
Abstract
Unstructured text processing is the first step for several applications such as question answering systems, information retrieval, and recipe classification. In the field of recipe classification, number of frameworks have been proposed. However, it is still very tedious and time consuming to extract the food items from the unstructured text and then process for classification.
In this research, an automatic food item detection from unstructured text is proposed based on semantic sense modeling. The candidate nouns are detected which can be food items and then the similarity of those nouns is computed with possible food categories. The candidate noun is treated as food item if the similarity is high. For similarity between possible food item and food category is computed by WordNet ontology. The proposed framework is evaluated on benchmark datasets and competitive performance have been achieved. The F-score on large dataset that contains around 20 K recipes is 0.89 which is improved from 0.56.
Introduction
The abundant amount of online data about food created difficulties for the users to find recipes. The use of web for culinary and recipe search has overwhelmingly increased [13]. People are very much curious about their dietary plans and usually follow the nutritional guidelines. Nutritional sciences which are aimed at furnishing food-based dietary plans are intended to prevent from disease and achieve optimum health [10]. The Foody people are always interested in querying different recipes according to their available food items. On the otherhand, the health conscious people are much curious about their dietary plans and try to find a healthy recipe within the domain of available food ingredients. The mobile apps to track nutritional intake is much popular among health conscious people. Such apps can render desired performance if powered by excellent text processing tools. In other words, eHealth and eFood have become an integral tool of life nowadays. This has triggered the need to create the food recommender systems [6] which if powered by semantic capability of named entity recognition can yield good results. However, the scope of this research is to extract food entities from an unstructured text based on semantic similarity to empower the information retrieval tasks apropos of food recipes.
Named Entity Recognition (NER), in particular food entity recognition, is one of the most needed task in a text processing system. For example, a question answering system, to extract the correct answer from the candidate answer set, needs an accurate and efficient way to tag the named entities. Similarly, text classification systems such as recipe classification needs some way to identify food items in the text. Our research mainly focuses on identification of food items from textual data, mainly recipes. Many popular NER systems do not tag a food item therefore, we propose a framework to identify food item from the text based on semantic of the words using knowledge resources such as WordNet [24]. The addition of semantic capability for determining the food named-entities are destined to achieve the more accuracy.
Cuisine classification and food classification have been widely discussed in recent research [2, 38] However, no formal framework exist that tags food entities in a text on a large dataset. Food, cuisines and recipes have become a very interesting topic recently. A recent book, The Language of Food: A Linguist Reads the Menu, discusses network of language, history, and some hidden meanings and facts about food we eat [17]. The book discusses how some foods were developed and how the menu at a restaurant is interpreted. It also explains how food entities are referred to in text according to linguistics. This highlights that food related text processing needs maturity to better understand the things we cook and eat.
As discussed above, recent research focuses on cuisines classification and recipe classification. In cuisine classification, given recipes are categorized into various cuisines such as Thai, Mexican, Italian, or Asian. Whereas, Recipe classification deals with classifying the recipes into classes such as vegetarian/non-vegetarian, high/low calorie recipes, and starter/main-course recipes.
Investigating the food consumption by the masses is also a tedious task which is usually surveyed manually and aren’t much reliable. The food consumption statistics are on the web in both structured and unstructured form. Such statistics plays an eminent role is making good governance decisions. The solution to such problems is to mine food patterns [35] among the unstructured text which can be beautifully dealt with our approach. The main purpose of such activity would solely be ascertaining people dietary needs and interests.
The named-entity recognition is one of the significant approach to perform domain-specific information retrieval tasks. The named-entity recognition(NER) is the process of ascertaining the words or phrases from a predefined classes that gives an explanation of specific domain of knowledge. Various NER techniques exists such as terminology-driven NER method also known as dictionary-based NER method, rule-based NER method based on regular expressions and corpus-based NER method which depends on annotated corpus data [10].
In question-answering systems the knowledge graph plays the important role by identifying the relationship between selected entities. Knowledge graph is one of the famous approach for many search engines and based on resources with attributes and entities, relationships between such resources, and annotations to express meta-data about the resources [14]. Moreover, adding the semantic capability before entering the query into knowledge graph framework adds more power to such systems. Hence, the key thing in knowledge graph is entity which allows the Q&A systems to render the required answer.
This paper proposes a framework to identify food items from unstructured text. Recipes contain many food items names in it that are randomly spread all over the text. We propose a framework to identify and tag all items that are food. Once we have extracted this information from the unstructured text, it can be used in various text processing tasks such as question answering systems, food recommender system, recipe classification and food-dietary planning etc. We have tested our framework on recipe datasets, however, the framework is generalized for any type of textual data. There are number of papers on unstructured text processing available for different kind of applications [4, 33].
WordNet is a large English lexical database, which comprises of words and words senses that are semantically grouped together forming synonym sets [24]. Senses are also categorized as nouns, verbs, adjectives, and adverbs. A hierarchy of semantically related words is also available interlinking the synonym sets. WordNet encapsulates a lot of knowledge about words and their relationships. The relationships or similarity between words help to better understand the semantic of the concepts. Semantic similarity helps to deal with problems of ambiguity in a natural language processing framework [30]. There are various methods for measuring similarity between a pair of words, several based on WordNet [15, 37]. We use the similarity metric by Wu and Palmer [37] to measure similarity between a pair of words.
In proposed framework, candidate nouns that can be foods are matched for the similarity with predefined senses, that are labeled as classes later in this paper and denoted as
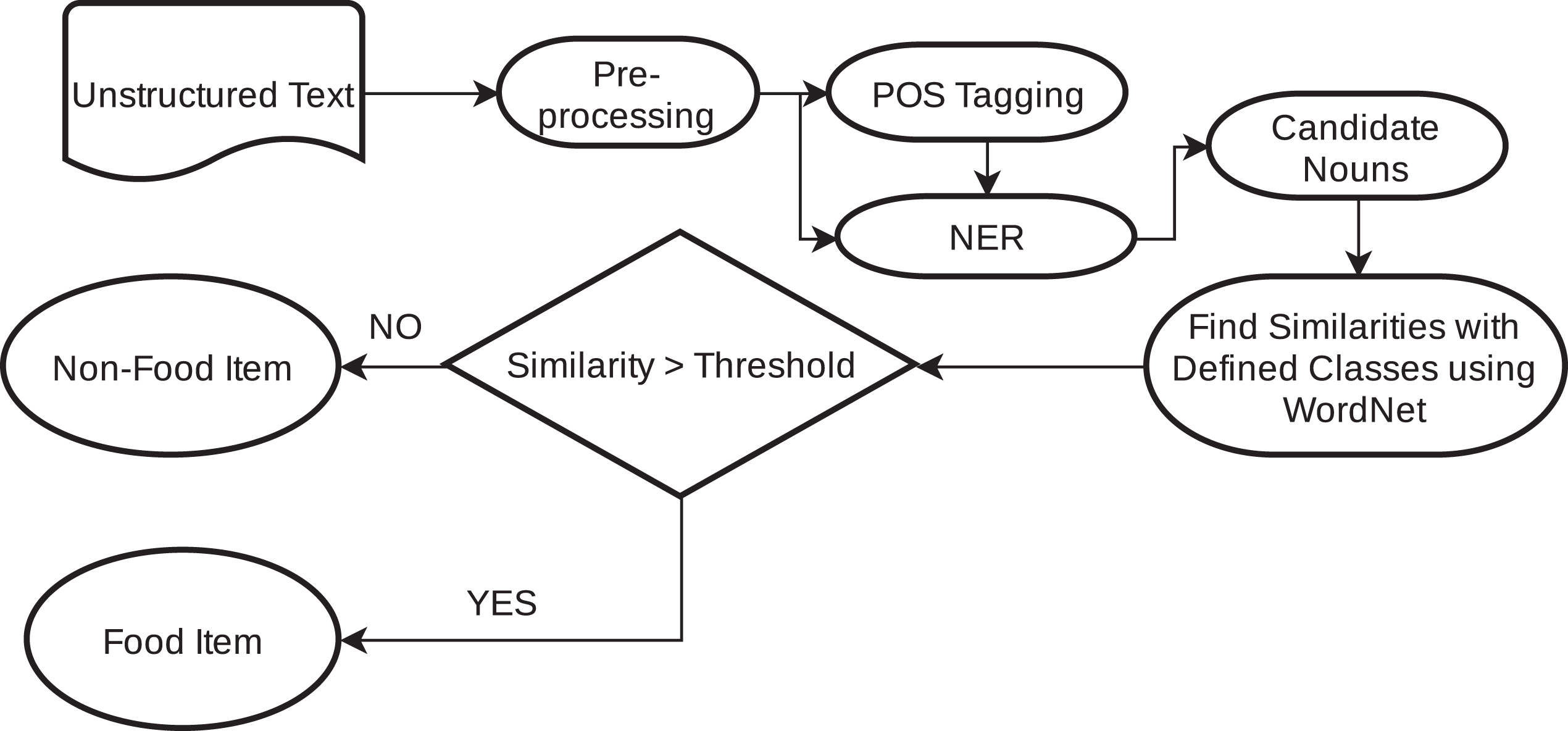
Abstract flow of the framework.
Many food related and recipe text processing frameworks have been proposed by researchers recently. In this section we discuss the current research, its limitations, and improvements required in food entities recognition and recipe text processing.
Since the inception of knowledge engineering, several knowledge extraction techniques were identified. Among these techniques the named entity recognition has got much attention by researchers. Apropos of evidence-based dietary recommendations Eftimov et al. [10] proposed a rule-based named entity recognition known as drNER for knowledge extraction. As the dietary information is represented in terms of food and nutrient entities or chemical components, unit entities etc which need to be extracted. Their proposed NER method is basically an amalgamation of terminological-driven NER and rule-based NER methods. The technique involves by initially determining the entity mentions and than selecting the entities by syntactic analysis of text. Moreover, the lack of annotated corpus data puts certain limitations on it and requires human experts to verify the recommendations.
An empirical study on Named Entity Recognition [31] reveals that traditional POS taggers, shallow parsing and NER methods for entity segmentation and information extraction arenâĂŹt reliable. To overcome this they used annotated data with their proposed T-POS & T-NER. They empirically evaluated that their T-NER method outperforms the Stanford NER System. Moreover, it was argued that their proposed T-POS and T-Chunk generated features can better help in segmenting the Named Entities.
In a recent research study Ensan et al. [11] proposed a pseudo-relevance feedback method for entity selection which is further used to expand the query to ameliorate the retrieval performance. They argued that non-transitive nature of knowledge graph relatedness in between entities and semantic relatedness may result the topic drift. TREC Web corpora was used to evaluate their proposed framework for entity selection and shown better performance for ad-hoc retrieval. There framework was based on probabilistic graphical model to capture the dependencies and an unsupervised entity selection method to expand the input query. The significance of entity selection can’t be denied as it is most preliminary preprocessing step for information retrieval systems. However, there approach is feedback dependent and may not render the desired results in the absence of such relevance-feedback.
In text processing, query expansion has long been a subject of interest for researchers. The fundamental step in expanding queries is to learn the relationships between entities and determine ontologies. Jimeno-Yepes et al. [16] discussed in their research that in information retrieval systems ontologies and terminological resources have been used for either query expansion or semantic indexing of documents usually in non-optimized mode. They proposed a language modeling technique which is based on topologies and ontologies. The key idea was the ontology refinement to support the IR operations. Our framework is also destined to optimize these IR resources so as to empower the information retrieval systems.
The healthy food recommender system has gained much prominence among the researchers during the past few years. Recently, Chen et al. [6] proposed a NutRec framework for healthy nutrition recommendation. A pseudo-recipe is generated which uses ingredient predictor, amount predictor and generate an automated healthy recipe. Subsequently, the similarity of the generated recipe is calculated from available recipes on web. For such systems our preprocessing framework suits best to accurately check the proximity of a recommended recipe.
A recent study to comprehend & predict online recipe upload behavior or the type of recipes created online and ingredients used [35] depicts another dimension of food investigation researchers introduced. In order to trace the recipe upload behavior, it is necessary to identify the features and to determine that at what extent the features are useful. Their proposed method entails, the data to be labeled and structured which is the major bottleneck in the success of this technique.
There is a rule-based NER method for food information extraction named FoodIE [28]. The system claims 96% accuracy, however, it is tested on a very small dataset of 200 recipes. The system comprises of a small number of rules, based on computational linguistics.
Some researchers have also opted the deep learning techniques to extract the scientific knowledge. Zhu et al. [39] proposed a GRAM-CNN; a deep learning approach for Named Entity Recognition in biomedical text. They used both characters & words embedding with deep learning and claimed F1 score 87.26%. However, a huge amount of data is needed to train the system.
Some systems deal with recipe classification and recipe recommendation [2]. Another research deals with food nutrition balance estimation [3]. In another paper, recipe ingredients [23], and cooking procedures are discussed [36]. However, no such system is available that tags food items in a text so that extracted food items can be used to better understand and process the recipe.
Another system classify the cuisine based on its ingredients using support vector machine [34].
A recipe processing system reports that combining verbs and ingredients causes a drop in performance, therefore, nouns should be separated from the text [32].
Agricultural NER is the basic component for developing any agriculture based application. Ample amount of work has been done in biomedical NER and general domain NER, however, agricultural NER has not yet taken in consideration. Agriculture NER [5] is an attempt to develop an NER system for agriculture domain. NLP toolkit by Stanford [23] is one of the most widely used for basic NLP tasks e.g., POS tagging, lemmatization, chunking, parsing, and basic named entity recognition. Twitter entity disambiguation investigating how much robust a number of state"-"of"-"the"-"art are on such noisy text introduced in [8]. Named entity recognition is mostly formalized as a sequence labeling problem in which syn-set of named entities are represented by label sequence in [7] effects of different SRs segment representations on NER tasks and propose a feature generation method for SRs. In [12] semantic information embedded in natural language documents can be viewed as an optimization problem aimed at assigning a sequences of labels (hidden states)to a set of inter dependent variables (textual tokens) CRF conditional random fields efficiently handled dependencies issues.
Methodology
The proposed framework extracts food entities from the unstructured text (e.g., recipe). The unstructured text may contain anything including food entities. The flow diagram is shown in Figure 1.
Initially, semantic classes,
Food Categories
Food Categories
In the first step, sentences are separated and passed to the NER and POS tagger. This step excludes basic entities that are non-food items from the given sentence using NER such as names, places, organization titles, numbers and dates. Based on POS tagging, all nouns, that left after NER filter, denoted as
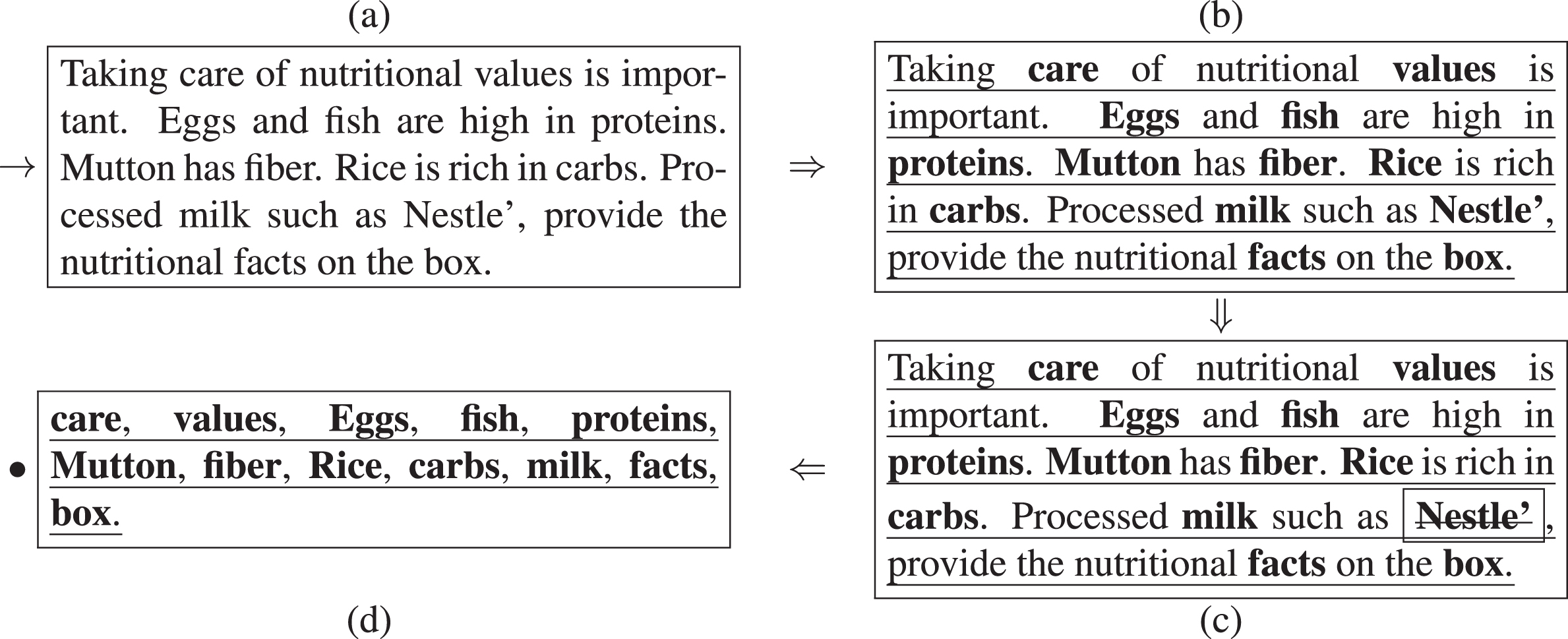
Example of POS and NER based candidate food nouns detection. (a) indicates the given input text, (b) shows the POS based nouns, (c) indicates the list of nouns that are not food items based on NER are removed, and (d) indicates the candidate nouns,
The pre-processing step involves tokenization and part-of-speech tagging of the sentences.
Part of speech tagging is usually one of the very initial text pre-processing steps for many NLP tasks. POS tagger assigns a POS tag to each of the token in a sentence e.g., Noun, Verb, Adjective, Adverb, etc. Figure 2 shows an example of a POS tagging of a sentence using Stanford University POS Tagger 1

POS Tagging.
POS tagging allows us to identify the nouns from the sentences, as an example shown in Figure 2. The intuition is that all food items would be nouns, therefore, words that are not nouns need not to be processed. Next, basic named entities are identified that are surely not food items, using named entity recognizer.
Named Entity Recognition (NER) is a task to extract entities from the unstructured text that have proper names e.g. Locations, Names, Institutes, Organization, etc. Consider the following example below
Processed milk such as Nestle’, provide the nutritional facts on the box. Nestle’ is a food processing company with headquarters located in Switzerland
NER identifies Nestle’ as Organization and Switzerland as Location. Our framework uses NER to identify the basic entities, as described above, and remove them from the text, to reduce the search space while identifying food items. The remaining nouns in the text are the candidates for identifying food items from them.
Semantic Sense Modeling
Many words in a human language have multiple semantic senses. For example, the word plant may refer to a living plant or may refer to a building of a financial bank, or may refer to an organization where one may deposit money. WordNet [24] provides all possible senses of any word in the English language.
For a given noun
Similarity of all candidate nouns,
The proposed methodology is evaluated using standard evaluation protocols and challenging datasets.
Dataset
The proposed framework works very well on far complex unstructured text to extract the food items. However, classical and focused recipes are used for the evaluation. Several dataset sets have been collected to evaluate the framework. The first dataset is collected by Kaggle site 2 , which is one of the most popular dataset sharing portal. The above mentioned dataset is known as Epicurus recipe dataset. This dataset contains of 20k recipes. Each recipe is provided with title, ingredients, set of description and directions, ratings, and some other useful information. There are approximately 3600 ingredients in all recipes. In addition, each recipe is associated with a set of categorical, i.e., cuisines, tags that it belongs. It is worthwhile to mention that the numbers of ingredients for such recipes is quite imbalanced: few recipes are too small compared to the average size of the recipes. In addition to the Epicurus recipe dataset, FoodIE dataset is used which is generated by two famous recipes sites, All recipes 3 and My Recipes 4 . This dataset quite small, contains only 200 recipes.
Evaluation
Precision
The
Extensive experiments have been conducted to evaluate the framework. The results are summarized in Tables 3- 4, and shown in Figures 4.
FoodIE dataset results for different values of
and
FoodIE dataset results for different values of
Epicurus dataset results for different values of
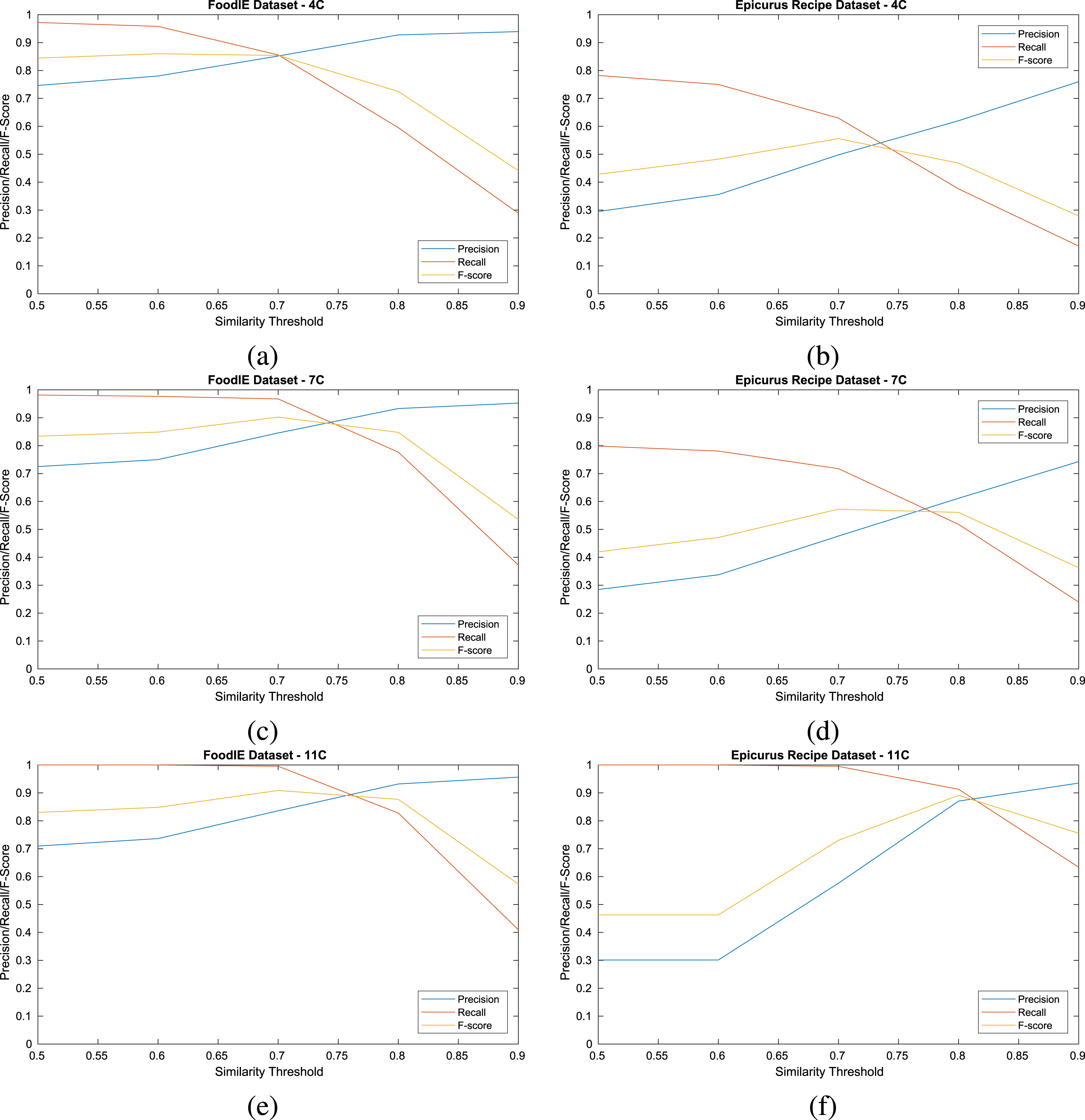
Performance evaluation of
As stated earlier, two datasets are used for the evaluation. Table 3 summarizes FoodIE dataset [28], and Table 4 summarizes Epicurus dataset. It can be seen that
Since, FoodIE is a very small dataset, contains only 200 recipes, that is the reason for higher
An automatic framework to detect food items in the given unstructured text, preferably recipes, is proposed. The NLP techniques of NER and POS are used to remove obvious non-food items, and candidate nouns that can be food items are identified which are matched for the similarity with our predefined categories,
Footnotes
Acknowledgment
We are thankful to Bilal Ahmed Chandio for providing the editorial services and feedback on the write-up. We are also thankful to the Office of Research, Innovation & Commercialization (ORIC), University of Balochistan, Quetta for providing necessary facilities to conduct the experiments.
Conflict of Interest
The authors declare that they have no conflict of interest.