
Abstract
Deep learning has gained popularity across several industries, including object recognition and classification. In the case of Convolutional Neural Networks (CNN), the first layers extract the most noticeable elements, such as shape and margin. As the model progresses, it learns to extract more complex features such as texture and color; conversely, skeleton features encompass significant locations (joints) that do not naturally align with the grid-like architecture intended for these networks. This study emphasizes the importance of structural features in enhancing the performance of deep learning models. It introduces the Gesture Analysis Module Network (GAMNet), which computes abstract structural values within the architecture for feature extraction, prioritization, and classification. These values go through a rigorous evaluation process along with the cutting-edge deep learning model, CNN, and result in intermediate representations, leading to better performance in gesture analysis. An automated dance gesture identification system can address the challenges of recognizing hand movements in unpredictable lighting, varied backgrounds, noise, and changing camera angles. Despite these challenges, GAMNet performed remarkably well, surpassing renowned models like VGGNet, ResNet, EfficientNet, and CNN, achieving a classification accuracy of 96.80%, even in challenging image circumstances. This paper highlights how GAMNet can revolutionize the world of classical Indian dance, opening up new opportunities for research and development in this field.
Keywords
Introduction
Machine Learning (ML) techniques have significantly transformed diverse domains, including social networking, cognitive science, speech processing, and computer vision, propelling technological advancements to unprecedented levels. Within these realms, deep learning has emerged as a crucial tool for informed decision-making. An essential aspect of many applications involves analyzing the structural characteristics relevant to object recognition and classification. The development of an ML system for tasks such as object detection or classification mandates a comprehensive understanding of processes encompassing image acquisition, enhancement, preprocessing, segmentation, pattern recognition, and algorithms. Achieving high accuracy in these systems hinges on meticulous feature extraction and selection, tailored to the characteristics of the input images [1].
The architectural frameworks of deep learning models seamlessly integrate these image-processing and classification tasks. Effective performance of these models relies on large training datasets, utilizing texture, color, and structural data to generate feature representations for object detection and classification. These representations serve as the foundation for precisely locating and categorizing items, enabling the models to excel in challenging real-world scenarios characterized by diverse visual traits. The success of deep learning models in object recognition and classification hinges on the automatic extraction and utilization of texture, color, and structural characteristics, with each model exhibiting specific advantages in handling these features [2].
Two prominent types of deep learning models designed to operate on grid or sequence data are Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). CNNs, especially effective in image retrieval, detection, and classification, employ advanced layering systems with non-linear functions and transformations. However, these models may struggle when processing non-grid data, such as skeletal features represented as a sequence of joint locations across time. Skeletal data, lacking standardized representation formats, poses challenges in creating a universal deep-learning model due to variations in data formats from different sensors or capturing devices. While RNNs or LSTMs (Long Short-Term Memory Networks) can analyze sequences, managing temporal data efficiently can prove more challenging than dealing with static data [3].
Recognizing the need for accommodating skeletal data, researchers have explored specialized deep-learning techniques and architectures. Models like Graph Convolutional Networks (GCNs) and Spatial-Temporal Graph Convolutional Networks (ST-GCNs) specifically analyze graph-structured data, such as skeletons, excluding considerations of texture or color [4].
Deep learning algorithms, though potent and versatile, were initially tailored for specific data types, necessitating specialized architectures and preprocessing methods to extract pertinent information for tasks involving skeletal data. To leverage the advantages of deep learning in gesture and pose recognition tasks, ongoing research focuses on adapting existing models to accommodate these unique requirements.
The CNN architecture encompasses components such as the classifier, convolution layer, pooling layer, and fully connected layer. Lower-order convolution kernels prioritize local perception, extracting features like edges and corners, while higher-order convolutions, facilitated by receptive fields, transition from local to global features. While CNNs excel in extracting features from raw image data, they are not inherently designed to capture skeletal information. Skeleton features, representing the underlying structure of objects, typically involve key points or joints and spatial relationships, necessitating distinct approaches such as pose estimation models or skeleton tracking systems.
Previous studies, including [2], have extensively explored deep CNNs, chiefly in the realm of CNN taxonomy based on acceleration methods. Recognizing the limitations of CNN and other deep learning techniques, this paper is motivated to propose a system with specific objectives: Preservation of structural features of an object, invariant to translation, rotation, and scaling. Representation of spatial relationships between objects through the maintenance of key points or joints. Enhancement of the performance of state-of-the-art systems.
In pursuit of these objectives, we present the proposed system, outlining its key components: Prioritizing CNN features by incorporating intricate relationships and patterns in the data. Extraction of structural skeleton features, concatenated with CNN features for classification. Evaluation of the system’s performance through implementation in hand gesture classification.
The subsequent section provides a detailed exploration of Indian classical dance forms and gesture analysis.
Dance is the mother of all arts, the artist and the creation, the creator and the work, remain intertwined as a singular entity. Through rhythmic movements, an innate grasp of spatial dynamics, and vibrant portrayal of both the observed and the envisioned, humanity forges these elements within their bodies through dance. It’s a prelude to using substance, stone, and language to externalize their inner journey.
Mudra, derived from Sanskrit, signifies that which gives ultimate joy. It’s been integral to India’s rich heritage since ancient Vedic times. Mudra’s significance transcends rituals, as it finds its place in dance, drama, and practical knowledge. Across the globe, practitioners of Indian dance, yoga, and studies are deeply intrigued by mudras. Dancers, in particular, display a profound curiosity. During the Vedic era, priests and religious leaders crafted mudras for offerings during sacrificial rites, employing them as a vital element of worship during mantra recitations.
Mudras, as per the traditional Natyashastra, were utilized to convey even the most intimate emotions. Gesture or mudra is revered as the essence of Indian classical dance [5]. According to the Natyashastra, experts are advised to harmonize mudras with established customs, considering factors like movement, intent, context, quantity, suitability, and manner (Bharata 1995). The hand’s palm serves as the epicenter of expression. Classical dance is marked by various finger positions displayed through the palm, while the wrist acts as the axis for hand movements in all directions. The language of mudra is rooted in the 24 mudras outlined in the Natyashastra and 28 in the Abhinaya Darpana. Unilateral gestures are termed asamyukta, while bilateral ones involve both hands, known as samyukta. Each mudra is meticulously detailed in these texts, specifying how fingers should extend, part, or bend to form a distinct mudra. It’s essential to note that “hastavedah” is synonymous with mudra in this context.
From the era of Bharata Muni to the modern day, theoreticians, scholars, critics, and artists have consistently characterized mudras as the very language of dance. This assertion, succinctly captured in the statement “mudra is the language of dance,” has been affirmed by commentators such as Nrityabaridhi Bela Arnab (1992), Anup Shankar Adhikari (1973), Nilratan Bandyopadhyay (1972), Gayatri Chattopadhyay (1995), and Krishna Acharya (1990). Without a doubt, the classical dances of India—Bharatanatyam, Kathakali, Kathak, Manipuri, Odissi, Mohiniyattam, Sattriya, and Kuchipudi—stand as repositories of mudras that conjure emotions and entities. Mudras, an integral facet of India’s classical dance heritage, has been ardently portrayed across every era of our creative history, narrating stories through dance. Mudras constitute the language or vocabulary of dance.
Scholars unanimously concur on the usage and significance of mudras, although discrepancies in the counted figures can be found in various aesthetic texts. According to Bharata Muni, widely regarded as the progenitor of Indian aesthetics, 13 Samyukta mudras (formed with two hands) and 24 asamyukta mudras (formed with one hand) exist. Bharata Muni firmly establishes this numerical division in the Natyashastra. However, Nandikeshvara, succeeding Bharata Muni, asserts that the dancer’s extensive repertoire encompasses 51 mudras, 28 are Asamyukta mudras, while the rest are Samyukta mudras.
Bharata Muni’s Natyashastra delineates the Samyukta mudras, including Anjali (salutation), kapota (dove), karkata (crab), swastika, pushpaputa (flower basket), khatva (bed), bardhaman (crescent), utsanga (embrace), nishad (ending point), dola (swinging arms), makar (sea creature), gajadanta (tooth of elephant), and avhiksha (beyond the sky). Meanwhile, the 24 asamyukta mudras encompass pataka (banner), tripataka (triple banner), kartarimukha (scissor mouth), arala (bent), suktundo (parrot beak), musti (fist), shikhar (peak, crest), kapitha (wood apple), katakamukha (link), suchimukh (needle face), padmakosa (lotus bud), sarpasirsha (snake head), mrigosirsha (deer head), kangul (tail), alapadma (fully bloomed lotus), chatura (clever), bhramara (bee), hamsasya (swan face), hamsapaksa (swan wing), samdamsa (pincers), mukul (flower bud), urnanabha (spider), and tamrachuda (cock). Nandikeshvara expands the asamyukta repertoire with additions like simhamukha (lion face) and chandrakala (crescent moon), some are displayed in Fig. 1. Mudra and dance share a symbiotic relationship, where each is indispensable to the other, and are interdependent, and hold equal significance. However, mudra transcends the confines of dance to establish a dynamic connection with abhinaya, the expressive element, which holds a paramount position, while dance, operating within its defined boundaries, fosters an environment for mudra to become profound and all-encompassing.

(a) Cock, (b) Face of Scissors, (c) Lotus Blooming, (d) Moon Crescent, (e) Needle, (f) Peak, (g) Square, (h) Swan Face, (i) Swan Wing, (j) Wood Apple.
The landscape of hand gesture classification, particularly within the nuanced field of mudra classification, has been extensively explored in recent literature, reflecting a collective effort to address the intricate dynamics of expressive dance movements. A comprehensive survey conducted by [6, 7] highlights the growing need for the development of robust and accurate algorithms capable of effectively deciphering the subtleties inherent in these gestures.
An avenue of exploration involves the in-depth analysis of texture and shape features extracted from preprocessed images of dance movements. In the study by [8], HOG (Histogram of Oriented Gradients) features and an SVM (Support Vector Machine) classifier are employed to classify various mudras using a labeled dataset of hand gesture images. Similarly, the works of Cho and Hong, as well as Ferreira et al. [9], leverage the HOG approach to locate and estimate attitudes toward human dancing.
The efficacy of deep learning models in classifying Indian classical dance forms has been a focal point, emphasizing the automation of mudra image identification for the enhancement of dance education and performances [10–13]. A significant contribution is made by [14], wherein a CNN is trained using stochastic gradient descent, achieving an impressive classification accuracy of 89.62% on the testing set, outperforming traditional machine learning algorithms such as support vector machines (SVMs) and k-nearest neighbors (KNNs). Subsequent research delves into the enhancement of CNN architecture, incorporating batch normalization and dropout techniques to further augment classification accuracy [15].
The exploration of the impact of data augmentation and transfer learning on CNN models for classifying hand gestures within classical Indian dance is evident in various studies aimed at performance improvement. [16] Evaluates the effects of data augmentation on CNN models, while [17] conducts a comparative study on different features for mudra classification. The investigation into the performance of various CNN architectures on limited mudras and hand gesture datasets is further enriched by the studies conducted by [18] and [19].
Expanding the discourse, [20] introduces a method for classifying various Indian dance forms using a pre-trained model called Visual Geometry Group(VGG), fine-tuning it on a dataset of six different Indian dance forms. [21] Proposes a technique for extracting and analyzing gesture features related to rhythm, dynamics, and form, utilizing multimodal techniques to compare and contrast gestures of different performers and performances. The application of transfer learning and fine-tuning a pre-trained VGG network is advocated by [22] for classifying hand gestures in a specific task. Another study [23] employs the VGG pre-trained model for categorizing single-hand gestures on a comprehensive Bharatanatyam Mudra dataset.
Further enriching the literature, [24] explores the fusion of multimodal features for improved gesture recognition. [25] Delves into the challenges posed by variations in lighting conditions on the accuracy of gesture recognition systems, proposing innovative solutions to mitigate these challenges. [26] Presents a novel approach to gesture recognition by combining traditional computer vision techniques with deep learning, showcasing the potential synergy between different methodologies.
While these studies collectively underscore the potential of leveraging computer vision and deep learning techniques for recognizing, classifying, and analyzing hand gestures or dance mudras, it is essential to critically examine existing approaches. The identified limitations and drawbacks, such as the absence of structural features in CNNs, underscore the need for continued research efforts aimed at refining and optimizing models to achieve higher levels of accuracy and efficiency in this intricate domain. The literature reveals a dynamic and evolving landscape, reflecting the ongoing exploration and refinement of methodologies in the pursuit of more robust and effective solutions.
Methodology
The main intention of this work is to propose a deep learning model GAMNet to prioritize CNN features by considering the structural and skeleton features and use it along with CNN features to improve the performance. These values go through a rigorous evaluation process along with the cutting-edge deep learning model, CNN, and result in intermediate representations, leading to better performance in gesture analysis. The system’s performance is evaluated by implementing it to classify Indian classical dance Mudras. Hand mudra images are extracted from dance videos and the following steps outline the data extraction process. The detailed architecture of the proposed model is in Fig. 2. The collection of extracted frame images serves as the dataset for classification. Each image corresponds to a specific instance of a hand mudra within the dance routine. These images are organized into classes based on the different mudra types, forming the ground truth labels for the classification task. The GAMNet architecture leverages this labeled dataset for training, evaluation, and testing.

Architecture of the proposed methodology.
In Video Selection and Keyframes Extraction, the process begins by selecting a dance video as the primary data source for analysis, and the first step in our approach is to extract frames from the dance video, which captures the intricate hand mudras. Methodology encompasses a series of systematic steps designed to automate the identification and capture of pivotal moments within dance videos. Initially, the selected dance video is loaded into the processing environment, Frame-by-frame analysis ensues, with each frame being assessed for its significance in portraying distinct dance poses or moments. Keyframes, representing crucial snapshots of the performance, are selectively chosen based on their temporal distribution, allowing for an even representation of significant moments. Subsequently, the extracted keyframes are cataloged as separate individual image files, forming a comprehensive dataset suitable for classification through a GAMNet approach.
To focus exclusively on hand gestures, hand detection techniques localize and segment the hands in each frame, which ensures that the subsequent classification process centers on the relevant region of interest. A potent Gaussian blur is judiciously applied to the mudra image, adeptly quelling any discordant noise, thereby yielding a pristine and smoother representation. Building upon this foundation, a judicious thresholding operation comes into play, fiercely demarcating an image wherein pixels are resolutely stratified into two resolute categories: the discernible foreground (representing the hand) and the unyielding background, predicated upon their resolute intensity values.
DMAug: Dance Mudra Augmentation
DMAug enhances the dataset by creating additional samples of the same mudra through diverse augmentation techniques, including adjustments in orientation, lighting, blur, noise, and background. These techniques encompass a range of real-world conditions, ultimately aiding in dataset enrichment, enhancing model generalization, and mitigating overfitting. The study introduces a set of DMAug techniques for achieving these enhancements.
Flipping techniques with precise axis reflection, Horizontal flips, I_h (1) performs a horizontal flip of the image by reflecting it along the vertical axis. w represents the width of the original image., while vertical flips I_v (2) maintain image integrity, perform a vertical flip of the image by reflecting it along the horizontal axis, h represents the height of the original image. Let I(x, y, c) be the original image with pixel coordinates x and y, and color channel c.
Incorporate image rotation at varying angles and scales, utilizing trigonometric functions and the rotation formula to perform image rotation at varying angles while preserving the image’s integrity. Rotation Transformation for x-coordinate (xT) as (3) and rotation Transformation for y-coordinate (yT) after applying a rotation of angle θ around the center (Cx, Cy) in (4).
Different lighting conditions like direct sunlight, artificial light, and low light can occur when capturing mudra pictures and can simulate the images by adjusting brightness (5), contrast, and gamma.
Where Ab_I(x, y, c) is the brightness-adjusted mudra image adj (1 + for brighter, 1- for darker) is a constant for brightness adjustment, and ctrl (+for brighter, - for darker) is a constant for overall brightness control. Contrast Adjustment and Gamma Correction are in (6) and (7),
Ac_I(x, y, c) is the new pixel value after contrast adjustment, μ, and α is the midpoint (128 for pixel values), and the contrast adjustment parameter respectively. For gamma correction (7), Ag_I(x, y, c) is the new pixel value after gamma correction and γ is the gamma parameter used to adjust the brightness response.
To address the blurring effects arising from motion blur, defocus blur, or camera shake in mudra images, some of the blur techniques, like Gaussian, median, and bilateral filters, were employed.
The blurred pixel value is denoted as B_I(x, y, c). Here, the variables k, l, and h correspond to kernels and coordinates, respectively, relating to the origin (x, y) of the output image.
Gaussian blur, effective at reducing high-frequency noise and achieving image smoothness, is gained through convolution with a Gaussian kernel defined by the function h, as outlined in (8). The convolution operation allows for precise control over the blur radius, and mitigating the detrimental effects of motion blur, the other distortions in the mudra images. B_I(x, y, c) represents the blurred pixel and h(k, l) represents the Gaussian filter kernel, which controls the blur radius.
To eliminate salt-and-pepper noise by replacing each image pixel I(x,y,c)) with the median value of neighboring pixels (Med(x,y,c) (r)) as in (9) within a specific radius (r),
To simulate real-world noise conditions in mudra images, including factors like low light, sensor noise, camera lens imperfections, and compression artifacts, noise N(x,y,c)) is introduced during the data augmentation (DMAug) phase. Gaussian noise, as defined in (10), is utilized for this purpose. It involves adding random values drawn from a Gaussian distribution to the image pixels. The extent of noise is controlled by adjusting the standard deviation (σ) of the distribution, which follows a normal distribution with mean 0 and standard deviation σ, represented as N(0,σ).
Where GN(σ) denotes random values drawn from a Gaussian distribution with a standard deviation (σ), values are added to the original pixel value to introduce Gaussian noise. Standard deviation (σ) controls the noise level in the image, with higher values leading to more pronounced noise.
Salt-and-pepper noise, a disruptive, impulsive noise type, is introduced to image pixels by (11),
Sn_I(x,y) represents the modified intensity value after adding salt-and-pepper noise,
ps is the probability of a pixel being affected by salt noise (replaced with the maximum value), pp (replaced with the minimum value) and 1–ps –pp (remains unchanged).
To describe the random blending of two images, image compositing, and synthetic image generation, let I1 and I2 be the two input images to be blended, and let α be a random weight sampled from a uniform distribution over the range [0, 1]. The blended image Bb_I can be defined as follows in (12):
The random weight (α) sampled from a uniform distribution, determines the contribution of the first image (I1) to the blended result. (1–α) represents the contribution of the second image (I2) to the blended result, value of α can vary between 0 (only I2 is visible) and 1 (only I1 is visible), resulting in diverse synthetic images with elements from both input images.
To describe the blending of multiple images using alpha compositing techniques, creating a seamless composite image (Co_I) by combining a foreground image (If) with a background image (Ib) based on transparency (α) and a binary mask for blending areas in If, M be the binary mask (1 for blending, 0 for non-blending) for blending areas in If. The resulting composite image Co_I can be defined (13) using alpha compositing,
The generation of a synthetic image by combining the object, text, and background images using their respective alpha mattes, which control the transparency and blending of each component in the synthetic image.
Syn_I(x,y) be the Synthetic image, Iobj(x,y) (Object image), Itex(x,y) (text image), Ibg(x,y) be the background image,, and Aobj(x,y), Atex(x,y), Abg(x,y) as Alpha matte for the object, the text and the background in (14),
Define the architecture of the classification Model Gesture Analysis Module Network, Fig. 3, the convolutional layers in the GAMNet perform operations to detect patterns in the input images, such as edges, textures, and simple shapes. The exact features learned by these layers include things like edge orientations, colors, and textures. Feature maps from the previous convolutional layer are passed through Max-pooling layers to reduce the spatial dimensions of the feature maps while retaining the most important information. This helps capture scale-invariant and translational-invariant features, i.e., down-sampled feature maps. Flatten layers reshape the 2D feature maps into 1D vectors, effectively unstacking the spatial information and preparing it for processing by fully connected layers.

Gesture Analysis Module Network architecture.
After that, each dense layer applies linear transformations followed by non-linear activations (ReLU) to the Flattened feature vectors. These layers can capture complex, hierarchical features that may involve combinations of low-level features learned in earlier layers, producing Intermediate feature vectors.
GAMNet separates the network into three parts: GX1, GD1 and GE1. These parts are designed to capture different aspects of the Gam-values. These features are then further processed using a series of complex functions and calculations (Gam1 to Gam5) to obtain the Gam values. Each Gam module represents a different variant of Gam value calculation, incorporating various complex functions and operations. Using non-linear functions enables the model to learn complex relationships and patterns within data. Ultimately, by incorporating non-linear functions at intermediate layers, the model can learn and represent complex relationships and features in the data, making more accurate predictions and classifications. Without non-linear activations, the network would behave like linear models, which can’t handle the intricacies of the input data. The choice of non-linear functions and their parameters allows for control of the level of complexity and expressiveness in the model. This control is crucial for balancing model capacity and preventing overfitting. Each value is used as a feature or component in the overall computation and is combined and manipulated to generate a final output, used for classification.
The extracted features are then processed through various sub-modules labeled as Gam1, Gam2, Gam3, Gam4, and Gam5, these variants of Gam-values capture different aspects or representations of the input image. The different variants of Gam values are computed, each with its unique calculation methods to obtain the abstract feature representation as given below,
Gam1 values are calculated by taking the 25th percentile of the values obtained from GamX1 module and combining them with GD1 as in (15) and (16) where P and Q as percentile and Quantile respectively, GX1, GD1 and GE1 are the intermediate values obtained from the GAMNet layers.
Gam2 values are calculated as in (17), where N in the summation limit represents the number of elements in the respective tensors.
Normalise the noisy Gam to obtain Gam4 values as in (20), where N(mean, stddev) represents the normal distribution with the given mean and standard deviation,
The complex functions and transformations within the Gam modules help capture intricate relationships in the data, potentially improving the model’s ability to make accurate classifications. Gam-values in (23) guide the selection of the most appropriate mudra class for a given input image, aiding the learning process and improving the overall performance of the classification model. The neural network is trained to optimize its weights and biases, so the final output is suitable for the mudra classification. This training minimizes a loss function quantifying the difference between the network’s output and the desired target values or the class labels, mudras. The Gam-values represent the model’s confidence associated with different hand mudra classes, the class with the highest Gam-value is typically chosen as the predicted class for a given input mudra. The GAMNetwork takes the input images of shape and processes them through a series of convolutional and dense layers. These layers learn to capture important patterns and features from the input images, which are crucial for distinguishing between different hand mudras.
GAMNet is an innovative deep-learning model designed to address the formidable challenges of analyzing hand gestures across diverse imaging conditions. The model aims to overcome the limitations inherent in state-of-the-art techniques, such as their inadequate handling of various sources of variability, including diverse backgrounds, illumination variations, noise, other types of interference and failure in computing relevant structural features, such as skeleton features, commonly encountered in hand gesture recognition methods. The model’s performance is evaluated on the Indian classical dance mudra dataset.
The primary challenge encountered during data collection revolved around capturing various mudras (hand gestures) in various environmental conditions. Many Indian classical art forms are typically performed under diverse illumination conditions, often in the presence of traditional ceremonial lamps. Moreover, there are no predetermined conditions for the backdrop or background; these aspects depend on the specific venue. Additionally, the artists performing these art forms are adorned in traditional, vibrant costumes and intricate jewelry. They convey their messages through a combination of mudras (hand gestures), facial expressions, footwork, and poses. The video data of Indian classical dance mudras collected from various sources were Frame Sampled into a sequence of individual frames. Keyframes were selected, and they were ranked based on their importance or informativeness. This ranking helped to create a hierarchy of keyframes, with some being more crucial than others. The final keyframes were determined based on the selection criteria and ranking. To focus exclusively on hand gestures, the hands were localized and segmented in each frame using hand detection techniques, ensuring that the subsequent classification process was centered on the relevant region of interest.
From intricate mudras, categorized into Asamyukta Hasta and Samyukta Hasta, the most complex 10 Asamyukta (single-handed gestures) mudras are taken for the study, displayed in Fig. 1. The base images were resized into 224*224*3, defined the dimensions of the input data that fed into the model, and a set of around 25,036 assorted images of mudras was generated from the base data using the augmentation techniques present in the DMAug module. Flipping and rotating images with diverse orientations and viewing angles were employed to enable the handling of different perspectives.
The simulation of varying lighting conditions involved adjustments to brightness, contrast, and gamma, resulting in the creation of a more diverse training set that aided in the augmentation of mudra images captured under different lighting scenarios. Blurring effects were introduced using Gaussian, median, and bilateral filters, replicating motion blur, defocus blur, and the camera shakes. Gaussian and salt-and-pepper noise were introduced to simulate low-light conditions, sensor noise, and imperfections. To further augment the dataset, various backgrounds were generated through random blending, image compositing, and synthetic image generation, some of the results of DMAug are shown in Fig. 4. This approach aimed to ensure that the model could handle various backgrounds, including plain walls, stages, or natural landscape conditions.

Results of DMAug on (a) Cock, (b) Face of Scissors, (c) Lotus Blooming, (d) Moon Crescent, (e) Needle, (f) Peak, (g) Square, (h) Swan Face, (i) Swan Wing, (j) Wood Apple.
A typical split dataset of 80% for training and 20% for validation set, is used during the training phase to tune hyperparameters, evaluate the model’s performance, and prevent overfitting, a subset of data the model has not seen during training. Now the GAMNetwork defined, which takes the input shape as an argument, starts by creating an input layer for the neural network with the specified input shape. Shared convolutional layers were defined in sequence, consisting of Conv2D and MaxPooling layers to extract features from the input image. The initial convolutional layer applies 32 filters of size (3, 3) with the Rectified Linear Unit (ReLU) activation function to detect image features. Subsequently, more convolutional layers follow, with a number of filters, 64 and 128, while maintaining the (3, 3) filter size and ReLU activation. After each convolutional layer, a max-pooling layer with a (2, 2) window is applied to down-sample the feature maps and retain important information. Next, the GAM Module, created three branches (GX1, GD1, GE1), each flattening the output of the convolutional layers and passing through separate dense layers with activation functions. These branches will be used for different computations. Each branch of GX1, GD1, and GE1 further processed with dense layers had to produce different types of output values, and five different GAM values (Gam1, Gam2, Gam3, Gam4, Gam5) based on the previous branches and some mathematical operations. Figure 5 used a line plot to display the raw values of the features, making it easier to observe trends or patterns in individual features (each line on the plot represents a specific feature, the x-axis corresponds to the feature index, and the y-axis represents the feature values).

Visualize the features extracted by the model.
A Probability function, was used to compute the 25th percentile (quantile) of GX1, then added to GD1 and GX1 to obtain Gam1 values. Gam2 values were computed based on various mathematical operations using GX1 and GD1. Gam3 values were calculated by subtracting the baseline (GD1) from a complex function of GX1. Gam4 values introduced randomness by adding noise to Gam3 values and normalizing it.
Gam5 values were computed using a mathematical operation on GE1. All Gam values (Gam1, Gam2, Gam3, Gam4, Gam5) are combined to obtain the final GAM values. Figure 6 displays a heatmap of features extracted from a set of example images. Each row in the heatmap corresponds to a different image, while each column represents a specific feature. The colors in the heatmap indicate the values of the features, with warmer colors (red) indicating higher values and cooler colors (blue) indicating lower values.

Heatmap of Features Extracted using GAMNet.
The model was created by taking the input and output layers as parameters, next, a feature extractor was defined using the GAMNetwork function and the classification head was created as a separate Sequential model, which takes the Gam values extracted by the feature extractor and applies additional layers for classification head are combined into a single model by specifying the input and output layers. The model, compiled with the Adam optimizer, a custom learning rate, and sparse categorical cross-entropy loss for training. The fully connected final dense layer with 128 neurons in the classification head produces the actual class predictions. Softmax activation function was used, which converts the raw model output into probability scores for each class. These probability scores indicate the likelihood of the input image belonging to each mudra class. As a part of the work, a weight study was undertaken to gain deeper insights into the functioning of our classification model designed for hand mudras.
By analyzing the filter weights of the model, a comprehensive understanding of feature extraction, particularly the detection of specific features or patterns within the input data, was achieved. The magnitude of weights in individual filters was examined, and it was observed that the network had learned to detect specific features or patterns in distinct regions of the input. Furthermore, the specialization of certain filters in detecting edges or boundaries, essential for delineating objects or regions within the input, was noted. Additionally, the recognition of repetitive patterns or textures in certain filters indicated that the network had acquired the capability to identify recurring textural or patterned elements within the data. Throughout the study, it was evident that filter weights played a pivotal role in the hierarchical feature learning process.
The change in weights of individual filters in the first convolutional layer of the neural network is been visualized through colored boxes as in Fig. 7, with the color intensity within each box indicating the strength of the weights, visualizations allow for examining specific patterns or features that the filters have learned to detect in the input data. Each box in the output represents one of these filters, and the darkness or lightness of the visualization corresponds to the weight values. Darker regions (higher weights or stronger features), and lighter regions (lower weights or weaker features), help in the analysis of patterns, and color variations aid in the understanding of how different filters respond to distinct features within the data. Notably, darker colors correspond to lower values, often approaching zero or negative values, whereas lighter colors correspond to higher values, typically nearing one or positive values.

Weights of the first convolutional layer (epoch 100).
The utilization of filters in initial layers to detect features, such as edges, and their subsequent combination in later layers to identify more intricate shapes or objects observed highlights the hierarchical nature of feature learning. Furthermore, the variability in the features learned by filters within the same layer identified with some filters exhibiting specialization in recognizing particular aspects, while others adopted a more generalized role.
Comparison of filter weights across various training epochs provided valuable insights into the evolving feature detection capabilities of the network during the training process. Moreover, the influence of filter weight initialization on their learning behavior was explored, revealing that filters initialized with varying techniques exhibited distinct characteristics. The identification of symmetry or repeated patterns in filters was accomplished, shedding light on the inherent structure within the data. Additionally, the recognition of redundancy among filters proved essential for model optimization and compression, as filters learning similar or redundant features could be consolidated to streamline the model’s architecture.
Lastly, detecting unusual or unexpected patterns in filter weights was a crucial indicator of issues during training, data quality problems, or anomalies in the learning process, allowing for prompt troubleshooting and model improvement. In summary, the weight study conducted in this research has contributed to a deeper understanding of the inner workings of the mudra classification model, ultimately facilitating the development of more effective and reliable classification systems. Evolution of Layer Weights over Training Epochs in Fig. 8 highlights the fine-grained adjustments made by the model as it refines its feature extraction and decision-making capabilities during training. These visualizations are valuable for interpreting model convergence, identifying layers that may require further training, and assessing the impact of weight initialization on training dynamics.

Evolution of layer weights over training epochs.
As in Fig. 9, the evolution of the Frobenius norm of model weights was examined over the course of training epochs; values were calculated for each set of model weights at different training epochs, revealing how the magnitude of the model’s parameters changed over time. Observed that the Frobenius norm decreased steadily throughout the training process, indicating the convergence of the neural network to a stable solution. This analysis provided valuable insights into the training dynamics and stability of the deep learning model employed in this study. Delving into the intricate patterns encoded within filter weights, helped a deeper understanding of how the model discerns and classifies hand mudras, aids in model optimization also sheds light on the interpretability and robustness of the network, paving the way for more effective and reliable hand mudra classification systems.

Evolution of frobenius norm of model weights during training.
This architecture was designed, to be versatile and trainable, making it suitable for various classification tasks, including hand gesture recognition, and works well with Indian Classical Dance Mudras with a training accuracy of 97.09%, and a validation accuracy of 96.72%, Fig. 10 gives the accuracy plot. The model performance was tested on a set of 492 images for prediction and achieved an accuracy of 96.80%, and their confusion matrix is given in Fig. 11.
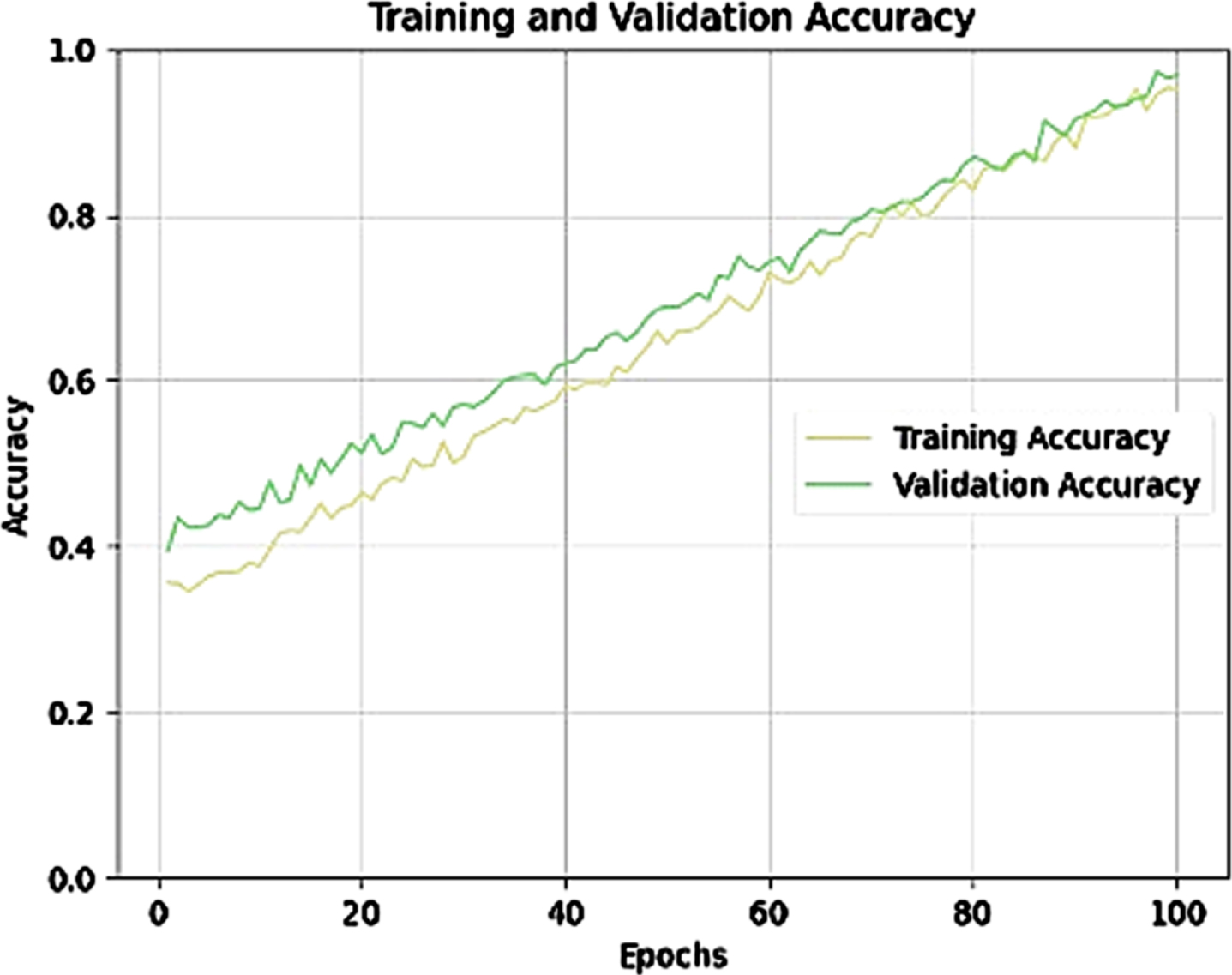
Training and validation accuracy of the architecture.
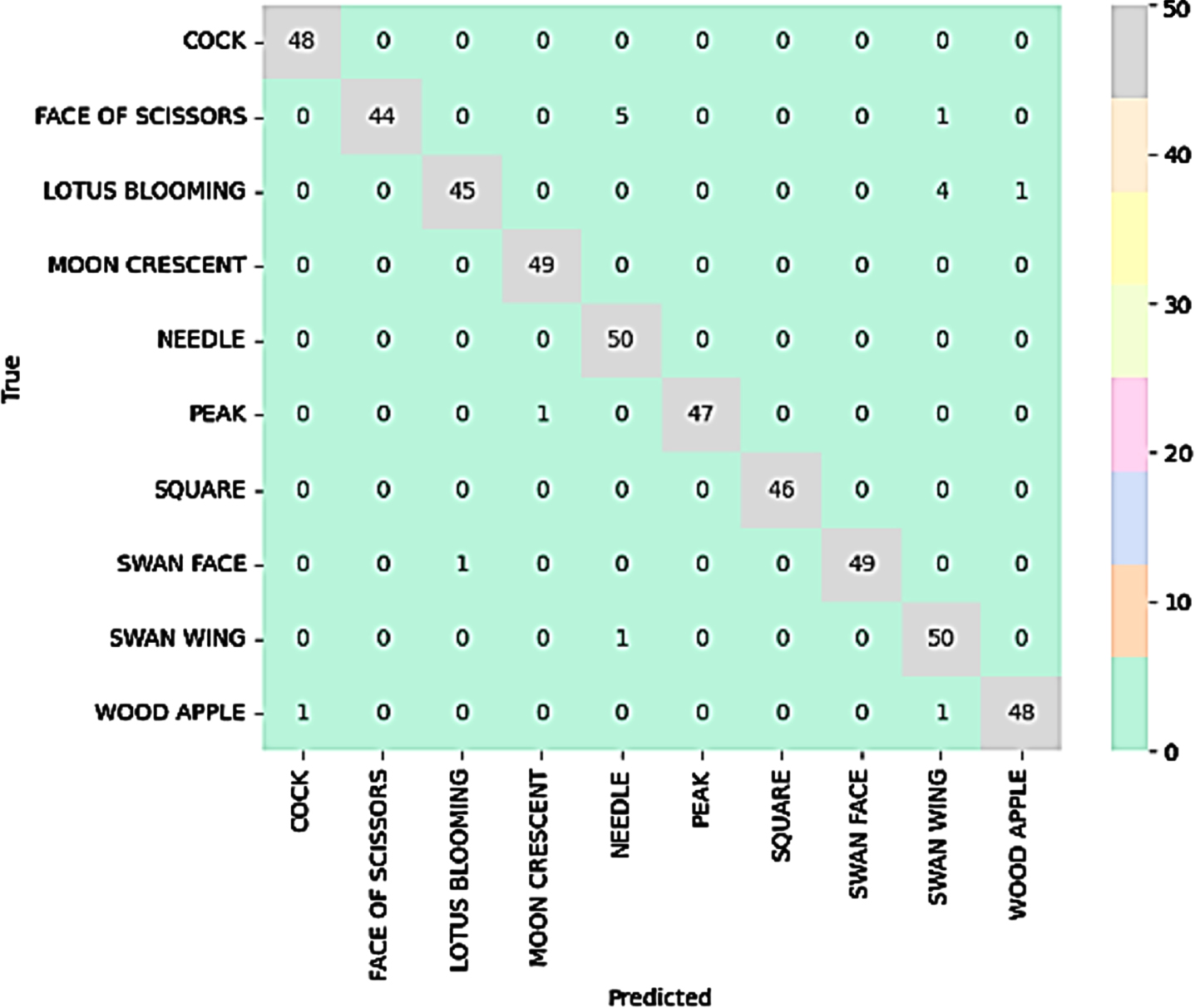
Confusion matrix.
In the analysis, it is observed that the GAMNet model exhibited the highest training accuracy at 97.09%, with a validation accuracy of 96.72% . This suggests that GAMNet is proficient at capturing patterns within the training data. GAMNet also achieved a commendable precision score of 0.969, indicating its ability to correctly classify positive instances, along with a substantial recall score of 0.938, suggesting that it effectively identified true positive Models.
Consequently, GAMNet attained an F1 score of 0.941, reflecting its strong balance between precision and recall. In contrast, the CNN model [24, 25] achieved a lower but still respectable training accuracy of 94.60% and a validation accuracy of 92.67%, suggesting that CNN captures underlying patterns reasonably well but may not generalize as effectively as GAMNet. Its precision score of 0.912 recall score of 0.880 and F1 score for CNN stands at 0.904, and a summary of the results is outlined in Table 1.
Model Metrics (Precision (P), Recall (R), F1-Score (F1)) of state-of-the-art\\ models, and GAMNet
EfficientNet [26, 27], on the other hand, displayed considerably lower training and validation accuracies of 76.22% and 45.73%, respectively, indicating a significant issue with overfitting, where the model performs well on the training data but struggles to generalize to unseen examples. The precision score for EfficientNet is 0.483, while the recall score is 0.311, leading to an F1 score of 0.392, lower scores suggest that this model struggles to correctly classify positive instances and has room for improvement. ResNet18 [28] achieved a training accuracy of 83.72% and a validation accuracy of 57.61% . While it has a notable drop in accuracy between training and validation, it doesn’t suffer from overfitting as severely as EfficientNet. Its precision score of 0.652 and recall score of 0.517, and its F1 score of 0.595.
Finally, VGGNet16 [22, 23] attained a training accuracy of 80.00% and a validation accuracy of 78.43%, indicating a relatively consistent performance between training and validation datasets. VGGNet16 also demonstrated a high precision score of 0.774 and a recall score of 0.746, leading to an F1 score of 0.760, suggesting a good balance between precision and recall. Accuracy and Precision Comparison, Recall and F1 score, GAMNet, and different Models, overall performance, as shown in Figs. 12 and 13, a boxplot to visually represent the distribution of performance metrics, including training accuracy, validation accuracy, precision, recall, and F1 score across different models. Each box indicates the interquartile range, with a centreline denoting the median. The plot provides a concise overview of the variability and central tendencies of these metrics, aiding in the comparison of model performances.

Model performance comparison-radar chart.
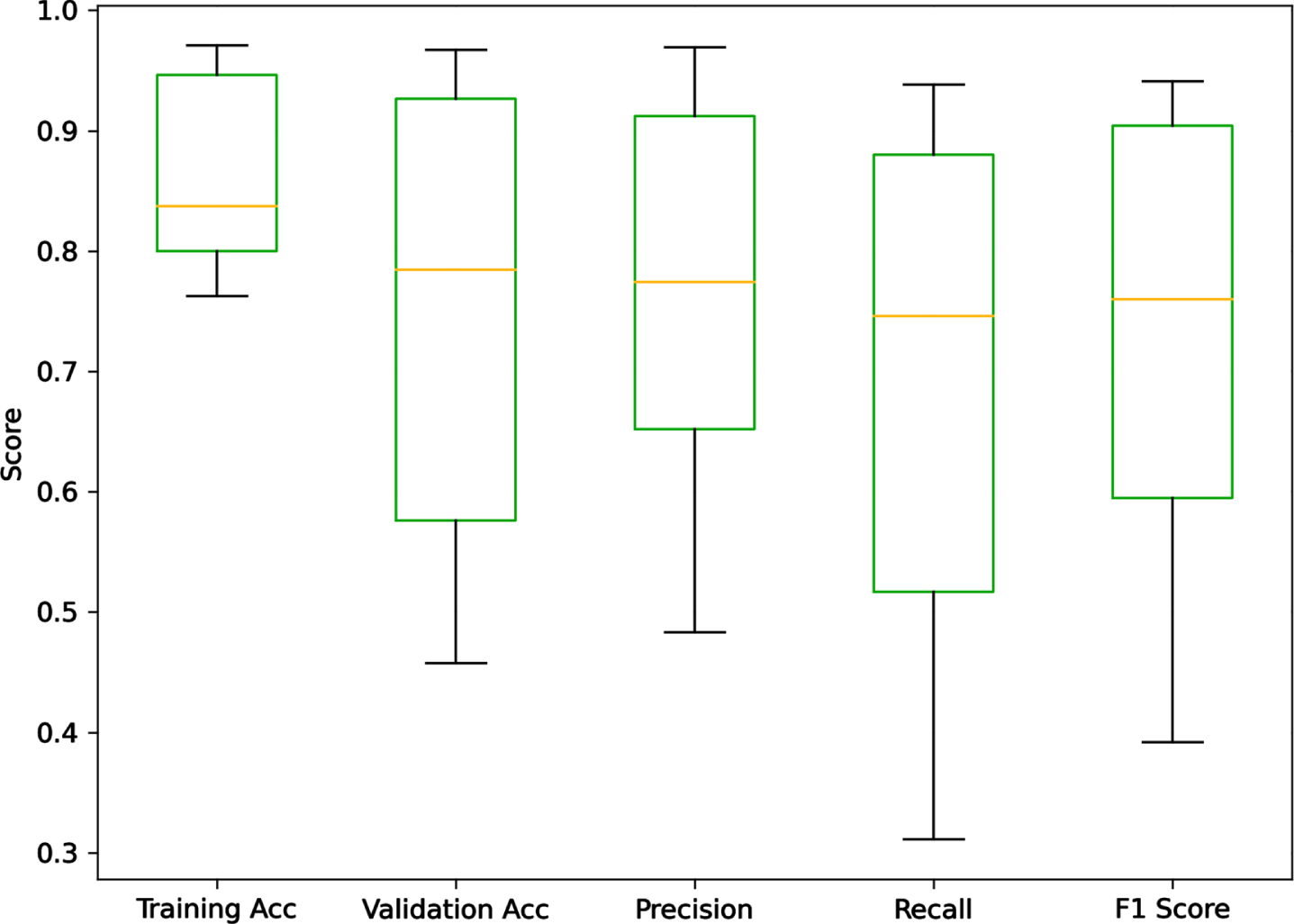
Distribution of metrics across.
In summary, the proposed GAMNet framework has demonstrated exceptional proficiency in the precise identification of static hand gestures. Consequently, this research holds significant practical implications, as it addresses intricate challenges in classifying dance mudra images. It paves the way for developing robust and effective systems with real-world applications, highlighting its potential impact in various domains.
In this paper, we propose a deep learning approach, GAMNet, for precise gesture identification to address the limitations of CNN by incorporating additional capturing of intricate relationships and patterns in the data and prioritizing CNN features using skeleton features. The study proposed a deep learning technique for image classification tasks, particularly when faced with challenging conditions such as diverse illumination, background, and camera angles, particularly in the context of classical Indian dance gesture recognition. By incorporating additional features and introducing the innovative GAMNet model, this research has demonstrated remarkable performance improvements, surpassing established models in classifying intricate hand gestures, and mudras with an accuracy of 96.80% . This work not only showcases the power of deep learning but also paves the way for future research and development in this rich and nuanced domain, further promoting the cultural heritage of Indian classical dance.