
Abstract
Many real-world knowledge graphs are complex and keep evolving over time. Inferring missing facts in temporal knowledge graphs is a fundamental and challenging task. Previous studies focus on link prediction in static knowledge graphs which hardly extracts the temporal features effectively. In this paper, we propose a novel deep learning model, namely KBGAT-BiLSTM, which is capable of solving long-term predict problems and is suitable for temporal knowledge graph with complex structures. First, we adapt the Graph Attention Network (GAT) to learn the structural features of knowledge graph. Then we utilize the Bidirectional Long Short-Term Memory Networks (BiLSTM) to learn the temporal features and obtain the low-dimensional embeddings of entities and relations. Finally, we employ a scoring function for link prediction in temporal knowledge graphs. Through extensive experiments on YAGO, WIKI, and ICEWS18 datasets, we demonstrate the effectiveness of our model, compare the performance of our model with several different state-of-the-art methods and further analyze the properties of the proposed method.
Introduction
Link prediction has been widely used in various areas, such as social networks [1, 2], question answering [3], recommender systems [4], etc. The real-world knowledge graphs (KGs) keep evolving, entities and relations may appear or disappear. Previous works focus on the link prediction of static knowledge graphs, which is designed based on the structure of the knowledge graph, making it difficult to use temporal information effectively. So, in recent years, Link prediction for temporal knowledge graphs (TKGs) has attracted widespread attentions. It learns both structural features and historical information of TKGs in order to better understand the evolution process and the topological structure of TKGs.
Link prediction for TKGs attempts to find the missing relations or entities. For example, in Fig. 1, a quadruple (Trump, visit, China, 11/8/17) is represented as two entities: (Trump, China) along with a relation (visit) and a time (11/8/17). Many real-world TKGs may lack entities or relations and even have wrong quadruples. So, we need to correct these wrong quadruples or predict missing relations or entities. KG embeddings are generally recognized as a fundamental tool for this due to their extensive usages in link prediction.
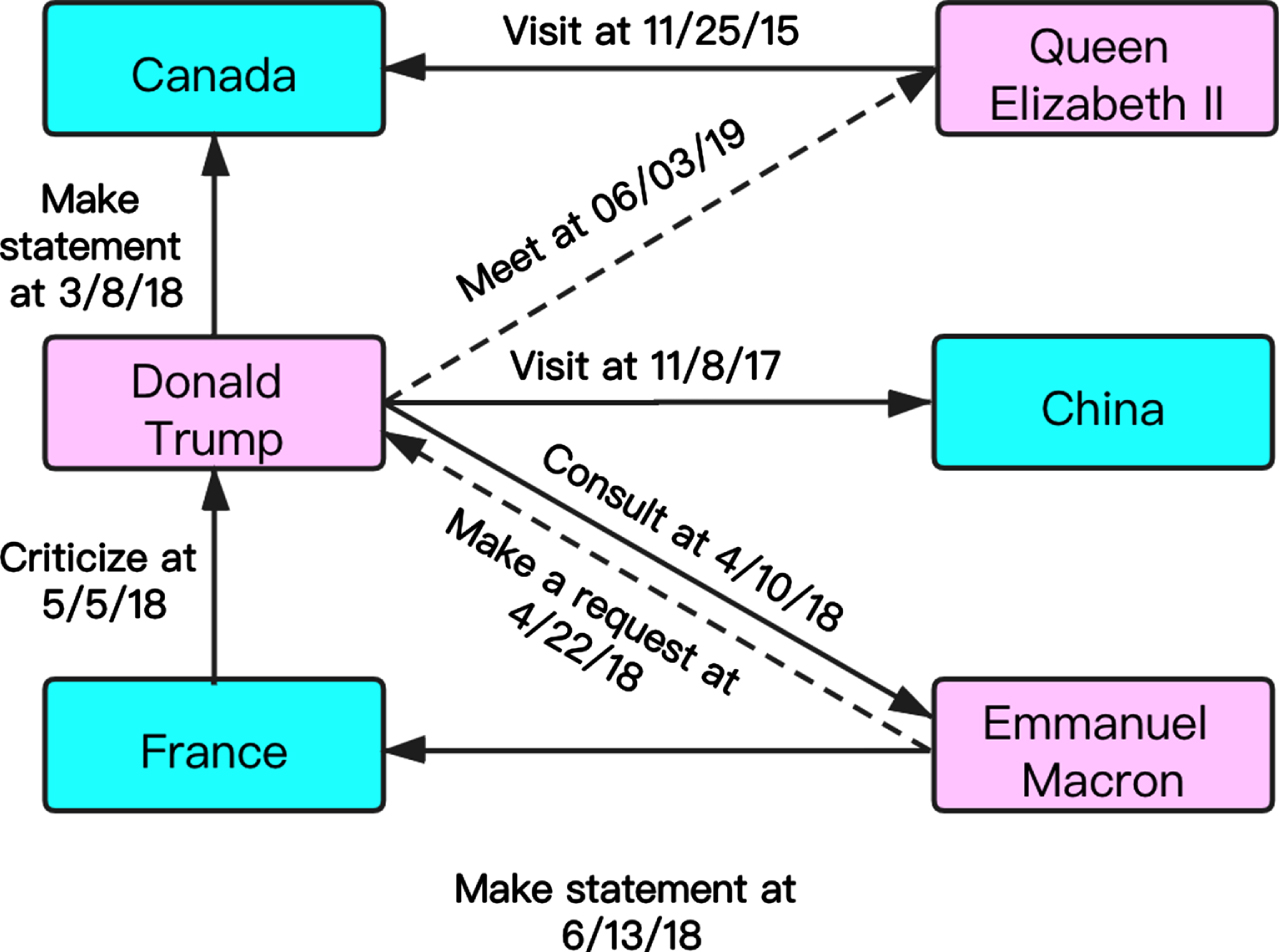
A subgraph of temporal knowledge graphs contains relations between entities and temporal information. Entities include places (blue) and people (purple). The dashed lines represent predicted quadruples.
State-of-the-art link prediction methods for TKGs can be primarily classified as: 1) based temporal point process [5, 6], 2) based time steps [7, 8], 3) based dynamic network [9, 10]. The first group of methods aims to model the occurrence of an event as a multidimensional temporal point process by conditional intensity functions and relation scores. It can predict whether an event will occur and when it will occur. But this method cannot model events that occur at the same time step. The same subject entity and relation pair may simultaneously involve many different object entities, which often happens in the real world. The second group of methods predicts events based on time steps. So if the time step of the event is unknown, link prediction cannot be made. It is pretty bad for TKG to predict. In reality, there are many quadruples that lack time information. Moreover, their models are relatively simple, rely on scoring functions, and cannot effectively capture the structural information of the knowledge graph. The last group of methods ignores the importance of relations. Dynamic networks are capable of learning the embedding of entities and learn the structural information of TKGs through the neural network and the attention mechanism effectively. Still, they are difficult to capture the relationship features and potential semantic information of neighborhood entities effectively. They cannot learn the embedding of relations, ignoring the importance of relations and reducing link prediction accuracy.
To address the aforementioned defects, we propose a novel deep learning model KBGAT-BiLSTM for modeling dynamic multi-relational directed graphs. Our model is based on the Graph Attention Networks to capture the multi-hop neighborhood features of a given entity. Compared with the based temporal point process models, our model can model events that occur at the same time step, learn both the structural and the temporal characteristics of TKGs effectively, and predict future additions or disappearances quadruples. Our model considers TKG data in a dynamic scenario, where each triple consists of two entities and their relations sequentially over time. So it can capture entities and relations latent temporal features. We conducted experiments on three public temporal knowledge graph datasets to demonstrate the effectiveness and superiority of the proposed model for link prediction of temporal knowledge graphs. Our contributions are summarized as follows: We propose a novel deep learning model to perform embedding on temporal knowledge graphs. The model is capable of capturing both the structural and the temporal features of entities and relations for link prediction. To the best of our knowledge, we are the first to apply GAT to link prediction of temporal knowledge graphs. The proposed new deep architecture is competent to solve long term prediction tasks. We utilize KBGAT at each time step, and then we employ BiLSTM to capture the temporal features of entities and relations.
The structure of the rest of the paper is as follows. We first introduce related work in Section 2 and then introduce some concepts and our method in Section 3. Section 4 describes the datasets and experimental results. Finally, we conclude this paper and outline future work in Section 5.
Recently, some researchers have proposed different embedding methods for link prediction. We divide these methods into static and temporal KGs link prediction.
Static KGs link prediction
Link prediction of static knowledge graphs includes reasoning based on translation, Convolutional Neural Networks (CNN), graph, and hybrid. TransE [11], DISTMULT [12] and ComplEx [13] are based on the translation model. TransE learns the embedding of entities and relations and then uses it to predict triples. After TransE many variants were derived, such as TransH [14], TransG [15] and TransR [16]. DISTMULT expresses the relation as a matrix. The head entity vector can be transformed into the tail entity through the linear transformation of the relation matrix. ComplEx uses complex-valued embeddings to handle various binary relations, among them symmetric and antisymmetric relations. ConvKB [17] and ConvE [18] is based on CNN reasoning, using CNN to analyze the features of triples for link prediction. ConvKB models the relations among the same dimensional entities of the embeddings. This implies that ConvKB generalizes transitional characteristics in transition-based embedding models. ConvE is a competitive 2D convolutional model and focuses on the local relationships among different dimensional entities. We summarize the score functions of the model based on translation and CNN in Table 1. Reasoning based on the graph, such as R-GCN [19], is an extension of Graph Convolutional Network (GCN) and predicts by convolution operation on the neighborhood of entities. Hybrid reasoning includes DeepPath [20] and MINERVA [21], which use reinforcement learning methods to learn path selection strategies in the multi-step reasoning process of knowledge graphs.
The score functions in previous translation and CNN models. e
i
p
denotes the p-norm of e
i
. denotes a tri-linear dot product. The real part of e
i
denotes Re (e
i
). concat denotes a concatenation operator. f denotes a non-linear function. ∗ denotes a convolution operator. · denotes a dot product. W denotes a set of weight matrixes. Ω denotes a set of filters.
denotes a 2D reshaping of e
i
The score functions in previous translation and CNN models. e
i
p
denotes the p-norm of e
i
. denotes a tri-linear dot product. The real part of e
i
denotes Re (e
i
). concat denotes a concatenation operator. f denotes a non-linear function. ∗ denotes a convolution operator. · denotes a dot product. W denotes a set of weight matrixes. Ω denotes a set of filters.
Recently, some researchers have attempted to incorporate temporal information into KG link prediction. DyRep [6] captures the interaction process between nodes through two simultaneous temporal point process models and combines the attention mechanism to give neighborhood nodes different weights. DySAT [22] obtains the structural and temporal characteristics of entities at each time step and then performs vector addition to obtain the embedding of entities. Besides, some representation learning techniques [23, 24] model temporal information for link prediction. But they cannot effectively capture structural information and predict future events.
Some researches are based on recurrent graph neural models for temporal graph-structured data. EvolveGCN [25] adapts the Graph Convolutional Network (GCN) [26] model along the temporal dimension without resorting to entity embeddings. EvolveGCN captures the temporal feature by using an Recurrent Neural Network (RNN) to evolve the GCN parameters. GCRN [27] aims to learn the structural and temporal features of TKGs through CNN and RNN. GN [28] and RRN [29] update entity embeddings through message-passing at each time step. DDNE [30] uses a Gated Recurrent Unit (GRU) to learn the embedding of entities and obtain the final embedding of entities based on the interaction of neighborhood entities. However, they all ignore the relationship features of graphs and reduce the performance of the model.
Problem definitions and prediction framework
In this section, we will introduce KBGAT-BiLSTM model for link prediction in temporal knowledge graphs. It consists of two parts, Knowledge Base Graph Attention Network (KBGAT) and BiLSTM, as shown in Fig. 2. KBGAT is an attention-based feature embedding method, which can capture the rich semantic information and potential relations inherent in the neighborhood of a given entity. The BiLSTM can effectively capture the temporal characteristics of TKGs. Therefore, our framework can capture structural and temporal features of temporal knowledge graphs for future added or removed links.

KBGAT-BiLSTM is an end-to-end TKG link prediction model. Given a TKG sequence of length N, G t = f (Gt-N, Gt-N+1 ⋯ , Gt-1), feeds the entity matrix H and relation matrix G of each TKG snapshot into KBGAT to learn the structural features of the KG, respectively. In the next step, the entity matrix sequence and the relation matrix sequence of each time step are fed into BiLSTM respectively to obtain the final embedding. Then, the entity matrix and the relation matrix are mapped to the original space through a scoring function, finally the predicted result G t is obtained.
We denote a sequence of length N in temporal knowledge graphs, {Gt-N, Gt-N+1, ⋯ , Gt-1 }. First, we use GAT to capture the structural features of the knowledge graph at each time step to obtain
1: t′ ← t - N
2: While t′ < t
3: Train Gt′ through KBGAT model to obtain
4: Input
5: t′ ← t′ + 1
6: endWhile
7: BiLSTM model outputs G t , and predicts the structure of the network through the score function;
Temporal knowledge graphs
We consider a temporal knowledge graph as a sequence of multi-relational directed graph snapshots, {Gt-N, Gt-N+1, ⋯ , G
t
}, where G
t
= (V, R
t
) represents a directed and unweighted graph at time t. Let V be the set of all entities and R
t
be the temporal relation within the fixed timespan [tk-1, t
k
]. The number of entities is denoted as |V|. The number of relations is denoted as |E|. An event between two entities, namely e
i
and e
j
, is represented by a triplet
In a static knowledge graph, the link prediction problem generally aims to predict the entities or relations by the current KG. It mainly focuses on the structural feature of KGs. Similarly, link prediction in TKG not only needs to capture structural feature, but also needs to capture the temporal feature of KG according to the dynamic evolution processes of previous snapshots, so as to predict the future status of the KG. Our goal is to learn the structural and evolutionary properties of the knowledge graphs.
Link prediction in temporal knowledge graphs
In temporal knowledge graphs, we denote a series of snapshots as {Gt-N, Gt-N+1, ⋯ , Gt-1 }, where N is the number of time steps. The goal of link prediction task is to predict the structure of the next time t, which can be formally described below:
Given an entity in temporal knowldege graphs h ∈ V, we capture the features of entities and relations in a multi-hop neighborhood of the given entity h at each time step. We denote the output representations of the entity h as {h1, h2, ⋯ , h t }, which will be fed into RNN to solve long-term dependencies among the entities. {h1, h2, ⋯ , h t } is defined as neighborhood-based embeddings sequence.
With the defined sequence, the changes of entity embeddings over time can be manifested explicitly. We can infer the hidden structure of entities from the sequence. It is worth mentioning that the history neighborhood of entities can influence the current neighborhood. Meanwhile, the features of relations are easily overlooked, which are an integral part of TKGs. Similarly, We capture the features of relations at each time step. We denote the output representations of the relation as {r1, r2, ⋯ , r t }.
Before introducing the model in detail, we will give some terms and notations that will be used in this section in Table 2.
Terms and notations used in KBGAT-BiLSTM
Terms and notations used in KBGAT-BiLSTM
GAT is an improved model based on Graph Convolutional Network [26], and the attention mechanism is introduced into GCN. GAT solves the shortcoming of obtaining information from neighbors equally in GCN and uses the attention mechanism to assign different weights to neighbor entities. Since the existing link prediction models process triples independently and cannot capture the multi-hop information and potential relations of neighbor entities, Nathani et al. [31] improved GAT and proposed the KBGAT model. First, we calculate the attention coefficient of the neighbor entities. For a particular triplet
where N
i
represents the number of neighborhood of entity e
i
, R
in
represents the number of relations between entities e
i
and e
j
, and α
ijk
represents the attention coefficient of entity e
i
to neighbor entity e
j
under relation k. Figure 3 shows the calculation method of the attention coefficient of the triple. In order to obtain the multiple semantic information of neighborhood, we introduce multi-head attention mechanism to obtain a new entity embedding vector, which is expressed as:

Calculation of attention value between entities.
The new entity and relation embedding matrices and G′ capture the structural feature of the current time step of the KG. Each entity can capture the neighborhood information according to the attention coefficient. After accumulation, it can effectively capture the multi-hop neighborhood information.
RNN is mainly used to process sequential data. As both the training time and the number of network layers increase over time, the problems of gradient disappearance and gradient explosion are prone to occur, which makes it impossible to process longer sequential data. In 1997, Hochreiter and Schmidhuber proposed LSTM network [32], which solved the problem of vanishing and exploding gradient and long-term dependence by improving the hidden structure.
LSTM is not capable of encoding the information back to the front. Sometimes the output at the current moment is not only related to the previous state but also may be related to the future state. The bidirectional LSTM network (BiLSTM) was proposed to solve this problem. The BiLSTM network contains two LSTM networks with opposite directions, as shown in Fig. 4. The embedding sequence of entities and relations is used as input, and the final embedding vector of entities and relations is obtained by extracting temporal features through BiLSTM. Hence, the model can capture the context information of a sequence precisely. The hidden state of LSTM propagating from front to back is denoted as
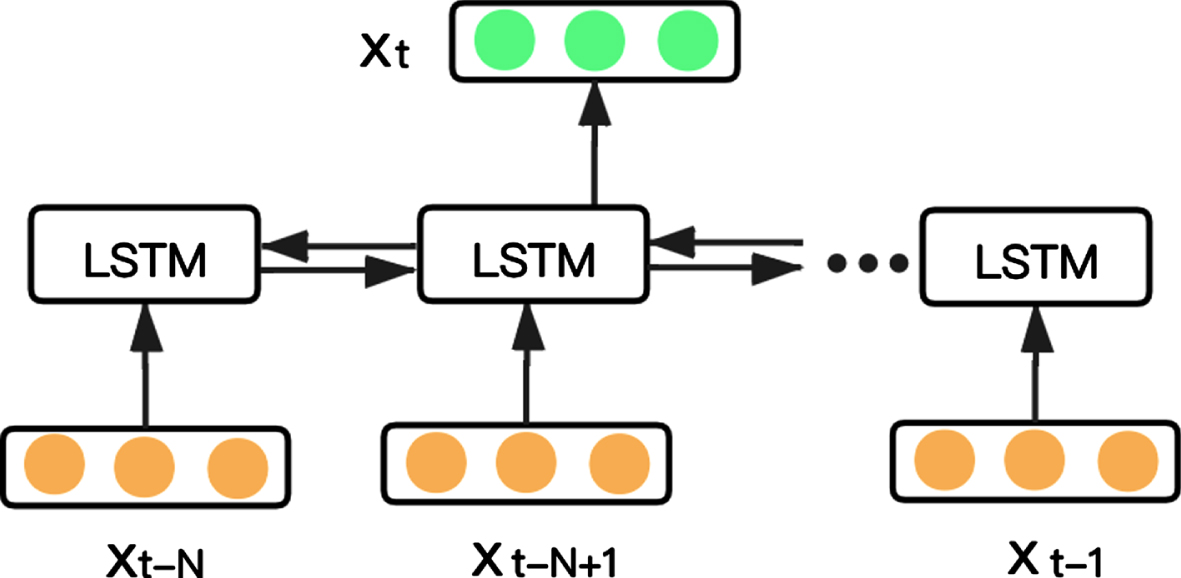
The BiLSTM network consists of two LSTM networks in opposite directions. The input of the network (yellow) represents the embedding sequence of entities and relations, and the output of the network (green) represents the final embedding vector of entities and relations.
Our model borrows the idea of a scoring function from [23], which learns embeddings of given neighbor entities e
i
and e
j
, input their relational sequence {r1, r2⋯ r
k
} into LSTM and obtain the new relation r
seq
. The new relation contains temporal information, which is used to determine the probability that the triple
Datasets
We conduct the comparison of our proposed method with other methods on three real-world TKG datasets, which are widely used for link prediction. The entities in these datasets represent people, places, institutions, etc., and relations representing the connections between entities. The ICEWS18 [33] dataset is event-based temporal knowledge graphs, such as (e
i
, r
k
, e
j
, t), and the WIKI [7] and YAGO [34] datasets have time spans as (e
i
, r
k
, e
j
, [t
s
, t
e
]), where t
s
is the starting time point, and t
e
is the ending time point. In order to facilitate comparative experiments, we converted the format of WIKI and YAGO datasets to the format of ICEWS18 dataset. The details of these datasets are as follows. YAGO: It is a semantic knowledge base that aggregates data from various sources, including Wikipedia. YAGO contains many famous places and people. These places and people naturally contain many attribute values, such as height, weight, age, population size, etc. The YAGO dataset is collected from 2013 to 2017. WIKI: Wikidata originated from Wikipedia. Wikidata is a multilingual encyclopedia knowledge base that can be edited collaboratively. It is expected to extract structured knowledge from Wikipedia, Wikisource, and Wiki guide. There are many different entities in Wikidata Language tags, aliases, expressions, and statements, etc. The WIKI dataset is collected from 2008 to 2017. ICEWS18: The Integrated Crisis Early Warning System(ICEWS) is generated by the BBN ACCENT event encoder, automatically extracting data from news articles and adding temporal information. The data is usually generated once a day. The ICEWS18 dataset is collected from 1/1/2018 to 10/31/2018.
The statistics of three datasets are summarized in Table 3. Before training, we need to preprocess the datasets, remove the repeated quadruples, and sort them in ascending order of each time step.
Dataset statistics
Dataset statistics
Evaluation metrics
In this paper, we use three evaluation methods: Mean Rank (MR), Mean Reciprocal Ranks (MRR) and Hits@1/3/10. When predicting the missing head entity or tail entity of the quadruple, we use the score function to rank all entities to obtain the correct entity’s ranking in the result. We average the rankings of the predicted results, which is MR. MRR is to average the reciprocal of the right entity’s ranking in the predicted results. Hits@1/3/10 is the probability that the correct entity is in the top 1/3/10 of the predicted result. In order to reduce the generalization error, We divide each dataset into three subsets by time step, such as train(80%)/valid(10%)/test(10%). In the relation prediction task, we will remove the head entity or the tail entity to obtain the quadruple (? , r k , e j , t) and (e i , r k , ? , t). Our model will generate two entity sets of length N, which are the prediction results of the head entity and the tail entity, respectively. We can use the above three evaluation metrics to evaluate the results.
Static methods
We compare our model with static methods by ignoring time steps. Static methods includes TransE [11], DistMult [12], R-GCN [19] and ComplEx [13]. R-GCN predicts triplets by convolution operation on the neighborhood of entities. TransE, DistMult and ComplEx are based translational models. Translational models learn the embedding of entities and relations through scoring functions. They usually require fewer parameters and relatively easier to train.
Temporal reasoning methods
To verify the effectiveness of the model, we also compare our model with the state-of-the-art temporal knowledge graph models, which are capable of capturing the structural feature and handling long-term dependencies, including Know-Evolve [5], DyRep [6], HyTE [8], TTransE [35], R-GCRN [36]. The details of these models are as follows.
Temporal knowledge graphs link prediction on MRR and Hits@3/10. Hits@3/10 values are in percentage and the value of MRR times 100. The best score are marked in bold and the second best score is underlined
Temporal knowledge graphs link prediction on MRR and Hits@3/10. Hits@3/10 values are in percentage and the value of MRR times 100. The best score are marked in
Know-Evolve: It uses the temporal point process to model the occurrence of events. The model uses bilinear relation scoring to capture multi-relational interactions between entities and learn dynamic entity representations. It is one of the earliest models for link prediction of TKGs.
DyRep: It is the representation learning of TKGs, which can effectively absorb the information related to the entity events over time, and introduces an attention mechanism to update the weight ratio of the node neighbors continuously, thereby forming a continuously updated embedding.
HyTE: It is a temporally aware KG embedding method that explicitly incorporates temporal in the entity and relation space by associating each time step with a corresponding hyperplane. The model not only performs KG complete using temporal information but also predicts temporal scopes for relational facts with missing time step.
TTransE: It is an extension model of TransE by using temporal information among facts. TTransE is based on Integer Linear Programming (ILP) using temporal consistency information as constraints to incorporate the valid time of facts.
R-GCRN: GCRN [27] combines CNN and RNN to learn spatial structures and temporal features. It is not capable of link prediction for TKGs. Jin et al. [36] modeified the model to work on TKGs by using RGCN instead of CNN.
EvolveGCN: EvolveGCN [25] adapts the GCN to learn entity and relation embeddings. It captures the dynamism of the graph sequence by using RNN to evolve the GCN parameters.
For better comparison experiments, Know-Evolve, DyRep and R-GCRN use the Multi-Layer Perceptron (MLP) decoder proposed by Jin et al. The three models achieve better performance after using the MLP decoder.
Experimental parameters
In this section, We will introduce the parameter settings. In the experiment, we got the best parameters through repeated training. In the knowledge graph training for each time step, we set the vector dimension of entities and relations to 100, without pre-training entities and relations, with a learning rate of 0.001, and set entity embeddings to obtain 2-hop neighborhood information. In the multi-head attention, we use two-head attention. We set the batch size to 128, margin to 5.0 and we utilize the adam optimizer. After obtaining the embeddings of entity and relation at each time step, we use the stacked BiLSTM to get the temporal information, and the stack value is set to 2. In the predictive model, the batch size and margin are different from the KBGAT model, they are 512 and 1.0 respectively, and the momentum of the optimizer is 0.9.
Experimental analysis
We compare the KBGAT-LSTM model with five temporal benchmark models and four static benchmark models on three different datasets. The experimental results demonstrate the effectiveness of our model, especially in YAGO and WIKI datasets. The results of all models are summarized in Table 4. Figure 5 shows the detailed prediction results of our model in different datasets at each time step. Specifically, Fig. 5(a) presents the detailed prediction results of our model in the Yago dataset from 2013 to 2017. Fig. 5(b) demonstrates the precise predictions of our model in the Wiki dataset from 2008 to 2017. Fig. 5(c) presents the detailed prediction results of changes in our model over 33 minutes in the ICEWS18 dataset. Hits@1/3/10 values are in percentage and the value of MRR times 100. The best results are marked in bold. The experimental results of the baseline model are from Jin et al. [36].
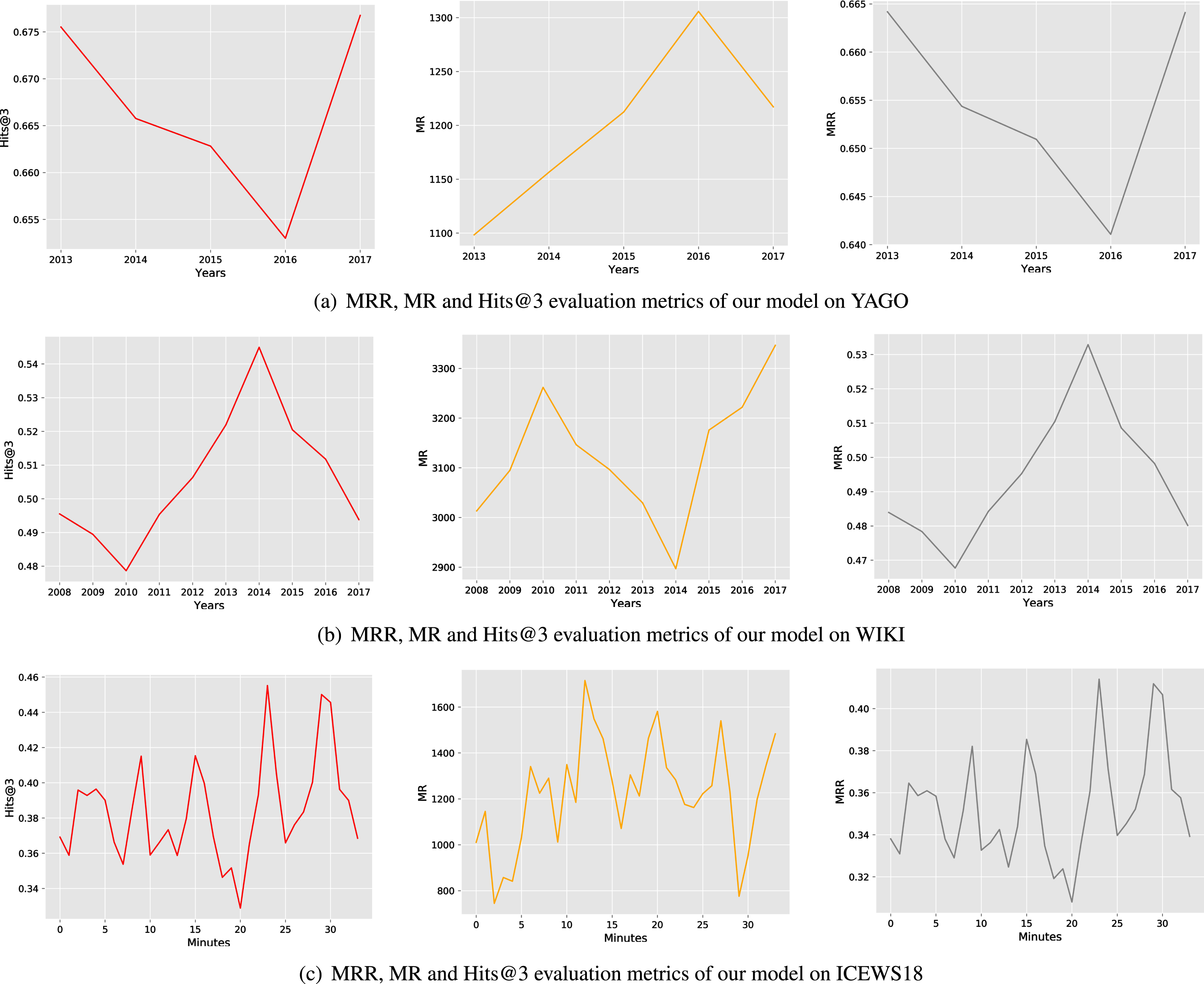
The prediction results of the KBGAT-BiLSTM model at each time step on YAGO, WIKI and ICEWS18 datasets.
We find that the prediction results of these models on the WIKI and YAGO datasets are better than the results on the ICEWS18 dataset. This is due to the characteristics of the datasets themself. The ICEWS18 dataset is event-based and the time granularity is days. Therefore, events of ICEWS18 dataset are real-time. We define it as interactive knowledge graphs. The events of interactive knowledge graphs are repetitive and unstable. They can be interactions that last for a while (phone calls, face-to-face communication, etc.), or they can be discontinuous interactions (emails, text messages, etc.). The events in the WIKI and YAGO datasets are usually long-term and stable, and their time granularity is years. We define them as the relational knowledge graph. Relations of the relational knowledge graph is more stable, such as the relation between friends and colleagues. Therefore, we can appropriately combine the link prediction model of static knowledge graphs with the link prediction of temporal knowledge graphs to achieve better prediction results. For interactive knowledge graphs, it is necessary to focus on the time window or some aggregation to infer future knowledge graphs.
In the MRR evaluation metrics, our model is 4.19 higher than ComplEx on YAGO and 1.48 higher than ComplEx on WIKI. But our model is 0.25 lower than R-GCRN on ICEWS18. In the Hits@3 evaluation metrics, our model is 4.21 higher than TransE on YAGO and 0.42 higher than ComplEx on WIKI. Still, our model is 0.28 lower than R-GCRN. In the Hits@10 evaluation metrics, our model outperforms all competitors in these datasets. Our model focuses on the training of relational embedding and outperforms state-of-the-art models in relational knowledge graph datasets with stable relations. Our model and R-GCRN have achieved similar results in interactive knowledge graphs datasets. The experimental result is also indicating that our model is more suitable for the prediction of relational knowledge graphs.
GCRN aims to study the dynamic pattern of data and researches sequential data such as video through convolution operations on LSTM. R-GCRN introduces RGCN instead of CNN based on GCRN and uses a new decoder. Therefore, R-GCRN shows outstanding performance in interactive knowledge graphs datasets. Know-Evolve and DyRep have achieved better results in the ICEWS18 datasets because they adapt temporal point process to model events that change over time. Know-Evolve and DyRep pay more attention to the learning of the temporal feature of knowledge graphs, which can better capture multi-relational exchange information between entities. HyTE and TTransE focus on the modeling of relations and are suitable for the prediction of relation knowledge graphs.
Since the formation of a network is a complex process and is affected by many factors, it is impossible to design a method to be better than other methods on any datasets. We can conclude that the experimental results of static models and temporal models are quite different on different characters of datasets. Static methods achieve good results in the YAGO and WIKI datasets, but the results of static methods are impoverished in ICEWS18. This is because of the characteristics of the dataset itself. We can conclude that static methods are more stable than temporal reasoning methods by the experimental results. Because previous researchers have done lots of works and achieved better results in the link prediction of static knowledge graphs. The study of temporal reasoning is still in its infancy, and we need to continue to explore.
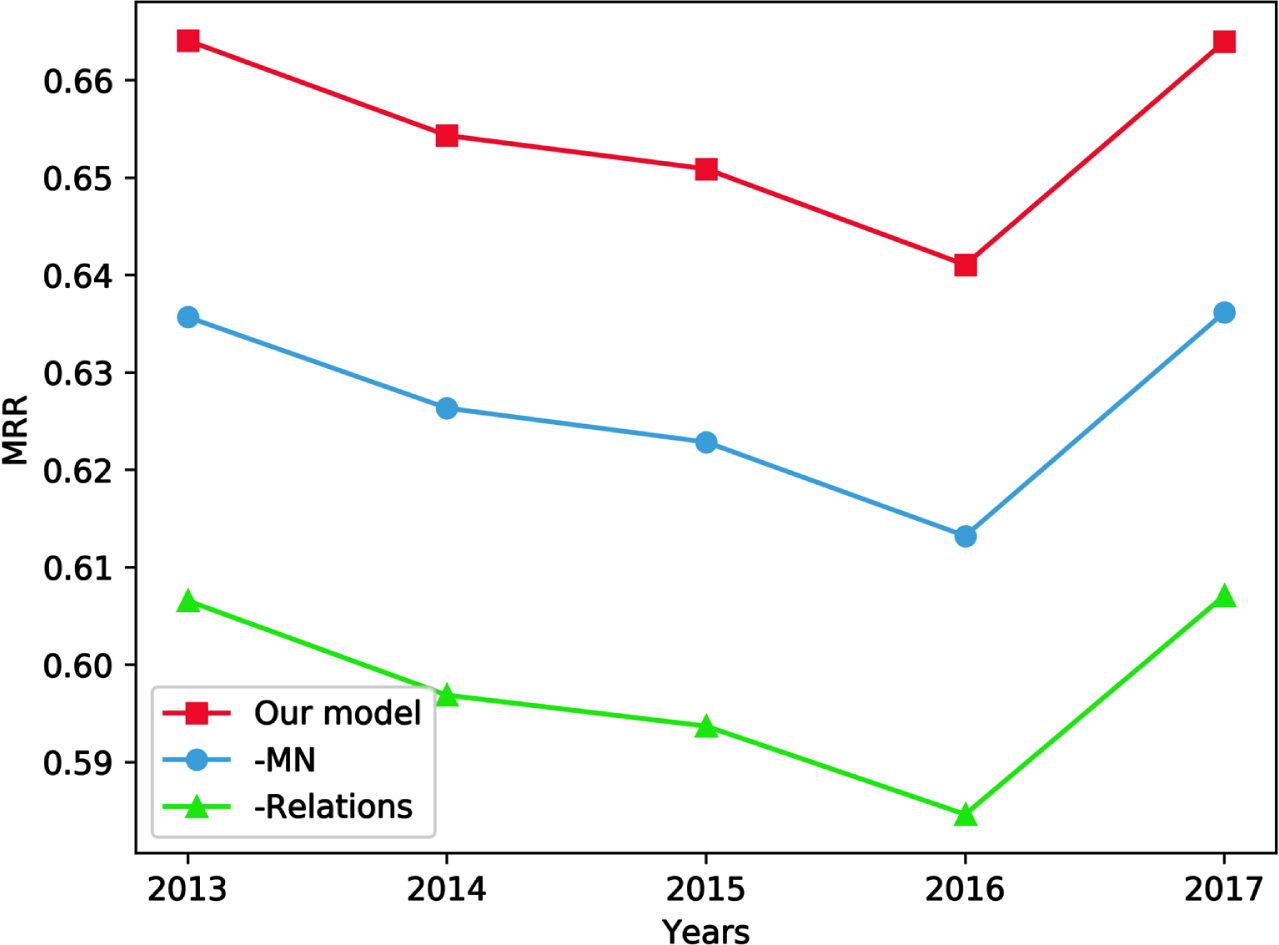
To study the importance of the various components of our model, we performed an ablation study. Specifically, we removed the relational embedding of our model (— Relation) and replaced it with relational embedding without training. We also removed the multi-hop neighborhood (— MN) information of a given node, which means we only get the one-hop neighborhood information of the node. Fig. 6 shows that our model is better than these two ablation models. Removing the relational embedding of our model will have a substantial impact on the performance of the model.
Mean Reciprocal Ranks of our model and two ablated models on YAGO. — MN (blue) represents the model after removing multi-hop neighborhood information. — Relation (green) represents the model without relational information. Our model (red) represents the entire model.
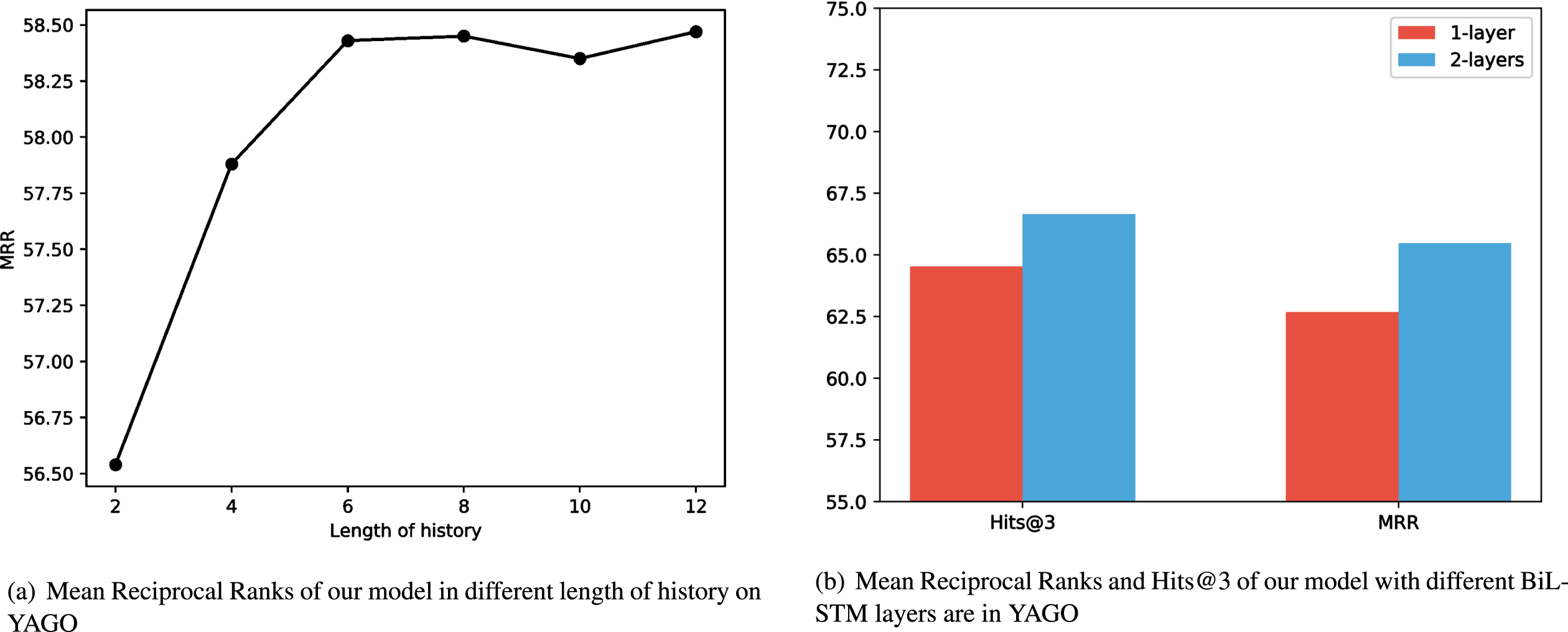
In this section, we study the parameter sensitivity of our model, including the historical length of knowledge graphs and the number of BiLSTM layers. We record the effects of hyperparameter changes on the performance of our model in Fig. 7. Specifically, Fig. 7(a) shows the changes in the prediction results of our model under different historical time steps, and Fig. 7(b) shows the influence of layer number of C on model performance. We will separately introduce their impact on model performance as follows.
Parameter sensitivity of our model on YAGO.
In temporal knowledge graphs, we perform link prediction tasks based on the historical information of knowledge graphs. The longer length of knowledge graphs, the more temporal information can be obtained. Conversely, the shorter length of knowledge graphs, we cannot effectively obtain the temporal features of knowledge graphs, which will lead to worse prediction results. When the length of knowledge graphs reaches a specific value, the effect of link prediction will not be significantly improved, and the computational complexity will increase. Therefore, we need to find a suitable length to predict.
Layers of BiLSTM
We have evaluated the number of layers of BiLSTM to obtain better temporal features. Fig. 7(b) shows that we use 2-layer BiLSTM better than 1-layer BiLSTM because 2-layer BiLSTM can get more temporal information. Therefore, in the experiment, we set the number of layers of BiLSTM to 2.
Conclusions
In this paper, we propose a new deep learning model KBGAT-BiLSTM, which combines the KBGAT and BiLSTM models. KBGAT encapsulates both the rich semantic information and potential relations of entities to learns the structural feature of knowledge graphs. BiLSTM captures the temporal feature of knowledge graphs by learning the embedding sequence of entities and relations. Besides, we are the first to apply GAT to temporal knowledge graphs. Our model captures the neighborhood information of entities effectively by continually updating the attention value. The results show the effectiveness of our model and achieve state-of-the-art performance.
The network structure of knowledge graph is complex and is affected by many factors in the process of change. Therefore, it is difficult to propose a model that can show good performance on different characters of datasets. We worked to advance the progress of this research. In the future, we will work to reduce the complexity of the KBGAT-BiLSTM model and make it suitable for link prediction of large-scale knowledge graphs. Additionally, we will study the transferability of our model to make it suitable for tasks such as dynamic networks and node classification.
Footnotes
Acknowledgments
This research is funded by the Key Program of Tianjin Natural Science Foundation (19JCZDJC40000), Science and Technology Program of Tianjin (18YFCZZC00060, 18ZXZNGX00100) and Natural Science Foundation of Hebei Province (F2020202008).