
Abstract
Learning based credit prediction has attracted great interest from academia and industry. Different institutions hold a certain amount of credit data with limited users to build model. An institution has the requirement to obtain data from other institutions for improving model performance. However, due to the privacy protection and subject to legal restrictions, they encounter difficulties in data exchange. This affects the performance of credit prediction. In order to solve the above problem, this paper proposes a federated learning based semi-supervised credit prediction approach enhanced by multi-layer label mean, which can aggregate parameters of each institution via joint training while protecting the data privacy of each institution. Moreover, in actual production and life, there are usually more unlabeled credit data than labeled ones, and the distribution of their feature space presents multiple data-dense divisions. To deal with these, local meanNet model is proposed with a multi-layer label mean based semi-supervised deep learning network. In addition, this paper introduces a cost-sensitive loss function in the supervised part of the local mean model. Conducted on two public credit datasets, experimental results show that our proposed federated learning based approach has achieved promising credit prediction performance in terms of Accuracy and F1 measures. At the same time, the framework design mode that splits data aggregation and keys uniformly can improve the security of data privacy and enhance the flexibility of model training.
Introduction
The credit system in industry is already an important part of national credit management where credit prediction is indispensable. Credit prediction is to evaluate the credit status of the institution or individual based on the current credit-related information, which can quickly and effectively discover its possible credit related problems. If the credit information of companies can be better used for credit prediction and modeling, it will provide a strong guarantee for the credit supervision of our society. And also credit evaluation is the content of long-term research in financial field. At present, various institutions, such as banks, government agencies, etc., hold a certain scale credit data with limited users. However, due to data privacy protection, it is difficult to get benefits from the data from other institutions. Moreover, some institutions are still using traditional manual methods for credit evaluation, which is time-consuming and labor-intensive.
In order to solve the current problems in the field of credit prediction, this paper proposes a federated learning based semi-supervised credit prediction approach enhanced by multi-layer label mean. So as to make cooperation between institutions more flexible and data exchange more secure, this paper divides the federated learning framework into three modules. (1) In the cooperation center, various institution can more easily reach cooperation and carry out the collaboration of the keys needed in the subsequent federal modeling process. (2) The main work of the federal modeling center is to aggregate and distribute the encrypted data of various agencies. Taking into account the differences in the amount of data and computing power of each institution, this paper designs an asynchronous notification scheme to make the federal modeling process more flexible. (3) The local meanNet model is a semi-supervised deep learning network for each institution to conduct local data training after utilizing the data characteristics in the field of credit prediction.
More specifically, this paper has observed that credit datasets have multiple
data-dense divisions. A public credit data is normalized to the
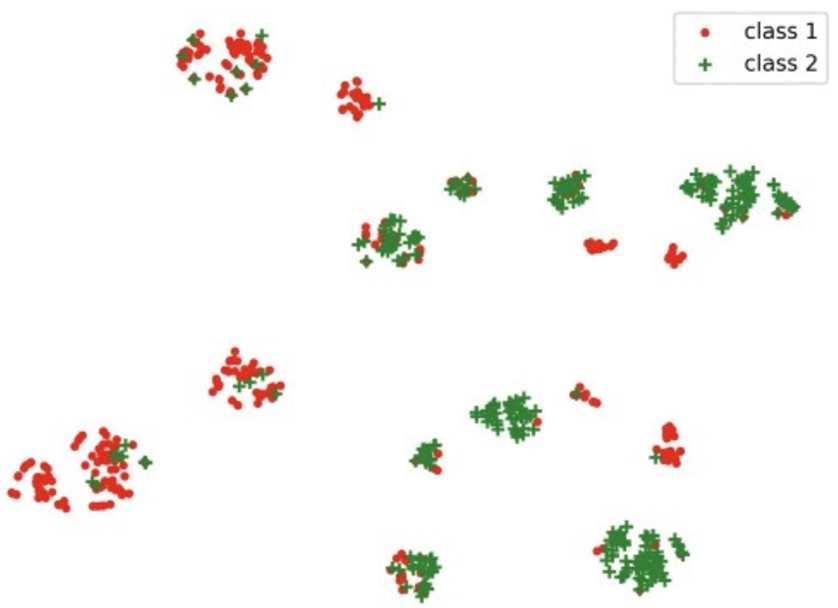
An example of credit dataset visualization. Normalize the digitized data
features to
In summary, the main contributions of this paper are as follows:
This paper proposes a federated learning based semi-supervised credit prediction approach enhanced by multi-layer label mean (FL-CPMN), which can effectively ensure the data security of various institutions, promote cooperation between multiple institutions, and improve the quality of credit prediction.
This paper introduces a deep multi-layer label mean model (meanNet) [22] embedded as a module in FL-CPMN that solves the problem of multi-sample centers and inconsistent loss of sample misclassification in the credit prediction.
An extensive experiments have been done to show the effectiveness of our proposed FL-CPMN. Results show that our proposed FL-CPMN has achieved promising credit prediction performance while improving data security.
This paper is organized as follows. Section 2 introduces the related work on semi-supervised deep learning in credit prediction and federal learning. Section 3 describes the overall framework and each module of our approach. Section 4 provides the experimental setup and analyzes the results. Section 5 concludes this paper and discusses future directions.
Credit prediction is based on the credit-related data of enterprises or individuals, usually analyzed and modeled by professional and qualified institutions, and finally predicts their credit status.
Federal learning
Federal learning can effectively interact with the data of various institutions and meet the data exchanging requirements of credit prediction. Yang et al. [25] used federated learning to train, evaluate, and deploy models for the first time in a global business environment to improve the quality of Google’s GBoard virtual keyboard search and suggestions. Bonawitz et al. [3] built a scalable production system for federated learning based on mobile devices based on TensorFlow. Xie et al. [23] proposed an innovative multi-center aggregation mechanism for the non-independent and identically distributed data problem (Non-IID, Non Independent and Identically Distributed) that is common in federated learning. It can make the best match between heterogeneous data and multiple centers, and the experimental results also verify the effectiveness of this idea. McMahan et al. [14] proposed the concept of federated average algorithm in machine learning, which can achieve excellent training effects. Yang et al. [24] proposed the concept of secure federated learning for data privacy and demonstrated a federated learning framework that includes horizontal, vertical, and migration. Kairouz et al. [9] summarized the progress in the field of federated learning in recent years, and proposed a large number of applicable domains of federated learning (such as finance, medical treatment, blockchain, etc.) and the challenges faced when applied to it. For Federal Learning, privacy protection is a very important part of it. Guo et al. [8] applied the federal deep learning framework to the medical field and solved the problem of magnetic resonance image reconstruction. However, in the field of credit prediction, there are few model building and empirical studies that take into account both of deep learning based credit prediction models and federated learning to improve the effectiveness of model training of various institutions while protecting data security.
Credit prediction
Methods based on machine learning, especially methods based on deep learning, have very excellent performance in credit prediction tasks. There is insufficient label data in the credit prediction data, while there is a large amount of unlabeled data. In order to better utilization of these data, recently some studies have worked on semi-supervised learning in the field of credit prediction. Li et al. [13] used a semi-supervised support vector machine (S3VM) [20] to solve the credit scoring problem with rejection inference. Chapelle et al. [4] summarized the research progress in the field of semi-supervised learning. Among them, the semi-supervised neural network performs well, and its performance is better than traditional machine learning methods in many fields such as image [2, 11, 16, 17, 19], medical treatment [1, 15], and review recognition [5]. Ladder Network [17] is a classic structure in semi-supervised deep learning. The ladder network integrates the unsupervised loss and the supervised loss. On the Mnist handwritten digits dataset, only a small amount of labeled data is used, and the accuracy is close to that of the supervised neural network. Pezeski et al. [16] verified the effectiveness and rationality of the ladder network through a large number of control variable comparison experiments. Based on the idea of time series, Laine et al. [11] proposed two semi-supervised neural network structures (∏-Model and Temporal Ensembling), which performed well on multiple image classification datasets. The Mean Teacher proposed by Tarvainen et al. [19] proposed a semi-supervised deep learning method with two isomorphic networks from the perspective of model weight averaging. Compared with the model proposed by Laine et al. [11], Mean Teacher needs to use fewer samples to achieve the same prediction effect, and is more suitable for large-scale data training. The MixMatch proposed by Google [2] is an effective semi-supervised deep learning method that combines the advantages of current semi-supervised deep learning methods. To the best of our knowledge, the models proposed in the above studies seldom deal with the problem that the distribution of credit data in the feature space presents multiple data-dense divisions. Our proposed approach introduces multi-layer mean label [22] to a semi-supervised deep learning network to solve this problem.
Our approach
This section will introduce the overall framework of A Federated Learning based Semi-supervised Credit Prediction Approach Enhanced by Multi-layer Label Mean (FL-CPMN), as shown in Fig. 2. FL-CPMN is based federated learning that integrates deep learning with relatively decoupled modules. It can fully protect the privacy and security of institutions, and also supports the addition and withdrawal of various institutions at any time. This can meet the needs of a variety of industries.
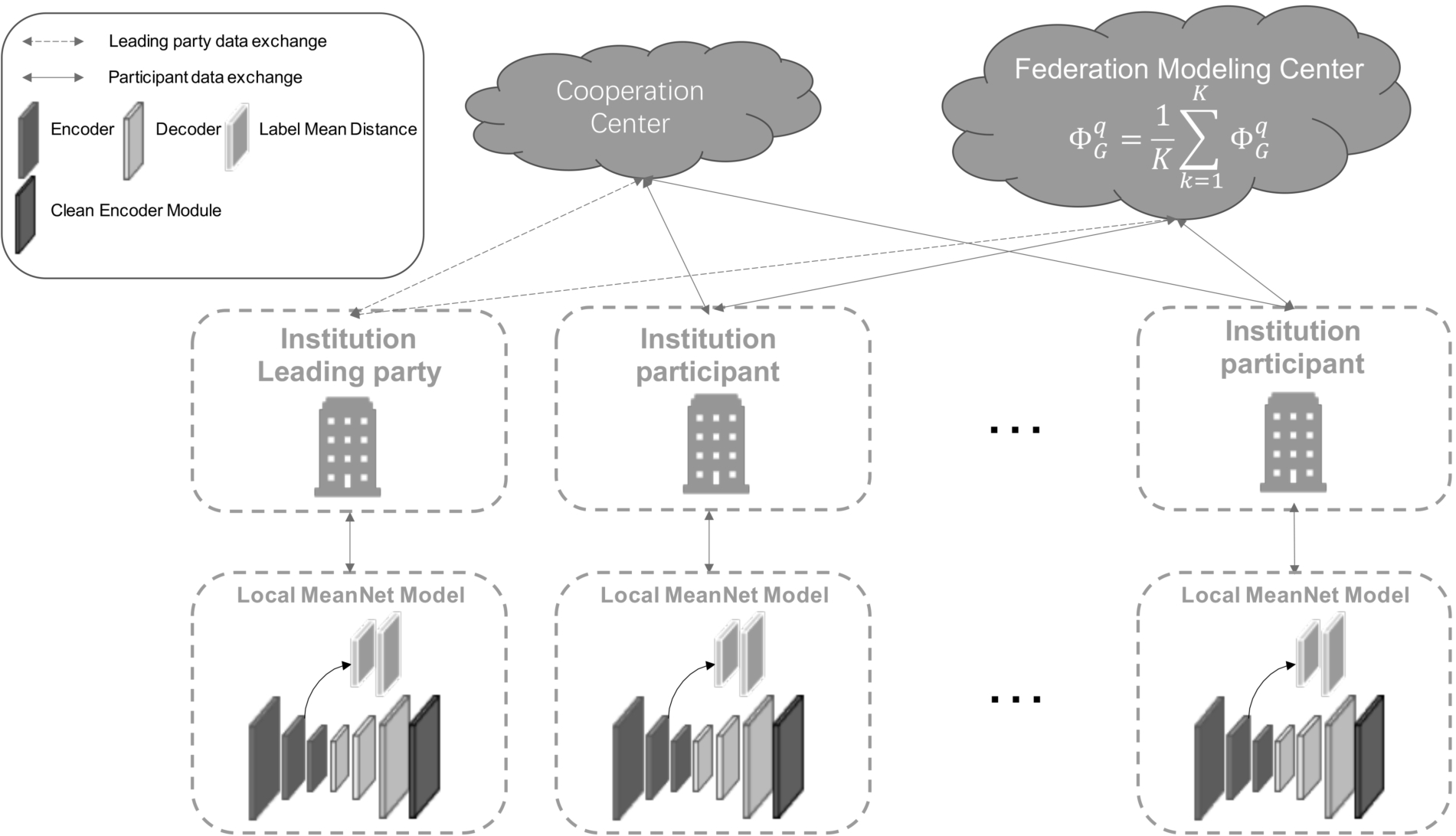
The framework overview of FL-CPMN. The figure shows the data flow between the cooperation center, the federal center and the data center. Cooperation between institutions is reached in the cooperation center. Each organization transmits its own local model training results to the federal model center for data aggregation.
There are three modules in FL-CPMN. The cooperation center in the upper left of Fig. 2 is responsible for registering identity information, communicating keys, and reaching cooperation. The federal modeling in the upper right of Fig. 2 center handles the aggregation and allocation of parameters. Local meanNet model in the bottom of Fig. 2 is the server node module of each organization, which mainly conducts credit prediction model training locally.
One advantage of federated learning is that it can protect data privacy. The main way is to ensure that the data is always local to each institution during the entire federal learning training process, and does not directly interact with other institutions or enterprises. Instead, the gradient information after each round of training can be exchanged. However, if the gradient information is not protected, the basic requirements of data privacy cannot be met, because the data information can be reversed according to the gradient information of the neural network [27]. Therefore, the encryption strategy of authentication and parameters is very important. In reality, the central server is not highly credible, so this paper establish a cooperative center to ensure data security. The advantage of splitting the Federal Modeling Center and the Cooperation Center is that the Federal Modeling Center responsible for data aggregation has never held the encryption and decryption keys. The cooperative center holding the key has never had training-related data from beginning to end. The two modules are completely isolated in function. This solves the problem of untrustworthiness of the central server and reduces the possibility of data leakage.
The main task of the cooperation center is the preparatory work for the federation study, which mainly includes establishing cooperation, generating and distributing the key pairs that need to be used in the federation modeling phase. This paper assumes that an institution in the federal study is the federal leader (special participant), and the others are the participants. The lead party establishes a project in the cooperation center, and the participants can apply to join, obtain the corresponding identity, and the lead party agrees. After the agreement is agreed, the key will be unified, and the necessary data encryption transmission cooperation will be carried out.
When federated learning is performing central data aggregation, the entire operation should be in an encrypted state. Therefore, a homomorphic encryption scheme needs to be adopted. Taking into account the computational complexity of the encryption algorithm and the actual application in the industry, this paper chooses the Paillier algorithm in Partial Homomorphic Encryption (PHE) as the basis of encryption. Paillier algorithm is an encryption algorithm that satisfies additive homomorphism.

Parameter aggregation of FL-CPMN.
In order to ensure that the various institutions in the federal study can join
and withdraw more flexibly, and will not affect the training of other
institutions. This paper designs an asynchronous training notification
architecture. The pseudo codes of the data aggregation steps is shown in
Algorithm 1. The leading party creates the model
at the Federal Modeling Center and initiates training. Participants can then
participate in federated learning by obtaining identity information and keys
from the cooperation center, and download the model. Let
Due to the inconsistencies in the time, computing power, and data volume of each participant joining the Federal Modeling Center, the training progress will be inconsistent. In response to this problem, the participants need to attach relevant information such as their own iteration rounds while sending the parameters. The Federal Modeling Center will save the current parameters and directly return the response of the successful acceptance of the parameters, instead of immediately returning the result of the parameter data operation. After waiting for a new participant to send the parameter data to the Federal Modeling Center or complete the data aggregation, each institution of the current calculation result is notified (for example, the parameter aggregation result of the q-th epoch involving k institutions has been calculated). According to their own strategies, each participant considers whether to pull the current version of the data from the Federal Modeling Center.
Compared with the mechanism of synchronous waiting, the asynchronous notification architecture allows all institutions to not need to join the federated learning at the same time, and can withdraw at an appropriate time after subsequent joins without affecting the institutions that are already doing federated modeling. And each participant does not need to wait for the training of other participants to maintain the connection for a long time, consume resources and bear the risk that the connection is disconnected and cannot be automatically reconnected. Participants can develop more flexible strategies for training. For example, as long as a few organizations participate in data aggregation, I can directly obtain it, instead of waiting for all organizations to participate in the training.
Local MeanNet model
This paper studies the inconsistency of credit dataset feature distributions and misclassification loss, and proposes a prediction model that is more suitable for the field of credit prediction. It is integrated into the federal learning framework. In order to solve the problem of multiple data-dense divisions, this paper considers the method of mean center as the basis, combined with deep learning, and proposes the method of multi-layer label mean center based on ladder network. The mean center method combined with semi-supervised learning was first proposed in meanS3VM [12]. The multiple data-dense divisions of the credit data are caused by multiple reasons. This paper argues that the feature output by different layers of the deep neural network can capture class centers from different angles. This method can alleviate the multi-center problem in credit data to a certain extent.
In the case of inconsistent misclassification losses, cost-sensitive loss fuction is designed to solve the problem. In this paper, the ladder network [17] is selected as the basic network, multi-layer average label module and cost sensitive function are added. It is called meanNet [22], and its network structure is shown in the Fig. 3. meanNet adds a label mean center module (LMD, Label Mean Distance) to each hidden layer of the noise reduction decoder on the basis of the ladder network, and divides the supervised loss into two parts: positive example misclassification loss and negative example misclassification loss. Label mean center module consists of three parts:
Predict the class center of positive and negative samples.
Calculate the distance between the predicted class centers.
Transform the distance from a maximization problem to a minimization problem.

The architecture of meanNet with two layers. meanNet contains three loss functions. cSC is the supervised cost using cross entropy and cost-sensitive function. UC is the unsupervised cost using MSE (Mean-Square Error). Label Mean Distance is the distance between estimated class center points which is called LMD.
The loss function of meanNet is shown in Eq. (2):
The supervised cost using cross entropy and cost-sensitive function.
The unsupervised cost using MSE (Mean-Square Error).
The LMD.
Among them,
For the specific form of
Among them, the input of the
In this section, some details of the datasets and experimental setup will be introduced, and the results of the experiments performed will be reported to prove the effectiveness of the proposed method.
Datasets
Two open source datasets are obtained for experiments. The smaller dataset comes from the “Good Letter Cup” big data algorithm competition held by Qianhai Credit Information in 2017. The data is collected and compiled by commercial credit bureaus under the Ping An Group, which is called Ping-An1
For the Ping-An dataset, its label is whether it is in default (default or non-default). The dataset contains 40000 loan records. The number of features of the original data is 490 dimensions, the positive samples are non-default data, and the negative samples are default data. The negative samples account for 14.73% of the total data.
The labels of the LC07-15 dataset have multi-type labels. There are 7 in total: Late (16–30 days), Late (31–120 days), Default, Current, Charged Off, Fully Paid and In Grace Period. This paper divides these seven types of labels into two categories: default (Late, Default, Charged Off, and In Grace Period)/non-default (Current and Fully Paid). The dataset contains a total of 887438 sample records. The number of features of the original data is 119 dimensions, of which negative samples account for 17.53%.
Basic statistics of the two datasets
For the Ping-An dataset, the entire dataset is completely desensitized, and only three data types are known: product information, user information, and web page information. This paper first analyzes the missing data and removes feature columns with a missing rate greater than 63%. This is because the missing data takes 63% as the dividing line. Then this paper completes the data, and finally do feature cross to obtain 600-dimensional features. Enter the data into XGBoost to find the feature importance, and finally select 46-dimensional features as the feature dimension of the training data.
For the LC07-15 dataset, more processing is required. First, we need to list the data that is not discretized, such as country, region, and loan status. Similarly, it is also necessary to deal with missing values, discard data columns with a missing rate greater than 75%, and complete the rest with data. It is also necessary to classify data labels and determine labels for positive and negative samples. Finally, according to the actual meaning of the data column and the feature importance ranking of XGBoost, the 38-dimensional feature is selected as the feature dimension of the training data.
For the division of the dataset, this paper uses the training set and the test set to be divided into 8:2, and sets the proportions of the three types of labeled data in the training set: 5%, 10%, and 20%. To ensure effectiveness, this paper obtains 10 random seeds for data division, and fixes the values of these 10 random seeds. The final experimental result is the average of 10 experiments, and the error value of the model is calculated based on the experimental results.
For the sensitivity coefficient c in meanNet, the value of Ping-An dataset is 1.3, and the value of LC07-15 dataset is 1.2. In order to better observe the experimental results, the F1 value has been enlarged by 100 times.
Baseline
This paper compares the performance of the current relatively popular
semi-supervised deep learning methods on the credit dataset. We use FPR,
Accuracy and F1 [6, 10, 26] three evaluation indicators to judge the effectiveness of the
model. The definitions of the three evaluation indicators are shown in
Eq. (4), (5),
(6), (7),
(8). Among them, True Positive (TP) indicates
that the prediction is a positive example, and the actual is a positive example.
False Positive (FP) means that the prediction is a positive case, but the actual
case is a negative case. True Negative (TN) indicates that the prediction is a
negative case, but the actual case is a negative case. False Negative (FN)
indicates that the prediction is a negative case, but the actual case is a
positive case.
After comparing the three evaluation indicators of FPR, Accuracy, and F1, it is found that the ladder network performs best. This paper will use ∏-Model [11], Mean Teacher [19], MixMatch [2], meanS3VM [12] and Ladder Network [17] as the basis for a comparative experiment with meanNet. The common experimental parameters of these models are shown in Table 2.
Ladder Network: The main structure of the ladder network is the deep
denoising AutoEncoder [21],
which is composed of three parts: Corrupted Encoder Moudle, Clean
Encoder Moudle, and Denoising Decoding Module, and add random Gaussian
noise to all hidden layers of the network noise module. On the MNIST
dataset, only a small amount of labeled data is used to obtain accuracy
close to the supervised neural network. The value of λ
is
∏-Model: This method is similar in thought to the ladder network, but the
learning of the unsupervised part is more direct, making the whole
network more suitable for semi-supervised work. On the Ping-An dataset,
the maximum value of
Mean Teacher: The network structure adopts an idea similar to ∏-Model, and considers to solve some problems of ∏-Model from the perspective of weight sliding translation.
MixMatch: This model integrates current effective schemes in the field of semi-supervised learning. There are two main methods: Consistency Regularization [11, 18] and Entropy Minimization [7]. The value of T is 0.5, the value of K is 2, and the value of α is 0.5. When doing data augmentation, do not perform random rotation.
meanS3VM: A mean center method combined with semi-supervised learning is
proposed. Research shows that after knowing the mean center of each
category of unlabeled samples, the semi-supervised support vector
machine is very similar to the supervised support vector machine that
knows the labels of all unlabeled samples. For the parameters of
meanS3VM, set
Common parameters of baseline models
Common parameters of baseline models
Table 3 shows the performance of ∏-Model, Mean Teacher, MixMatch, meanS3VM, Ladder Network and meanNet on the Ping-An dataset with 5% labeled samples.
When the positive sample data is accounted for 10% and 20%, the experimental results are basically consistent with the positive sample accounted for 5%. It can be seen that for different data partition settings, the meanNet method, which combines multi-layer label averages and cost-sensitive, performs well in all evaluation measures for Ping-An dataset. In the entire experimental setting, without negatively affecting the accuracy rate, the cost-sensitive ladder network was incorporated to reduce the false positive rate by 1.58% to 2.74%. meanNet shows that the false positive rate is reduced by 2.35% to 2.43%. From the perspective of accuracy, the fixed cost sensitivity coefficient value is compared with the ladder network and meanNet, and the accuracy is increased by 1.42% to 3.09%. Considering the model’s performance in false positive rate, accuracy rate, and F1 value, meanNet are significantly better.
Table 4 is the results of comparasions on LC07-15 dataset. On the LC07-15 dataset, after incorporating cost sensitivity, the false positive rate on the ladder network is reduced by 0.7% to 2.46%, and the false positive rate on the meanNet is reduced by 1.09% to 2.38%. Similarly, after fixing the cost sensitivity coefficient and comparing the accuracy rate, meanNet is 0.71% to 1.16% higher than the ladder network. In the case of ensuring that the accuracy rate is not excessively negatively affected, the integration of cost-sensitive methods can effectively reduce the false positive rate, which is a more important point in the field of credit prediction. At the same time, the multi-layer label mean enhancement method proposed in this paper can effectively improve the performance of the model in the field of credit prediction.
The method of multi-layer label mean enhancement mainly requires that in the learning process, the difference between the sample centers of different categories in the high-dimensional feature space is maximized. This idea can be summarized as follows: in the classification problem, the greater the distance between different categories in the feature space, the easier the classification problem is to be solved, and a better classification effect can be obtained. The cost-sensitive module is derived from the requirements of credit prediction itself, that is, the loss caused by the misclassification of default samples is greater than the loss caused by the misclassification of non-default samples. The experimental results also better prove that the credit prediction method that combines the above two methods can have better performance.
In order to verify the effectiveness of the federated learning framework proposed
in this paper, this paper conducted comparative experiments on three cases of
single-machine full data model training, single-node data model training, and
multi-node data model training under the federated learning framework. The
number of participants in joint learning is set to 2, named Client A and Client
B. The preliminary division of the dataset remains the same as the previous
paper, but Client A and Client B each hold 50% of the training data. Suppose the
training set is
Table 5 shows the experimental results of three different situations under different proportions of labeled samples on the Ping-An dataset. Considering federated learning, the effect of federated learning training is usually affected by the loss of accuracy after encryption operations and data aggregation problems. There is a gap between the federated learning method of fusing meanNet on the Ping-An dataset and the meanNet method of full data in a stand-alone environment. The gap in false positive rate is 2.48% to 3.65%, and the gap in accuracy is 2.63% to 3.89%. The experimental results also show that, in terms of predictive performance, there is a certain gap between the method of fusion federated learning and the mode of training the data in a centralized manner. Our FL-CPMN has been significantly improved in terms of the training results of each single node with half the amount of data.
Experimental results of FL-CPMN on Ping-An dataset
(
)
Experimental results of FL-CPMN on Ping-An dataset
(
Experimental results of FL-CPMN on LC07-15
dataset(
Table 6 shows the experimental results on the LC07-15 dataset. On LC07-15, the difference in false positive rate of meanNet with horizontal federated learning and the upper limit of the model is 4.13% to 4.83%, and the difference in accuracy is 3.38% to 3.9%. It can be seen from the two data experimental results tables that for the experimental results of half of the data in a single-machine environment, the experimental results of the federated learning framework fused with meanNet have been greatly improved. If more participants join and expand the data for federal modeling, it will provide financial institutions with richer data information, promote inter-institutional cooperation, and effectively improve the effect of model training. For the encryption module, with the further development of the homomorphic encryption field, it is expected that more efficient encryption schemes will be adopted in the future to achieve better results.
The experimental results of meanNet with full data in a stand-alone environment are used as the upper limit of the credit prediction scheme integrating horizontal federated learning. From the experimental results of the two datasets, it can be seen that when the amount of training data is too small, the problem of prediction will be difficult to solve well. When both the labeled data and the unlabeled data become half of the original, the prediction performance of the model drops sharply. This also shows that in the case of insufficient data, the use of the federated learning framework proposed in this paper can effectively promote the secure exchange of data and information among various institutions and improve the effect of model training.
This paper proposes a credit prediction approach based on federated learning, and study the encryption scheme in the process of model parameter transmission. The framework proposed in this paper can effectively promote data cooperation between institutions and improve the effect of model training on the premise of protecting the data privacy and security of various institutions. At the same time, in order to solve the problem of multi-sample center and inconsistent misclassification cost of sample data in the field of credit prediction, this paper propose a multi-label mean center model based on semi-supervised deep learning. Through experiments on two large credit datasets, the feasibility and effectiveness of the framework and model proposed in this paper are proved. In addition, it also shows the advantages of multi-institution credit prediction under the framework of this paper. Based on the framework proposed in this paper, more extensive research can be conducted in other fields in the future, such as federated speech recognition and so on. Due to the limitation of the credit dataset, this paper does not conduct experiments and research on non-IID data, which can be followed up in the future. This paper focuses on study of the horizontal federated learning in federated learning. In order to meet the needs of different scenarios, a framework compatible with horizontal and vertical federated learning can be constructed to promote cooperation and exchanges between more industries and fields.