
Abstract
Machine translation (MT) is an important challenge in the fields of Computational Linguistics. In this study, we conducted neural machine translation (NMT) experiments on two different architectures. First, Sequence to Sequence (Seq2Seq) architecture along with a variation that utilizes attention mechanism is performed on translation task. Second, an architecture that is fully based on the self-attention mechanism, namely Transformer, is employed to perform a comprehensive comparison. Besides, the contribution of employing Byte Pair Encoding (BPE) and Gumbel Softmax distributions are examined for both architectures. The experiments are conducted on two different datasets: TED Talks that is one of the popular benchmark datasets for NMT especially among morphologically rich languages like Turkish and WMT18 News dataset that is provided by The Third Conference on Machine Translation (WMT) for shared tasks on various aspects of machine translation. The evaluation of Turkish-to-English translations’ results demonstrate that the Transformer model with combination of BPE and Gumbel Softmax achieved 22.4 BLEU score on TED Talks and 38.7 BLUE score on WMT18 News dataset. The empirical results support that using Gumbel Softmax distribution improves the quality of translations for both architectures.
Introduction
Machine Translation (MT), which is the sub-field of Computational Linguistics, is regarded as an effective method to translate source language into target language. The pioneering work on MT was published by Weaver et al. [28] and the topic has witnessed a wide-spread development together with the rapid technological advances of the last decades.
Studies based on MT can be roughly classified into three groups: rule-based, statistical and neural methods. While rule-based machine translation (RMT) uses handcrafted rules to translate the language from source S to target T, statistical machine translation (SMT) utilizes probabilistic models and makes estimation from parallel corpora. The aim of traditional SMT is to search for the most probable translation
In recent years, deep neural networks have been found to be attractive in different fields of applications. Neural machine translation (NMT) based on neural networks was inspired by the increased usage of deep learning architectures. NMT models have been recently proposed by [5, 26] and showed promising results by enhancing state-of-the-art translation performance. Unlike the traditional SMT [16], most NMT models do not require linguistic knowledge such as syntactical or semantic features, do not consist of many small sub-components and utilize neural network to learn the model jointly to maximize the translation performance. Neural network architectures, especially the encoder-decoder structures, have recently been used in MT as well as in other applications and showed promising results. While an encoder encodes the input sentence into a fixed-sized vector, a decoder maps the vector representation to a sentence in the target language.
Agglutinative languages, like Turkish, are cumbersome for Computational Linguistics since they comprise morphologically complex words due to the morpheme agglutination. For example, in order to form the present tense of the word “öğrenmek”, which stands for “to learn”, a morpheme “-yor” is added along with varying suffixes of the subject. In consequence, corresponding translation of “I’m learning” becomes “öğreniyorum”. As the example indicates that the morphology of the words changes regarding not to sense but the context of the word, thus it is required to contain different forms of the words in order to efficiently represent them in the vocabulary. Therefore, collecting resources and applications for the agglutinative languages are difficult and computationally heavy.
This study serves for literature of morphologically rich and low resourced languages, including Turkish, by comprehensively comparing two main architectures of NMT: Sequence to Sequence (Seq2Seq) [25] and Transformer [26]. The contribution of this study is to examine Byte Pair Encoding (BPE) for morphemes tokenization and the Gumbel Softmax distribution for providing fluency on morpheme selection to models during training. Although, the Gumbel Softmax distributions were studied by Gu et al. [10] for the inference model, the effects on training have not been examined before, to the best of our knowledge. In our empirical studies, it is concluded that training models with Gumbel Softmax distribution is fairly successful to improve the results.
The rest of the paper is organized as follows. Section 2 introduces the related works conducted on Turkish-English machine translation along with NMT studies. Section 3 describes the dataset, architectures and methodology used in this study. Section 4 provides details about the parameters utilized in the experiments. Section 5 presents the results of the experiments. Section 6 overviews the experiments. Lastly, the conclusion is drawn in Section 7
Related works
A novel approach to NMT started with the adaptation of neural language models to traditional SMT systems [22]. The studies [23, 27] trained neural networks for scoring phrase pairs using different representations as an additional input. In the study of Schwenk [23], continuous space translation model probabilities of a phrase-based SMT system were used. Feedforward neural networks were employed and the model predicted an entire target phrase, rather than a word at a time. A similar study [7] proposed a model that uses a feedforward neural network for translation model which predicts one word in a target phrase at a time. Other similar studies [4, 9] utilized a feedforward neural network that accepts a bag-of-words representation for input phrase. Kalchbrenner et al. [15] proposed a different approach, where a convolutional n-gram model is used for encoder and hybrid of inverse convolutional n-gram model and RNNs are used for decoder. A similar study [5] proposed a RNN encoder-decoder architecture that uses two RNN structures. The one behaves as an encoder to map a variable length sequence to fixed-length vector. Another acts as a decoder to map vector representation to variable-length target sequence. A closely related study [25] employed Long Short-Term Memory (LSTM) [12] in both encoder and decoder networks to address vanishing gradient problems. Exploiting encoder-decoder framework, Vaswani et al. [26] developed another architecture, namely Transformer, that replaces the conventional RNNs with self-attention mechanisms to perform language translations. The inference method which decodes the predictions of the models to generate the translations is another important and challenging subject in the NMT field. Sutskever et al. [25] used beam-search decoder that selects the one with the highest probability from sequence of candidates regards to beam size. Moreover, Gu et al. [10] proposed to use Gumbel Softmax distributions for the inference model. This study inspired us to question the effect of Gumbel Softmax distributions on model training in order to teach robust utilization of morphemes to the models rather than the inference.
In Turkish, the study [1] addressed the lack of sufficient vocabulary problem on morphologically rich languages. Ataman et al. [1] proposed a vocabulary reduction methodology that encodes the suffixes. They showed that the impact of stem on model learning increases and the proposed model achieves better performance in open vocabulary translation of morphologically rich languages. Their research was also conducted on TED Talks dataset [20] by Seq2Seq model with attention. Curry et al. [6] also addressed the low resource problem for specific languages such as Turkish, and proposed to address the insufficient data problem for NMT by feeding the models with copied corpus that source and target language is switched in addition to original dataset. Another study conducted by Gülçehre et al. [11] on improving the NMT models, employs two alternative language models, named shallow and deep fusion, and augmented decoder corresponding to these language models. The resulting deep fusion language modelling was successful in improving the state-of-the-art score in Turkish-English translations. The study [19] developed strategies on the low-resource and morphologically-rich languages of Turkish and Uyghur. The results showed that method for morphologically motivated word segmentation is better for NMT and prominent advancement on Turkish-English and Uyghur-Chinese machine translations. Other studies [17, 30] also used multilingual neural machine translation considering Turkish language based on WMT17 and WMT18 News datasets.
Experimental setup
Dataset
The morphologically rich languages, such as agglutinative languages like Turkish, suffer from a lack of resource problem to train neural network architectures due to the required vocabulary and corpus sizes. TED Talks, that is compiled by Qi et al. [20], become a benchmark dataset especially among the morphologically rich language for NMT. The dataset contains sentence pairs in 60 different languages taken from TED Talks transcripts. Another dataset in this domain, namely WMT18, is provided by the shared task of the Third Conference of Machine Translation [3]. We used the WMT18 News corpus that contains texts from published news articles. In this study, we selected Turkish-English pairs to apply Turkish-to-English NMT. The reason why we select from Turkish to English translation, rather than English-to-Turkish, is to compare the results of our models with the studies conducted on exclusively on the selected dataset for this particular direction.
In our qualitative observations of the selected datasets, we noticed that the translation pairs have an even distribution of complex and simple sentences in the TED Talks dataset while having more complex sentences in the WMT18 News dataset. Intuitively, the mixture of complex and simple sentences is required to develop a robust translation system, since it stresses the models to learn complicated sentence fragmentation while acquiring the basics of the language by simple sentences. Similarly, another requirement for training a robust translation model is diversity on word stems. Although most of the datasets for morphologically rich languages suffer from low diversity of stems due to agglutination operation, an adequate variety of stems is maintained in both datasets. The quantitative summaries of the selected datasets are given in Tables 2.
The summary of the TED Talks dataset
The summary of the TED Talks dataset
The summary of the WMT18 News dataset
The morphologically complex words increase the vocabulary size due to the morpheme agglutination described in Section 1, resulting in that more computational power is required. To address this problem, Sennrich et al. [24] proposed to utilize Byte Pair Encoding (BPE) algorithm for word segmentation on NMT tasks. Instead of using one token to represent a word, BPE segments the complex word into the subword units. Thus less storage is required to constitute the vocabulary while covering more complex words in the language.
In order to apply BPE, the most frequent pairs of characters on corpus are obtained to determine the subword unit vocabulary. The subword units are merged until the specified target vocabulary size is satisfied. Because the words are segmented as subword units, this approach also alleviates the out of vocabulary (OOV) problem by generating or understanding fragments of the words that are not in training vocabulary. Therefore, BPE is a notable approach for low resource corpora, especially in morphologically rich languages.
Architectures
The latest studies on NMT are built upon Recurrent Neural Networks (RNN) [5]. However, a novel approach disuses RNN and exploits self-attention mechanisms, namely Transformer [26], became popular as well as RNNs after the success of Transformer variations, e.g. BERT [8] GPT-2 [21] on language modelling. Regardless of differences on architectures, the goal is to estimate the conditional probability P = P (y1, y2, . . . , y n |x1, x2, . . . , x m ), where x = (x1, x2, . . . , x m ) is the given sentence and y = (y1, y2, . . . , y n ) is the output sentence which its length may differ from given sentence.
Sequence-to-Sequence (Seq2Seq)
Sutskever et al. [25] proposed Sequence-to-Sequence (Seq2Seq) architecture comprise two networks fully based on RNN. The first RNN, namely encoder, learns to encode a sequence of input sentence to a fixed-length vector and the second RNN, namely decoder, maps the fixed-length vector representation into a sequence of the target language.
The encoder network reads the input sentence x sequentially, and forms the T length of hidden state vector h = (h1, h2, . . . , h
T
) for each time step t:
In practice, RNNs often suffer from the vanishing gradient problems while learning long-range dependencies [13]. The variants of RNN such as Long-Short Term Memory (LSTM) [12] and Gated Recurrent Unit (GRU) [5] are proposed to tackle this problem by allowing to forget the hidden states if necessary. The notable difference between LSTM and GRU is the number of gates, consequently requirement of computational power. In this study, we preferred to use GRU due to computational limitations.
Besides above mentioned pure Seq2Seq architecture, another model that is fully based on Seq2Seq but exploits an extra layer, namely Attention, is employed to expand our comparison on the task. The attention layer extension that is introduced by Bahdanau et al. [2] provides soft-search mechanism for decoder network by conditioning the significance of input sequence values. In order to obtain attention, the context vector γ computed as:
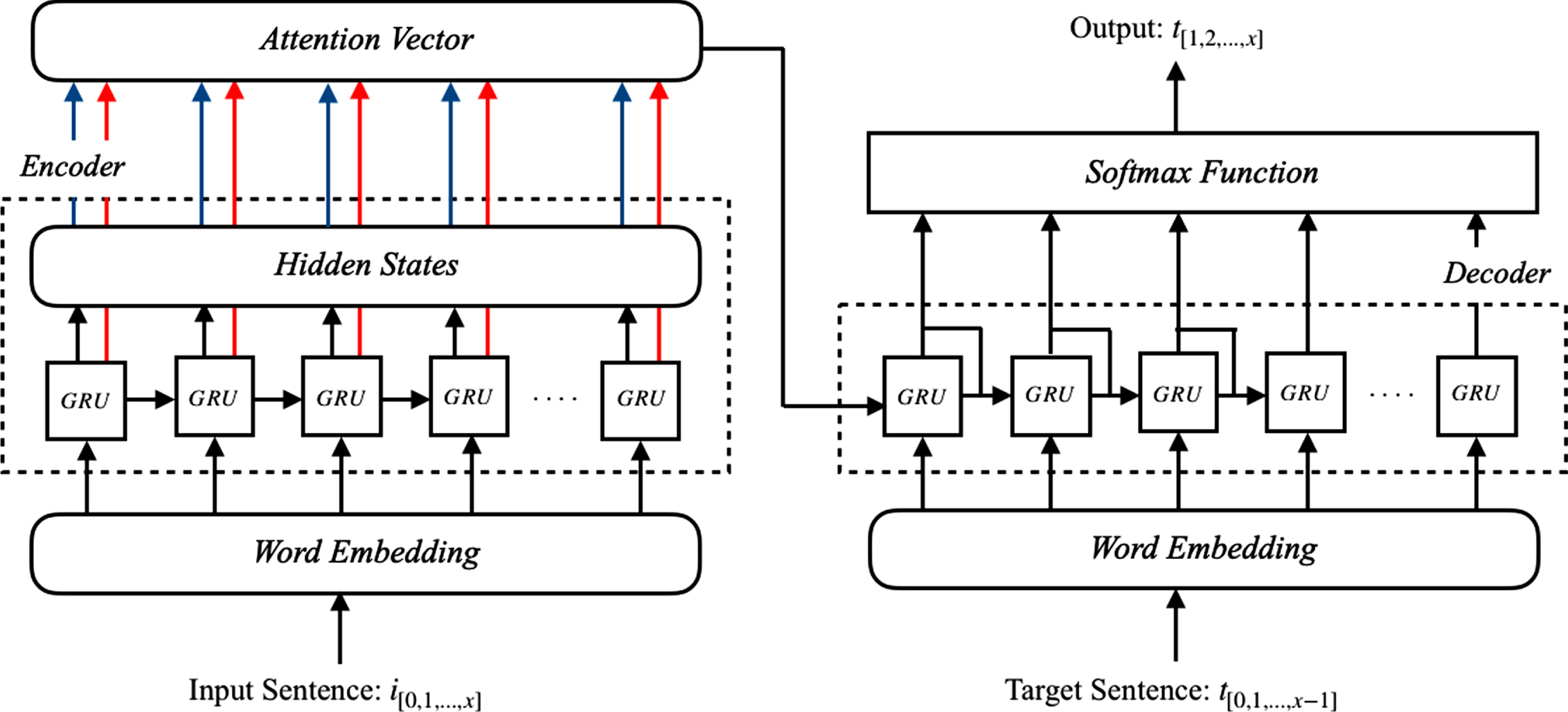
The representation of Seq2Seq with Attention layer.
The Seq2Seq architecture exploits LSTMs or GRUs in order to overcome the vanishing gradient problem in sequences. However, the novel study on self-attention mechanism proved to be successful in compensating for the gradient in longer dependencies [26]. The transformer model benefits from multi-head attention instead of LSTM or GRU. The rest of the framework is a traditional encoder-decoder architecture, except that the decoder network has an extra attention layer which combines encoder and decoder output by another n-stacked multi-head attention layer to pass the estimation to a fully-connected network with softmax activation function in order to predict the tokens in the target language.
Disusing RNNs causes vanishing on sequential information of sentence tokens. The transformer model uses Position-Encodings to determine the position of the tokens. By combining Position-Encoding with the embedding vectors, the sequentiality is acquired as in RNN structures. Position-Encoding consists of sine and cosine functions with given position as pos and dimension i:
The obtained vector that has sequential information between the tokens then is fed to a multi-head attention layer. The multi-head attention layer is constructed by query (Q), key (K) and value (V) matrices to present the linear projections of Q, K and V. The input contains queries and keys of dimension d k . The matrices refer to one head and are concatenated in order to form the multi-head attention layer.
where d k , K T and W O refers to dimension of keys, transpose of K and output weight matrices, respectively.
The main architecture of Transformer shares the pattern of the encoding and decoding mechanism same as Seq2Seq models. The encoder of the Transformer contains n-stacked multi-head attention (MHA) layer that is fed by a position-wise feedforward network then passes through the decoder, likewise the hidden state passing in Seq2Seq models. However, the decoder differs from the one used in Seq2Seq models since it consists of two sub-sections, a decoder MHA layer and an encoder-decoder MHA layer. The decoder MHA layer connects with a position-wise feedforward network same as the encoder. Further, these two layers link to another MHA layer that combines the information for both input and target sentences before the softmax layer. The basic representation of Transformer model can be seen in Fig. 2.
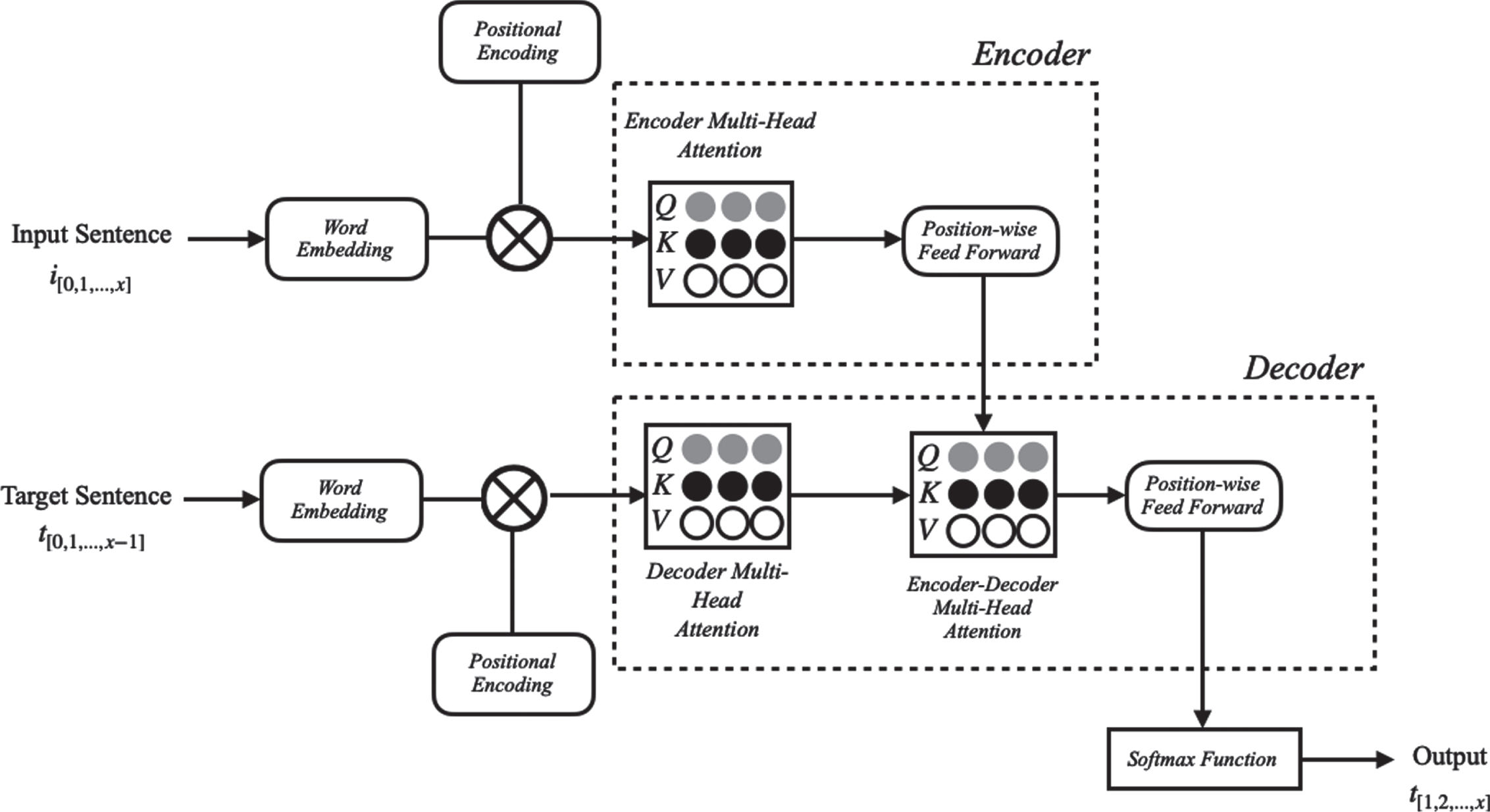
The representation of Transformer model.
A fully connected network with a softmax activation function is used for both architectures to select the tokens for the output sequence from the probability distribution which the decoder network predicted. In our experiments, we alternatively trained our models by using Gumbel distributions [14] on the softmax function.
Gumbel Softmax [14] function creates new categorical distribution corresponding to a tunable temperature parameter τ from the probability distributions of the output. Softmax function that selects the token at timestep yt+1 with respect to Gumbel distributions is calculated as:
In this study, we employed Seq2Seq and Transformer architectures on Turkish-to-English translation task. Besides, an Attention layer is utilized on the Seq2Seq architecture. In our experiments, Gumble softmax function and BPE are performed for each architecture. Consequently, we trained 12 models without using any pre-trained weights. The trained models and corresponding results on test datasets are given in Tables 4.
BLEU scores for the translations on TED Talks test dataset
BLEU scores for the translations on TED Talks test dataset
BLEU scores for the translations on WMT18 News test dataset
In the evaluation of the trained models, teacher-forcing [29] is selected for decoding strategy of inference model that generates translation for the given sentences. The teacher-forcing algorithm evaluates the next output by supplying with the token that is generated one step before. The algorithm exploits the maximum likelihood principle:
In our experiments that are conducted without Byte Pair Encoding (BPE), we had to reduce the size of the unique tokens because of computational resource limitations. We selected the most used 40K tokens for both languages from training dataset to create language vocabularies. All out of vocabulary tokens were removed from sentences. In the experiments with BPE, we selected the subword vocabulary size to be 8K. Although Seq2Seq models require less computational power than the Transformer, the size of vocabularies was left constant to eliminate the effect of vocabulary size and achieve a fair comparison between architectures.
The Seq2Seq models are employed GRU unit size of 1024 for each layer, encoder and decoder. RMSProp optimizer is used for optimizing the sparse categorical crossentropy loss function. Bahdanau attention layer [2] with unit size of 1024 is added on top of the pure architecture.
The Transformer models are trained with the number of layers to be 2, the dimension of the model to be 128, the dimension of the position-wise feed forward network to be 512, the dropout rate to be 0.1 and the number of attention heads to be 4. The activation of fully connected point-wise feedforward layer is chosen to be ReLU.
For both architectures, the maximum length of sentences are limited to be 50 due to computational limitations. The embedding dimension is selected to be 256. We did not use any pre-trained word embedding. The Gumbel softmax temperature τ is chosen to be 0.5 for TED Talks dataset and 0.25 for WMT18 News dataset. Training of models is conducted with batch size 64. Our implementation is independent of the languages that are translated. The models, therefore, can be trainable to perform different language translations as dataset is supplied. 1
In this study, we trained 12 different models based on the abovementioned architectures. Each trained model employed to make Turkish-to-English translations on TED Talks and WMT18 News datasets. The BLEU metric is used for evaluating the models. The quantitative results are given in Tables 4.
In our empirical study on TED Talks dataset, we observed that Transformer with combination of BPE and Gumbel Softmax outperforms other models with 22.4 BLEU score. Besides, Table 3 indicates that using Gumbel Softmax distributions during training is demonstrated a significant effect on contributing results in all experiments. Although using BPE reduces the quality of translation in most of the experiments, the combination of BPE and Gumbel Softmax improves the results except pure Seq2Seq architecture. Also, the study conducted by Qi et al. [20] is given in Table 3 to provide a comparison. They employed the Seq2Seq architecture with an attention mechanism to perform Turkish-to-English translation on TED Talks dataset and reported that their model is achieved 14.9 BLEU score, however, the score is increased to 17.9 by using pre-training word embedding for both languages.
As the results shown in Table 4, the experiments conducted on the WMT18 News dataset are in line with the results achieved on TED Talks. That is, the Transformer architecture achieved the best results with a 38.7 BLEU score by combining BPE and Gumbel softmax functions in addition to outperforming Seq2Seq models overall. In previous studies on the WMT18 News dataset, Yang et al. [30] proposed to train the Transformer model in multilingual modality, i.e. training the languages simultaneously and updating the network based on the proposed agreement function. A similar study conducted by Lin et al. [17] employed the Transformer architecture to learn the tokens randomly replaced with one from another language.
For qualitative analysis, an example taken from TED Talks test dataset and the translation outputs of the models are given in Table 5. As the table indicates, the translation closest to ground-truth is achieved by Transformer with combination of BPE and Gumbel Softmax. Although BLEU score of pure Seq2Seq model with combination of BPE and Gumbel is not the highest, the translation in given example demonstrates two notable feature: (i) using ’that’ as object of the verb, (ii) using auxiliary verbs with apostrophes.
Translation results on an example sentence that is taken from TED Talks test dataset
Translation results on an example sentence that is taken from TED Talks test dataset
(i) Learning to use ’that’ word as an object for the verb is an important achievement because it requires decent quality of language modelling. Further, (ii) using apostrophes is another notable feature because the word “yapıyoruz” is unique although the corresponding translation is “we’re doing” which comprises 4 tokens including apostrophe, therefore, it requires robust understanding between the agglutinative language and English.
Agglutinative languages, such as Turkish, are one of the most difficult language types for the studies of Computational Linguistics. The main characteristic of agglutinative languages allows changing the meaning of words by adding different unions of morphemes, resulting in that these languages own a vast amount of unique word vocabulary enriched by morphemes, so huge dataset even may not cover substantial words. Therefore, the resources of the morphologically rich languages are limited.
Due to the computational limitations, we were forced to apply reduction on vocabulary sizes and sentence lengths on training dataset. In fact for general-purpose translation systems, these reductions are not tolerable and the models require extensive data. However, we aim to provide a comprehensive analysis of the configurations and architectures for training models in this study. Therefore, we prioritized the eligibility of the comparative experiments rather than attempting state-of-the-art results.
Intuitively, the reduction on vocabulary sizes, although the vocabulary is selected from the most used tokens, causes out-of-vocabulary (OOV) issue. Sutskever et al. [18] also addressed this problem, and improved the quality of the translation with post-process replacement done by positional unknown model that learns the behaviour of the unknown words in sentences. However, we left the investigation of the effect of such OOV models on morphologically rich languages for future works.
After our empirical results, we concluded that self-attention mechanism is more suitable for Turkish-to-English NMT task rather than traditional gated RNN structures like LSTM and GRU. We observed that although using BPE improves the results for Transformer architecture, the combination of BPE and Seq2Seq architecture fails to contribute the results. Our experimental results also indicate that usage of Attention layer on Seq2Seq architecture without Gumbel Softmax decreases the quality on this task.
Gumbel Softmax function balances the distribution of the outputs with respect to temperature parameter. Training with more evenly distributed probabilities of predictions provides output regularization for the models, consequently that the models are penalized to learn for making more robust predictions. Overall, we observed that the results of the models are improved when Gumbel Softmax distributions are used. Therefore, we concluded that Gumbel Softmax function has a strong effect on improving the scores. However, it must be noted that the temperature has a substantial influence on the performance, thus it should be optimized with considerable caution. Although training the network with Gumbel Softmax functions is independent of the languages that are translated, our observations depend on a morphologically rich language. Investigating the effects of using Gumbel Softmax for the other types of language is subject of future works. In the light of our observations, we suppose that using Gumbel Softmax distributions with BPE may improve the quality of the translations for the languages containing a high density of compound words like German.
Moreover, we analyzed the correlation of sentence lengths and the performances of the trained models to assess the efficiency of the models on different types of sentence translations. Figures 4 show the performance of the best three models from different architectures respectively on TED Talks and WMT18 News test dataset with respect to the lengths of the input sentences. The figures depict the sentences which its length is between 3 and 65 because the rest of the sentences are rare in the test set. In TED Talks experiments as shown in Fig. 3(b), the Transformer with BPE and Gumbel Softmax outperforms the other models on the sentences whose lengths are between 5-25 range, however, the performance of the model drops drastically as the length of the sequences increases. Although the Seq2Seq architectures significantly surpass the Transformer architecture on 25+ length sentences, the sentences in this region are scarce. Therefore, the overall results of the Transformer model are substantially better compared to others. In WMT18 News experiments as given in Fig. 4(b), the performance of the Transformer with BPE and Gumbel Softmax universally surpasses the other models. Consequently, this confirms the effectiveness of the proposed model in complex and simple sentence combinations.

Performance of the best three models on TED Talks test dataset with respect to length.
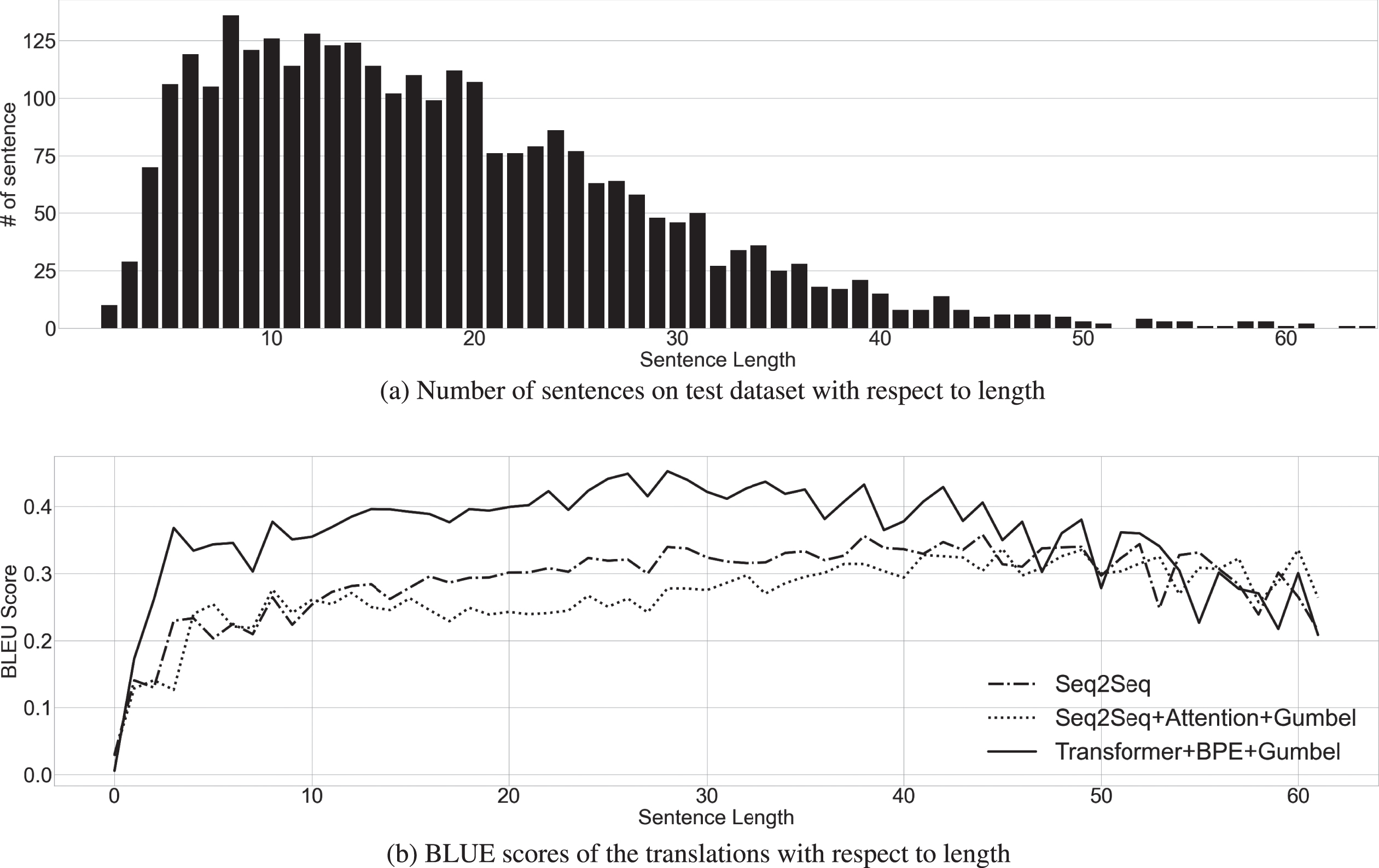
Performance of the best three models on WMT18 News test dataset with respect to length.
In this study, two main NMT architectures, i.e. Seq2Seq and Transformer, were employed to address the Turkish-to-English translation task. An attention mechanism in Seq2Seq architecture was also utilized to extend the capabilities of the architecture. Besides, BPE and Gumbel Softmax function were examined for each model. Although using BPE is intuitively convenient to approach for agglutinative languages, the empirical results showed that it could not to contribute the results on translation task in overall. On the contrary, Gumbel Softmax function was concluded to be effective in improving results. In our experiments, Transformer model with combination of BPE and Gumbel Softmax achieved the highest quality with 22.4 BLEU score on TED Talks dataset and 38.7 BLEU score on WMT18 dataset.
In conclusion, we conducted comprehensively comparison on NMT architectures for Turkish which is one of the morphologically rich language due to the agglutination. In our experiments, we concluded that Transformer architecture outperforms Seq2Seq. In addition, we found that using Gumbel Softmax distributions on model training substantially contributes to results. We will devote our future work to investigating the decoding strategy of inference model and OOV token problems on morphologically rich languages.