the value of 0.7 is the difference that can label the short texts. Therefore, 0.7 can be treated as the threshold value which can be used to determine whether the short texts with the same topic or not. The experiment results showed that the feasibility of our proposed model when it is applied in text classification.
The correlation values between different methods and human ratings are listed in Table 4. It can be observed that methods [4, 39] considering more related factors achieve higher correlation values than the single-factor measure [38]. The correlation values of some methods [32, 35] show that the combination of the factors plays an important role in the process of calculating the similarity of concepts. The experimental results confirm the following statements:
Considering more factors in the process of similarity measuring (like human processing) can improve the performance of the measurement. An appropriate combination of the factors increases the correlation value.
From the above observations, we believe that effective methods combining more related factors contribute to the performance of similarity measures.
Directly employing a single factor to compute the similarity between concepts gives a low correlation with human ratings. Therefore, other factors can be introduced to make an impact on the process of computing similarity. For instance, the dissimilarity between concepts can be considered while computing the similarity which is computed as AC in the proposed model. Different from other algorithms [36, 37] which simply consider the direct antonymy, we explored the effect of antonyms from concepts’ ancestor, and further considered the effect of antonyms in the NLAP structure.
The experimental results show that when (0
From Table 3, a conclusion can be drawn that our model can significantly improve the correlation value of various edge-counting similarity approaches on the WordNet, including path-based only algorithms [3], path-and-depth-based algorithms [4, 17], and combined path length, depth, density to re-weight the path length algorithm [16]. After combining with strategy 4, the edge-counting similarity approaches mentioned above universally promoted their correlation values on MC30 about 5 percent and about 0.5 percent on RG65. The extent of promotion decreases with the increase of the correlation values in the original methods. The best correlations reach 0.89 and 0.86 on MC30 and RG65 for WordNet, respectively.
While combining with strategy 3, the edge-counting similarity approaches promoted their correlation values on MC30 about 7 percent, and about 1.5 percent on RG65. The extent of promotion decreases with the increase of the correlation values of the original methods. The best correlations reach 0.89 and 0.865 on MC30 and RG65 for WordNet, respectively. Our correlations are widely recognized and repeatable for computer-based similarity measures on the MC30 dataset and are quite similar to the average correlation (0.9015) between individual human subjects reported in Resnik’s replication [20] of the Miller and Charles experiment.
The details of similarity measuring in strategy 4 on MC30
It can be observed in Table 10 that only 8 pairs of concepts’ similarities have changed in MC30 while using strategy 4 to improve Li’s method [4], which means the AC of 8 concept pairs are nonzero. This demonstrates that every two concepts may not appear antonyms. Meanwhile it explains the reason our improvement is not good enough in some cases. The result in Table 10 also indicates that the rectification of antonymy’s corrective effect is effective. Take concept pair “lad” and “wizard” as an example, the human judgment of similarity between “lad” and “wizard” is 0.42 (the range is from 0 to 4). However, in Li’s method [4] the similarity between them is 0.4491(the range is from 0 to 1), which is much higher than human judgment. After improved by strategy 4, the similarity between “lad” and “wizard” computed by Li’s method decreased to 0.1858 (the range is from 0 to 1), which is closer to human judgment. Similar to “lad” and “wizard” case, the similarity between “coast” and “hill” decreased from Li’s original similarity value 0.442 (the range is from 0 to 1) to 0.1827 (the range is from 0 to 1), which is closer to the human judgment 0.87 (the range is from 0 to 4). However, there are some overcorrection situations in the model combined strategy 4 with Li’s method For example, the similarity between “boy” and “lad” is more than 1. This is due to our formula’s limitation, the NLAPSim between “boy” and “lad” is bigger than expected, and that is greater than the corrective function of AC in Eq. (10) which leads to excessive positive correction. There are also excessive negative correction cases because of the oversized AC between concepts. For instance, the similarity between “car” and “journey is
The details of similarity measuring in strategy 3 on MC30
There are two sets of similarity results of strategy 3 in Table 11. That is because strategy 3 is the iteration of strategy 2, so there may be two similarity computations of compared concepts in strategy 3 and may produce two AC s. When some concepts’ similarities are corrected and reach the expectation in the first measuring, some concepts’ similarities appear in overcorrection situations like strategy 4. So here comes the second measuring which means another correction to the overcorrection concepts, such as concept pair “furnace” and “stove” in Table 11.
Computer configuration used in the experiment
However, since our strategies are proposed to improve the results of other exiting similarity methods [4, 17, 32, 38, 39], our proposed models take longer than the normal algorithms while calculating the similarity
Details of similarity measuring in strategy 3 on MC30
between concepts. To compare the computing time of each model, we recorded some models’ computing time on MC30 and their computation factors in Table 13. The computer configuration used in our experiment is shown in Table 12. We can know from Table 13 that the computing time of IC-based methods is much longer than other methods and is mainly affected by their choice of IC computation. While using different IC computation, the same IC-based method has much different computing time. For example, the computing time of Meng’s method [7] on MC30 is 27.8491 s when using Meng’s IC computation [7] to compute IC, which is much longer than 5.7281s of using Seco’s IC computation [34]. That’s because the formulas of IC computation also have different similarity factors. We can know from the difference between Meng’s IC computation and Seco’s IC computation that Meng’s method is more complex and needs more similarity factors like descendants of concepts and depth. This situation proves that the computing time is influenced by a method’s similarity factors.
In a method, all of its similarity factors are based on a concept’s factors in WordNet such as depth and LCA. Thus, the computing time is also influenced by concepts, especially the number of concepts. The number of similarity factors will increase when we need to query more concepts from WordNet. Moreover, query different relations in WordNet between concepts take different time. Hypernymy, hyponymy, holonymy, meronymy take the same time because they are directly connecting concepts. However, we cannot directly query a concept’s antonym by using NLTK. We can only get the antonyms of a concept’s lemmas and track which concept these antonyms belong to get antonyms of concepts. So, query antonymy takes longer than other relations in NLTK. While considering more relations in the process of similarity measuring, it takes more time because we need to deal with these relations separately. Hence the number of semantic relations also affects computing time.
Above all, we can conclude that the computing time of similarity measuring will increase with the increase of the number of similarity factors, the quantity of considered semantic relations, number of considered concepts, and the complexity of its formula. In addition, query concepts’ antonymy by NLTK takes longer than other relations.
We can know in Table 13 that our average computing times of strategy 3 and strategy 4 on dataset MC30 are 2.1484 s and 1.9745 s, respectively. Because of our strategies are attached to other existing methods [4, 17, 32, 38, 39], we got five computing times for each strategy and the computing time in Table 13 is the mean value of them. For example, the computing time of strategy 3 is 2.1484 s which is the mean value of 2.4129 s (combined strategy 3 with Wu’s method [17]), 1.9924 s (combined strategy 3 with Leacock’s method [38]), 2.1012 s (combined strategy 3 with Li’s method [4]), 2.1041 s (combined strategy 3 with Liu’s method [39]), 2.1317 s (combined strategy 3 with Hao’s method [32]). Our strategies’ computing time is close to Zhu’s model [14] and is longer than the computing time of the methods we improved. That is because both Zhu’s approach [14] and our approaches can be seen as the attachment of other processes on the existing path-based approaches. Compared with the methods we improved, our strategies consider more similarity factors (AC), more semantic relations, and a bigger number of considered concepts. Therefore, the fact that our methods take more computing time is consistent with the above conclusions. Furthermore, strategy 3 normally takes more time than strategy 4. That is because strategy 3 is the iteration of strategy 2 while strategy 4 just adds a similarity factor called NLAPSim to strategy 2, which means that the complexity of strategy 3 is higher than strategy 4 and needs an extra computation on compared concepts.
In this paper, we proposed a new approach to compute the similarity between concepts based on the antonymy of WordNet. The approach is suitable for improving other path-distance based methods to calculate semantic similarity between concepts. Compared with the existing “is-a” relation-based methods, our proposed model introduced one more structure in WordNet into the process of similarity computation to make the similarity results more precise. Compared with the existing multiple relation based measures, our proposed model makes full use of the potential antonymy and introduced it into the process of similarity computation. In the introduction, we put forward the research problems of our paper. We conclude the paper by answering each of them.
RQ1 What kind of structure can make full use of the antonymy?
Considering the low appearance of antonymy and the positive effect of the least common ancestor, we proposed a model named Node to Least Common Ancestor Antisense Path (NLAP).
The ancestors of concepts can be seen as the extension of concepts because concepts inherit some attributes from their ancestors. The farther a node is away from its ancestor, the fewer attributes it can inherit from that ancestor. To some extent, the antonyms of a concept’s ancestor can be seen as the antonyms of the concept. Those antonyms are called the NLAP of the concept, and the dissimilarity between concepts equals to the similarity between a concept and the nodes on the NLAP of another compared concept. In addition, those antonyms of ancestors’ contribution to the dissimilarity computation are determined by the different path distance between the concept and its ancestors.
RQ2 How effective is antonymy during similarity computation?
We introduced the antonymy into the similarity computation in the proposed model. Experiment results showed that our model obtains the highest correlation of 0.887 on word dataset MC30 and of 0.864 on word dataset RG65. The proposed model can correct the over-similar situations of existing path distance-based models by introducing the NLAP of concepts.
Furthermore, in order to validate the correctness on similarity measurement, the proposed model is applied to different granularity level of text including word, sentence and short text. The results showed that the proposed model did work on the above circumstances as well.
Antisense Coefficient (AC), a new calculation factor introduced in this paper, represents the impact of antisense during similarity computation which plays an important role in the proposed model. Depending on the usage of NLAP, our model is derived into two strategies. Strategy 4 uses the antisense similarity got from NLAP structure and the NLAPSim to compute AC Unlike strategy 4, strategy 3 only regards the antisense similarity got from NLAP structure as AC. However, there are two times of similarity computation on the compared concepts in strategy 3.
ACs in both strategies have an excessive corrective effect on the process of similarity measuring. In future work, we will find a more efficient combination of AC with other similarity results or other factors. The lexical structure of WordNet is too complex that LCA may not be the best structure to represent hidden antonymy, so a more efficient and more effective structure can be another interesting direction in future works. Besides, we will explore other relations in the impact of WordNet on semantic similarity and evaluate the graph and the weighting path to place each relation, such as meronymy and holonymy. In addition, we will find a sentence similarity computation method that can combine the concept similarity and the string similarity properly by the part of speech of words.
Footnotes
Acknowledgments
This work was supported by Natural Science Foundation of Liaoning Province (201602583).
Author’s Bios