
Abstract
Tensors have been explored to share latent user-item relations and have been shown to be effective for recommendation. Tensors suffer from sparsity and cold start problems in real recommendation scenarios; therefore, researchers and engineers usually use matrix factorization to address these issues and improve the performance of recommender systems. In this paper, we propose matrix factorization completed multicontext data for tensor-enhanced algorithm a using matrix factorization combined with a multicontext data method for tensor-enhanced recommendation. To take advantage of existing user-item data, we add the context time and trust to enrich the interactive data via matrix factorization. In addition, Our approach is a high-dimensional tensor framework that further mines the latent relations from the user-item-trust-time tensor to improve recommendation performance. Through extensive experiments on real-world datasets, we demonstrated the superiority of our approach in predicting user preferences. This method is also shown to be able to maintain satisfactory performance even if user-item interactions are sparse.
Introduction
Currently, in a network environment in which data exhibit explosive growth, when faced with a large amount of information, it is difficult for users to obtain information that is useful to them, which reduces the efficiency of information use. Currently, the best method to increase the use rate of information is a recommendation system [1]. A recommendation system can provide personalized recommendations based on a user’s preferences and the available information so that the user can obtain the content he or she likes. At present, many recommendation algorithms have been proposed in different scenarios, such scenes with time information and tag information, etc. [2, 3]. Among the existing recommendation algorithms, collaborative filtering (CF) is popular and one of the most widely used recommendation algorithms [4]. The collaborative filtering method utilizes the implicit or displayed feedback of users to make recommendations without domain information. Currently, there are user-based and item-based collaborative filtering algorithms [5]. User-based collaborative filtering focuses more on socialization and is used more in news recommendations. Item-based collaborative filtering algorithms focus more on users’ historical behavior, and recommendations are more personalized. But the CF algorithm has weak adaptability to new samples (Weak generalization ability). In order to solve this problem, matrix factorization is proposed.The concept of hidden vector is added to matrix decomposition, which strengthens the model’s ability to deal with sparse matrices [41, 42]. Matrix factorization usually associates information in two dimensions. In practical applications, user preferences are affected by many factors, such as time, social information, etc [5–7]. In the process of designing a recommendation algorithm, we consider adding influencing factors to improve the prediction accuracy. Therefore, we expand the matrix to a high-dimensional space and call this expanded high-dimensional matrix a tensor. A tensor can incorporate more information to mine the relationships for recommendation.
Higher-dimensional tensors mean that more effective information can be used. Adding valid information related to the user-item relationship can improve prediction accuracy [6–8]; In our model, we consider the influences of time [10] and user trust relationship information [32] on the recommendation system. Time information reflects that users’ behavioral preferences are dynamic, and they like different items at different time points. At the same time, people with similar preferences usually have similar choices in daily life. On this basis, we quantify their preference, which is called trust relationship. The higher the trust between two users, the more likely they are to like the same item. The addition of trust information can alleviate the “cold-start problem”. The “cold start problem” is caused by the fact that there is less new user data and the model cannot make personalized recommendations for users. Therefore, more information needs to be added for new users to alleviate this problem. In recent years, many models have integrated time information on the basis of CF [10–12]. However, their models only recommend the observed discrete time points, and they have difficulty addressing the “cold-start problem”. Rafailidis and Daras proposed a tensor factorization method based on label clustering [13], which clustered label information to alleviate the sparsity of data. Ziwei Zhu et al. propose a novel fairness-aware tensor recommendation framework that is designed to maintain quality while dramatically improving fairness [14], which is suitable for user friend location activity, but this model does not incorporate time information and has certain limitations. Our model is a 4-dimensional tensor that combines trust information with user and item and time information. It mines the relationships between users and items under trust relationships in different time periods because under normal circumstances, user interactions with items are sparse, especially in a high-dimensional tensor space with other information added. To solve the problem of data sparsity, we use traditional matrix decomposition to preprocess the tensor model, which reduces the sparsity of data to some extent. For tensor model decomposition, we adopt the block item tensor decomposition method (BTD) proposed by Lieven De Lathauwer [15], which Kun Tang et al. applied in traffic prediction [16] and achieved good results. The main contributions of our model are as follows: Before decomposition and prediction, to pretreat the tensor, the two steps of the tensor slicing operation and matrix decomposition are selected. The purpose is to reduce the sparseness of the data. Using the four-dimensional tensor of user trust and time, the project matrix of traditional users is pushed to a higher dimension, which can combine more information to mine more potential relationships and improve the prediction accuracy. The block item tensor decomposition method combines traditional CANDECOM/PARAFAC (CP) and Tucker decomposition to decompose and predict the tensor model [43]. This method not only overcomes the nonuniqueness of Tucker’s method, but it also carries more information than the low-rank item of CP decomposition.
The remainder of this article is as follows. Section 2 introduces the application of tensors in the related research. Section 3 specifically introduces the related definitions and the algorithm of this paper. Section 4 conducts experiments to compare this paper’s method with traditional algorithms and analyzes the algorithms’ performances based on the experimental results. The fifth part is the summary and outlook.
Related studies
At present, many recommendation algorithms based on tensors have been proposed. Symeonidis et al. proposed a tensor recommendation algorithm with tag context factors [19], constructed a three-dimensional tensor of user item labels, and used sparse high-order singular value decomposition (HOSVD) [46] to decompose the tensor into a matrix and a core tensor. HOSVD is a high-order generalization of matrix Singular Value Decomposition (SVD) [18]. This method is suitable for the decomposition of dense tensors, but not sparse tensors, and HOSVD may not find the best low-rank approximation of tensors; therefore, the actual application prospects are not good. Hidasi and Tikk et al [20] applied a tensor factorization method based on the least squares (ALS) to implement context-aware recommendations [21,22, 21,22]. However, the disadvantage of this method is that it has poor convergence for sparse data and cannot be expanded to large data sets. Stathis Maroulis et al proposed a personalized recommendation model that adds points of interest (POIs) to increase user experience through contextual POI awareness [38]. Hao Wen and others [39] added time weights to their models, which can reflect the changes in user interests over time. Symeonidis et al [24] also proposed a geographic recommendation system based on the friend contact algorithm and high-order singular value decomposition algorithm, which is suitable for user friend location activities. However, this method still cannot incorporate time information. In order to apply spatiotemporal information to point of interest recommendations, Ying et al. [25] used context based on user preferences to perform tensor factorization. They also proposed a POI user preference inference model based on the weighted hyperlink-induced topic search (HITS). Kun Tang et al. formed a three-dimensional tensor of a driver’s road segment time and formed a model with features such as the geographic space [16] to recommend personalized travel plans to users. Pei Ma et al. used the similarity between users to construct a three-dimensional tensor model for recommendation [32] but did not consider the time factor, and user preferences may change in different time periods.
To solve the above problems, we add time information, which can reflect the changes of users’ preferences in different time periods. The decomposition method is partly based on the BTD algorithm, which is different from HOSVD, which only estimates the unknown term according to its own non-zero term and ignores other information, BTD approximates by a sum of low multilinear rank terms [15, 17]. Compared with the above method, the accuracy of the experimental results has been improved. On this basis, aiming at the problem of data sparsity, matrix decomposition is used to pre-fill the unknown positions of the tensor, which reduces the sparsity of the tensor to a certain extent [30].
Tensor model
Related overview
Tensor:
A tensor can be regarded as an extension of a low-dimensional array. It has three major advantages when processing data, namely, dimension reduction processing, missing data filling, and implicit relationship mining. A one-order tensor is called a vector, a two-order tensor is called a matrix, and three-order and above tensors are called tensors. The values in a three-dimensional tensor usually have three coordinates. Our model consists of time-trust-user-item together to form a four-dimensional tensor.
Tensor slicing:
The tensor slicing operation is an operation to extract a matrix from a tensor. If two dimensions are reserved in a tensor, other dimensional changes can result in a matrix, which is a tensor slice. An example is a user project time three-order tensor
User trust:
Friends or relatives around a user may affect the user’s choices. For example, if a user wants to buy a piece of clothing, he usually consults his friends who have similar clothing styles. There is a certain degree of similarity between different users.
Matrix decomposition:
Matrix A*B is used to approximate matrix M. Then, the value obtained by A*B can be used to estimate the unknown value in matrix M, and matrices A and B can be regarded as the decomposition of matrix M [31], M ≈ A * B.
Description of related operations:
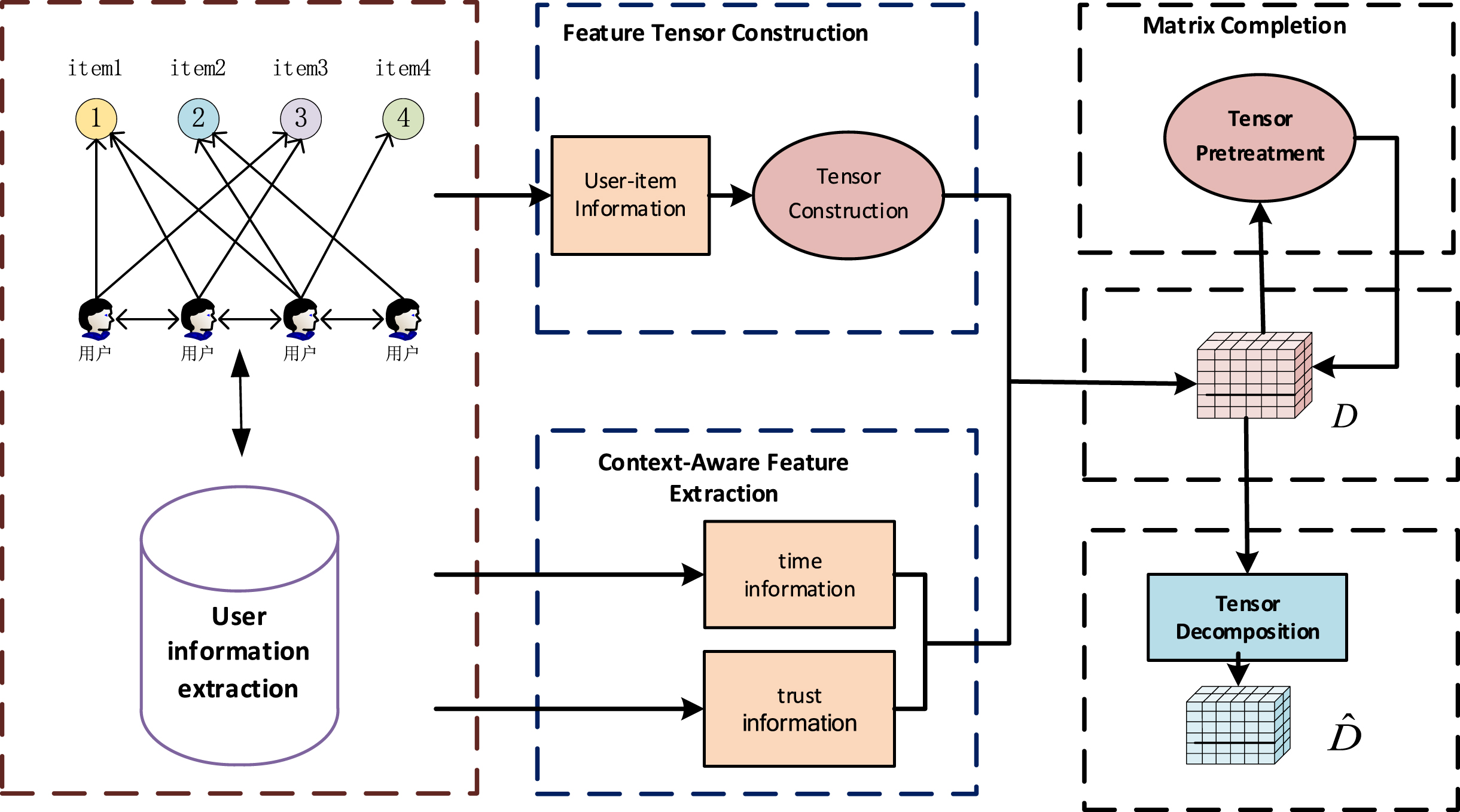
Framework model.
Tensor model:
We collect various user information from the data set and extract trust and time information to construct a fourth-order tensor
Contextual information:
User behavior is usually influenced by friends or other people. For people with the same likes or interests, when one user likes a new item, the other user is likely to like this item.For example, user
Equation (1) is the similarity penalty for popular items in the common interest list of user U and user V. Matrix Y is a scoring matrix based on the similarity of items. Different items i and j have certain similarities, which can be calculated by formula Equation (2). Finally, the information is integrated into the tensor model for prediction. The time information can reflect the changes in user interests. Users will like different items at different points in time. For example, users will want to buy down jackets or cotton-padded clothes in the winter and t-shirts in the summer; the books that researchers read will also change with the depth of their research, initially reading some introductory books and then transitioning to professional books. Therefore, time information is also one of the more important influencing factors in personalized recommendation systems.
Data preprocessing
Tensor preprocessing: Data preprocessing is performed in two steps: tensor slicing and matrix decomposition. The processing steps are shown in Fig. 2. A is the user item matrix slice cut out of the model. We decompose the matrix sliced in the model, taking into account the actual meaning of the matrix. The value of the matrix cannot be negative. There is a m × n rating matrix R, where r
ij
is the rating of user i on item j. R can be decomposed into R = UV
T
. U is the m × k user matrix, and V is the n × k item matrix, where k is the decomposed user and item hidden correlation dimension. The matrix factorization process is similar to the tensor factorization process, which is an approximate process, R ≈ UV
T
. We need to acquire the smallest error and construct an objective function:

Framework model.
For the optimization of the objective function, this paper adopts the classic stochastic gradient descent method. This method takes n samples to calculate each time, and the update time is less and the speed is fast. The update formula is as follows:
where α > 0 is the step size of the stochastic gradient descent, and j : (i, j) ∈ S, I : (i, j) ∈ S is the index of the nonzero elements in the corresponding vector. By updating, we can fill the matrix to obtain a new matrix.
Core initialization: To perform context-aware tensor decomposition, we need to initialize a core tensor and four solution matrices. The purpose is to generate an initialization tensor for the optimization of the subsequent algorithm. Due to the nonconvexity of the model, the final solution depends on the initialization to some extent. Normally, random initialization is used to initialize the tensor with random values in the interval [0,1]. Random initialization cannot well control the accuracy of the final result. At present, there are other initialization methods [33], and good hyperspectral results have been obtained. In this paper, considering the performance of the model and without introducing more external factors, the random initialization method is used in the experiment.
Block item decomposition (BTD):
There are many ways to decompose a tensor model, and different methods have different advantages. Before introducing the block item decomposition algorithm, we first introduce the classic Tucker/high-order odd value decomposition (HOSVD) and CP decomposition.
The CP decomposition of the third-order tensor is shown in Fig. 3(a). The rank of tensor X is the smallest number of tensors of rank 1 in the linear combination. Among them,
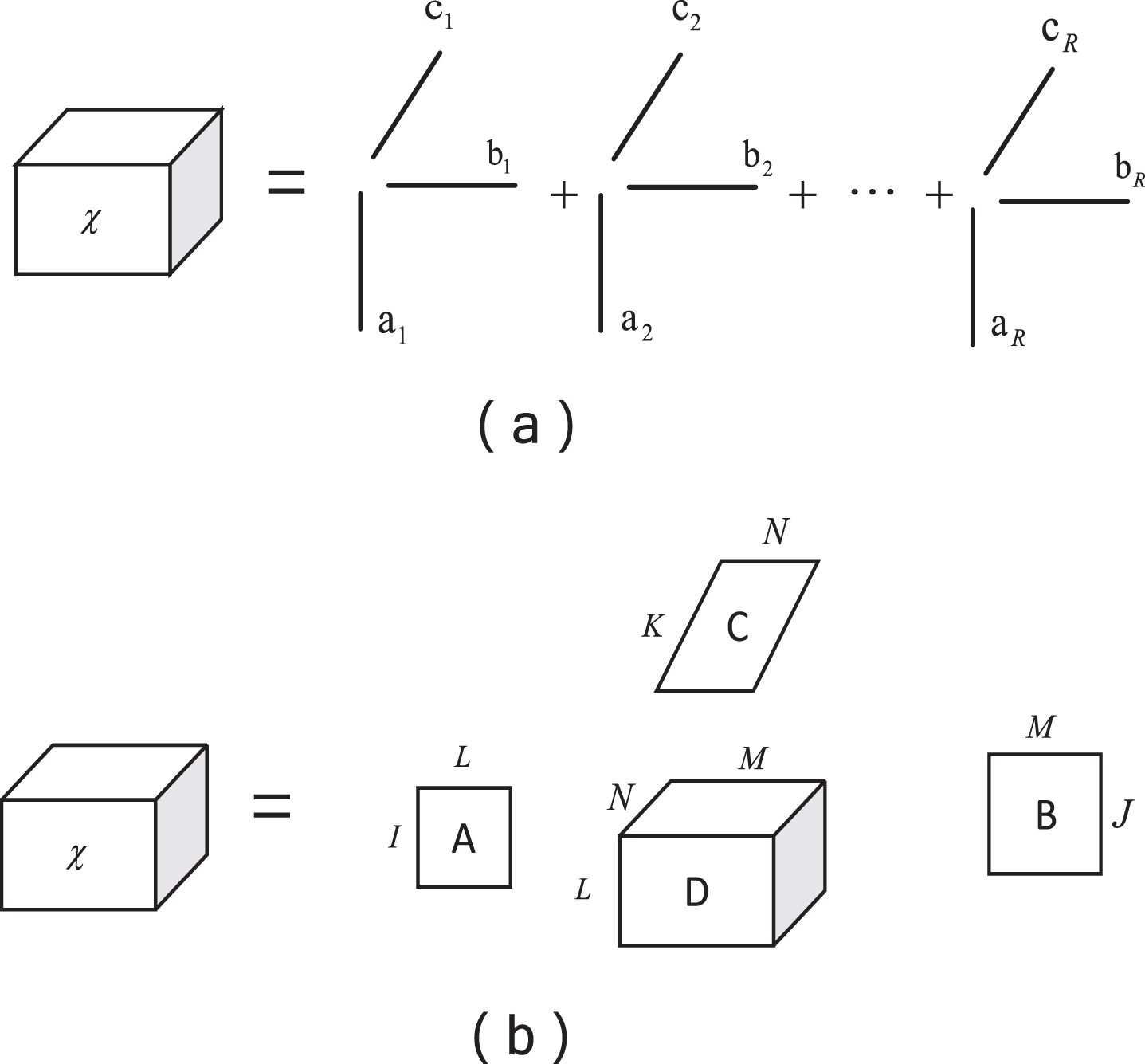
Tucker/CP decomposition visualization diagram.
A schematic diagram of the Tucker decomposition is shown in Fig. 3(b).
Similar to traditional matrix factorization, the core tensor of tensor factorization represents the implicit connection between each dimension. We cannot explain what this implicit relationship represents, but we can use these relationships to make effective predictions. The CP decomposition method requires prior knowledge of the rank of the original tensor. To date, there is no direct algorithm to determine the rank of a tensor. In actual situations, this is a difficult problem of np. Generally, for simple consideration, the value of max(I, J, K) is used as the rank of the tensor in the CP decomposition. Tucker decomposition itself is not unique.
Our experiment uses the tensor block decomposition algorithm (BTD) because it unifies the traditional Tucker/high-order odd value decomposition (HOSVD) and CP decomposition. The results of the traditional Tucker decomposition are not unique while the CP decomposition decomposes a tensor into the sum of multiple ranks. However, the features or information that a rank can carry because of its rank is very limited. The BTD decomposition unifies the two decompositions to make the decomposition unique. BTD decomposes a tensor into the sum of multiple low linear rank items. Each low linear rank item may have a different multilinear rank. In addition, each item can carry more information or features, as shown in Fig. 4.

Visualization of the decomposition of a tensor into the rank sum.
For a tensor D ∈ RI×J×K, the decomposition and form of a rank (L, M, N) of D are:
where S r ∈ KL×M×N is full rank (L, M, N), A r ∈ KI×L, B r ∈ KJ×M, and C r ∈ KK×N.
Based on the BTD paradigm, our context-aware recommendation model can be expressed as an optimization problem. We call the model in this article MCA-BTD, and the optimized objective function is:
where
The algorithm is as follows in Fig. 5.

BTD block item decomposition algorithm.
Dataset
Our article uses the Ciao 1 and MovieLens 2 public data sets that have a trust relationship. Note that the MovieLens data set does not have a trust relationship, and we need to calculate it [33, 43].
The Ciao data set was released in 2011 and captured user social and rating information on the Ciao website. Sufficient registration on the site allows users to rate and comment on the items and to browse other users’ comments and ratings on items, which can help users make appropriate choices. A trust relationship can be established between users on the website. The detailed descriptive information is shown in Table 1.
Statistical information of the Ciao and MovieLens datasets
Statistical information of the Ciao and MovieLens datasets
The MovieLens dataset is an available scoring dataset collected by GroupLens from MovieLens. The dataset has different sizes and is collected in different time periods. We selected the 100K dataset, which a dataset in which 1000 users rated 1700 movies 100,000 times (1–5). Each of these users has watched at least 20 movies, and users’ information such as their age, gender, and occupation is included. The detailed descriptive information is shown in Table 1.
The performance evaluation of an algorithm is usually based on the accuracy of the recommended prediction. For general classification models, the main indicators for evaluating the accuracy of recommendations are the following: the recall, the accuracy, and the coverage. For the score prediction recommendation model, we generally use the root mean square error (RMSE) and the mean absolute error (MAE) as indicators of the evaluation accuracy. Our model is mainly used to predict the user ratings of the item, so we use the MAE and RMSE as evaluation indicators to evaluate the performance of the algorithms. These two indicators are commonly used in a variety of different scenarios. Generally, the smaller the value is, the higher the accuracy, and the better the algorithm performance. The specific definition is shown in Table 2, where N is the total number of predicted ratings and D is the test set data.
Validation metrics
Validation metrics
Comparison of innovative points
We verify the advantages of our model from the following three aspects. The low-rank tensor decomposition of trust relations (LTF-ISTR) [32]. This method combines user trust values to form a three-dimensional tensor model to predict user ratings and achieves good results. The article uses the Tucker decomposition to make decomposition predictions for the entire model, but it is a factor of time. Verify the effect of the time factor in personalized recommendation. The time factor reflects the changes in user preferences and interests. Each person’s general preferences will be affected by many factors, and clothing and diet will be affected by seasonal changes. Therefore, we experiment to compare the effects of this information. The effect of matrix filling on the experimental results. The experimental four-dimensional tensor will have the problem of sparseness, so we analyze this problem. We compare the improvement effect of the tensor model before and after filling on the final experimental results.
The purpose of comparing the experiments using the decomposition of the trust relationship tensor is to compare the BTD and Tucker methods and show the superiority of the BTD algorithm to a certain extent. Our experiments are compared on the Ciao data set in order to better guarantee that the experimental results are not affected by other features. The time dimension of our model is removed, and the same features as the method are used for comparison. The experimental results are shown in Table 3, where LTF-ISTR is the trust relationship tensor Tucker decomposition model, and CA-BTD is our trust BTD model. The experimental results show that the BTD method, which improves the accuracy of the experiment to a certain extent, is superior to the traditional Tucker method.
Comparison of the Tucker decomposition and BTD under the same characteristics
Comparison of the Tucker decomposition and BTD under the same characteristics
We then proceed to determine the impact of time features on the prediction accuracy. We add time features on the basis of user-item-trust and analyze the improvement results of time features on the prediction model. The experimental results are shown in Table 4. Among the models, CA-BTD-3 represents a three-dimensional tensor model with only user-trusted items, and CA-BTD-4 represents a four-dimensional model with the addition of time factors. The experimental results show that time can significantly improve the model accuracy. This reflects that users’ preferences vary greatly over time, so time is a very important contextual feature in a personalized recommendation system. Aiming at the sparsity problem of the high-dimensional tensor space, we use traditional matrix factorization to fill the matrices sliced by the tensor to alleviate the sparsity of the model and further improve the prediction accuracy of the model. Our specific test compares the model without matrix filling to the model with matrix filling. We named the model without filling the CA-BTD and the model with filling the MCA-BTD. The experimental results are shown in Table 5. The experimental results reflect that matrix filling is effective since it reduces the sparsity of the model and improves the accuracy of the algorithm.
Comparison of time characteristics
Comparison of matrix filling results
Through the above comparative experiments, we have separately addressed the three innovations of this article. The addition of the time dimension makes the model accuracy the best, reflecting that that context information is very important information for the personalized recommendation model. Information corresponds to the characteristics of different users, and we can reasonably use this information to make more accurate predictions of user behavior.
Algorithm comparison
We combine the model of this paper with the matrix decomposition time-trust context decomposition algorithm to compare the results of experiments with the results of other recommendation algorithms to test the performance of the algorithm. Our main comparison algorithms are as follows: The collaborative filtering algorithm based on nonnegative matrix factorization (NMF) [35] is a privacy-preserving collaborative filtering algorithm combining random perturbation technology with nonnegative matrix factorization, which can protect user privacy while also generating recommended results. This method is an evolution of the KNN algorithm [44]. It uses the information close to the recommended date to help improve the recommendation results and reduce the information overload of the recommendation engine. User preference prediction recommendation based on SVD++ [36]. This method first uses a logistic regression to preprocess the original data, including click-through rates, shopping carts, purchase items, etc.; and then it uses the SVD++ model to analyze the processed data. This conducts the predictive analysis of data. The pairwise interaction tensor factorization (TF) [45] method is a special case of the traditional tensor decomposition model. The running time is linear, and it conducts pairwise interaction modeling between user items and related information. This article propose a new rating prediction model named the Rating-Trust-based Recommendation Model (RTRM) [40] to explore the influence of internal factors among the users.
We compared the above algorithms and the algorithm in this paper on the Ciao data set, and the comparison results is shown in Fig. 6. The experimental results show the relative superiority of the algorithm in this paper compared to the above algorithms. The two indicators of the RMSE and MAE show that the algorithm in this paper achieves the best prediction accuracy. Compared with RTRM, our method adds time information to reflect the user’s interest changes at different times,more contextual information can improve the prediction results to a certain extent. The BTD method extends the TF method by decomposing the tensor into a sum of low multilinear ranks. The BTD method is more accurate than the TF method. Benefiting of the original tensor pretreatment by matrix decomposition and iteration initialization preprocessing, our model is more accurate than the above methods. Figure 7 shows the comparative experimental results of various algorithms on the MovieLens data set. The analysis of the experimental results shows the performance of each algorithm is improved compared with that on the Ciao data set. The reason is that the density of the MovieLens data set is higher and the sparsity of the MovieLens dataset is lower than those of the Ciao data set. It can be seen that data sparsity has a certain impact on the prediction accuracy.

Algorithm comparison on the Ciao data set.

Algorithm comparison on the MovieLens data set.
In order to test the performance of each algorithm on different sparse data, we conduct different sparsity comparative experiments on the Ciao data set. The experimental results are shown in Table 6.
Results of the MAE and RMSE for each algorithm with Ciao dataset densities of 90%, 80%and 70%
The comparison results of the experiments show that our algorithm is relatively less affected by data sparseness under different data densities. Compared with the abovementioned traditional algorithms, the MCA-BTD algorithm has better performance in sparse conditions. In actual situations, user data are usually very sparse, so the MCA-BTD has more advantages in practical applications.
This paper proposes a method that uses a matrix to fill in the missing values in the tensor, and combines user trust and time information to predict user ratings. The trust relationship between users is first established on the existing data set, and then the processed data set is represented as a fourth-order tensor of users, projects, trust relationships and time information. Slice the tensor and use matrix decomposition to fill in missing items to reduce data sparsity. The BTD decomposition method is used to decompose the filled tensor. From our experimental results, our method has a good improvement in predicting user preferences.
For future work, we plan to (1) extend the single-level user trust relationship to multi-level user trust to improve the accuracy of user preference prediction; (2) try to add more user information. For example, the user’s age, gender, etc. These can all become research trends for potential information in future predictions.
Footnotes
Acknowledgments
This work was supported by the National Science Foundation of China under Grant No. 61867006, the Education Reform Project of Higher Education of Xinjiang Uygur Autonomous Region under a Study on the Application of Teaching Methods Combining MOOCs with a Flipping Classroom (No. 2018JG40), the Innovation Project of Sichuan Regional under Grant No. 2020YFQ2018, the Key Laboratory Open Project of Science & Technology Department of Xinjiang Uygur Autonomous Region under Research on Video Information Intelligent Processing Technology for Xinjiang Regional Security, and the Major Science and Technology Project of Xinjiang Uygur Autonomous Region under Grant No 2020A03001.