
Abstract
This paper uses two optimizers (Improved Gray Wolf Optimizer (I_GWO) and Dragonfly Optimization Algorithm (DA)) for the sensitivity and robustness of artificial intelligence (AI) techniques, namely radial basis functions (RBFs). The purpose is to evaluate and analyze the predictive strength of high-performance concrete (HPC). 170 samples were collected for this purpose. This includes eight input parameters, cement, silica fume, fly ash, water, coarse aggregate, total aggregate, high water reducing agent, concrete age, and one output parameter, the compressive strength, to produce Increase learning and validation data sets. The proposed AI model was validated against several standard criteria: coefficient of determination (R2), root mean square error (RMSE), scatter index (SI), RMSE-observations standard deviation ratio (RSR), and coefficient of persistence (CP), n10_index. Many runs were performed to analyze the sensitivity and robustness of the model. The results show that I_GWO using RBF performs better than DA. Furthermore, sensitivity analysis indicated that cement content and HPC test age are the most essential and sensitive factors for predicting the compressive strength of HPC, according to the evaluations performed on the models, it was seen that the IGWO_RBF model provided better results compared to other models and can be introduced as the practical model for the prediction of HPC’s CS. In conclusion, this study can help to select appropriate AI models and suitable input parameters to accurately and quickly estimate the compressive strength of HPC.
Keywords
Introduction
High-performance concrete (HPC) is compared to conventional concrete, exhibiting superior durability, workability, and strength. Its improved attributes include chemical additives and additional cement-based material [1]. Supplemental cement-based materials like crushed blast furnace slag, silica fume, and fly ash can help reduce costs, save energy and resources, and protect the environment from impact while significantly improving the properties of concrete [2].
In the manufacturing of HPC, compressive strength (CS) is one of the most significant attributes to consider as it is nearly related to the same microstructural properties of concrete that durability and determine Young’s modulus [3, 4]. Predicting compressive strength is an important assignment [5]. The 28-day specific test procedure is time-consuming, and if the test results are below the needed strength, costly rehabilitation measures should be implemented [6]. Nevertheless, the formulas of compressive strength found in traditional concrete regulations and standards are based on tests using concrete without cement-based additives [7, 8]. Thus, to better understand the further optimize the HPC mixture and natural concrete’s demeanor, it is necessary to explore the relationship between HPC components and compressive strength [8]. Traditional mathematical models utilize a statistical approach to specify the relationship between HPC components and compressive strength [9, 10].
Over the last decades, the computational intelligence system has been introduced from experimental data to produce HPC compressive strength prediction model. At different ages, Various systems like fuzzy logic (FL) [11], artificial neural networks (ANN) [12], support vector machine (SVM) [13], genetic programming [14], and hybrid [15] have been employed to predict compressive strength. In most techniques of mixed design, the computational intelligence’s usages are based on experimental data to make an association between components and compressive strength [16].
Some researchers produce a compressive strength prediction model based on blast furnace slag and fly ash HPC experimental data. CS is a function of 8 inputs, including water, coarse and fine aggregate, silica fume, cement, superplasticizer, fly ash, and concrete age. The model’s results are more exact than nonlinear regression analysis [8]. Chen and Li [17] have studied predicting the CS of HPC by using 168 datasets. They used support vector regression (SVR) coupled with DA and I-GWO optimization to obtain the target. ANN models were built at different ages to predict the fly ash HPC’s compressive strength. The model was trained the Portland cement’s weight and utilizing sample age, fly ash, water, a high rate water reducing agent, two crushed stone types, sand, and a lime fraction of 1 concrete cubic meter [18–20].
The multi-layer neural network architecture utilized a hidden layer of 11 neurons. For both the training and test datasets, the predicted compressive strengths on days 7, 28, and 90 were very near to the actual experimental strength [21]. Experimental data shows a radial basis neural network for producing models for predicting compressive strength using fly ash and silica fume as auxiliary cement materials [22]. Predictive results show that the coefficients correlate well with the experimental values. Much research has been done on computational intelligence methods for CS prediction, but no model has been proven consistently superior [23].
Artificial neural network (ANN) was developed in architecture with artificial intelligence’s expansion. ANNs are bionic technology in the human cerebral cortex that stimulates the nerve’s transmission of information processing. Backpropagation (BP) networks, RBFNNs, Hopfield’s recurrent neural networks, etc. [24–29]. Some researchers for the concrete strength’s causal relationship have established neural network methods. The training algorithm automatically determined the strength rule from the available data. The result was more accurate for predicting concrete strength than classic regression analyses. Using RBFNN to predict the fly ash concrete’s strength, it was found that the prediction method was easy, feasible, accurate, and could have a wide range of applications [23, 26].
ANNs employ nonlinear processing units to simulate biological neurons by constructing complex nonlinear causal systems with multiple influencing factors through multiple multi-layer networks of the processing unit. It extracts causality, summarizes the data, allocates it to different neurons in the multiple sets’ form of thresholds and weights, and utilizes its rules to make predictions, an invisible mathematical. This is the processing method. The method does not consider the concrete’s complex hardening process but directly creates predictive models and provides an effective means for computational issues in concrete and solving nonlinear modeling [30–32]. Nevertheless, the BP neural network models have the network converges slowly, low learning efficiency, and the learning process is easily minimized.
In this task, the RBF model predicts the compressive strength of high-performance concrete. Two optimization algorithms are used to optimize this type of modeling and achieve results close to the laboratory sample. Both use innovative Improved Grey Wolf optimizer (I_GWO) and Dragonfly optimization algorithms (DA) to achieve better optimization results.
This study’s main contribution is coupling the Radial base function with two optimization algorithms that can brilliantly simulate the problem’s physics and complexity. The new adaptive framework provided a new state-of-art in predicting HPC’s compressive strength compared to the literature.
Materials and methodology
Data gathering
A total of 168 HPC samples were evaluated in this study. The HPC test data are functional in the literature utilized samples of various shapes and sizes. The compressive strength of HPC is achieved as a function of 8 inputs: cement, silica fume, fly ash, water, superplasticizer, coarse aggregate, total aggregate, and curing time [33]. Table 1 shows the range of these characteristics in the database. The database has been split into two parts. In the learning set, 70% of the data, and in the validation set, the remaining 30% were evenly distributed and randomly selected from the first database. It can be seen that all input variables cover a wide value range. Thus, AI models can be learned with excellent generalization capabilities.
The variables contained in the dataset and their statistical properties
The variables contained in the dataset and their statistical properties
Table 1 shows the maximum (Max), minimum (Min), average (Ave), and standard deviation (St.dev) of each variable. The inputs mentioned are defined in (kg/m3), and the compressive strength is the output defined in (MPa). The compressive strength of concrete in 28 days equals 24 MPa and in 180 days equals 107 MPa. In addition, the input heat map of the effect ratio of the admixture on the compressive strength is shown in Fig. 2. As shown in the figure, and the compressive strength increases with the increase of cement and the decrease of coarse aggregate. The correlation from 2 to 9 shows the opposite and direct relationship between compressive strength and additives. In addition, Fig. 3 shows the histogram of input and output variables. According to Fig. 3, it can be seen that most of the abundance of B was in the range of 420–390 (Kg/m3). Also, the highest frequency of CS was in the range of 50–70 (MPa), which made its distribution follow the normal state.
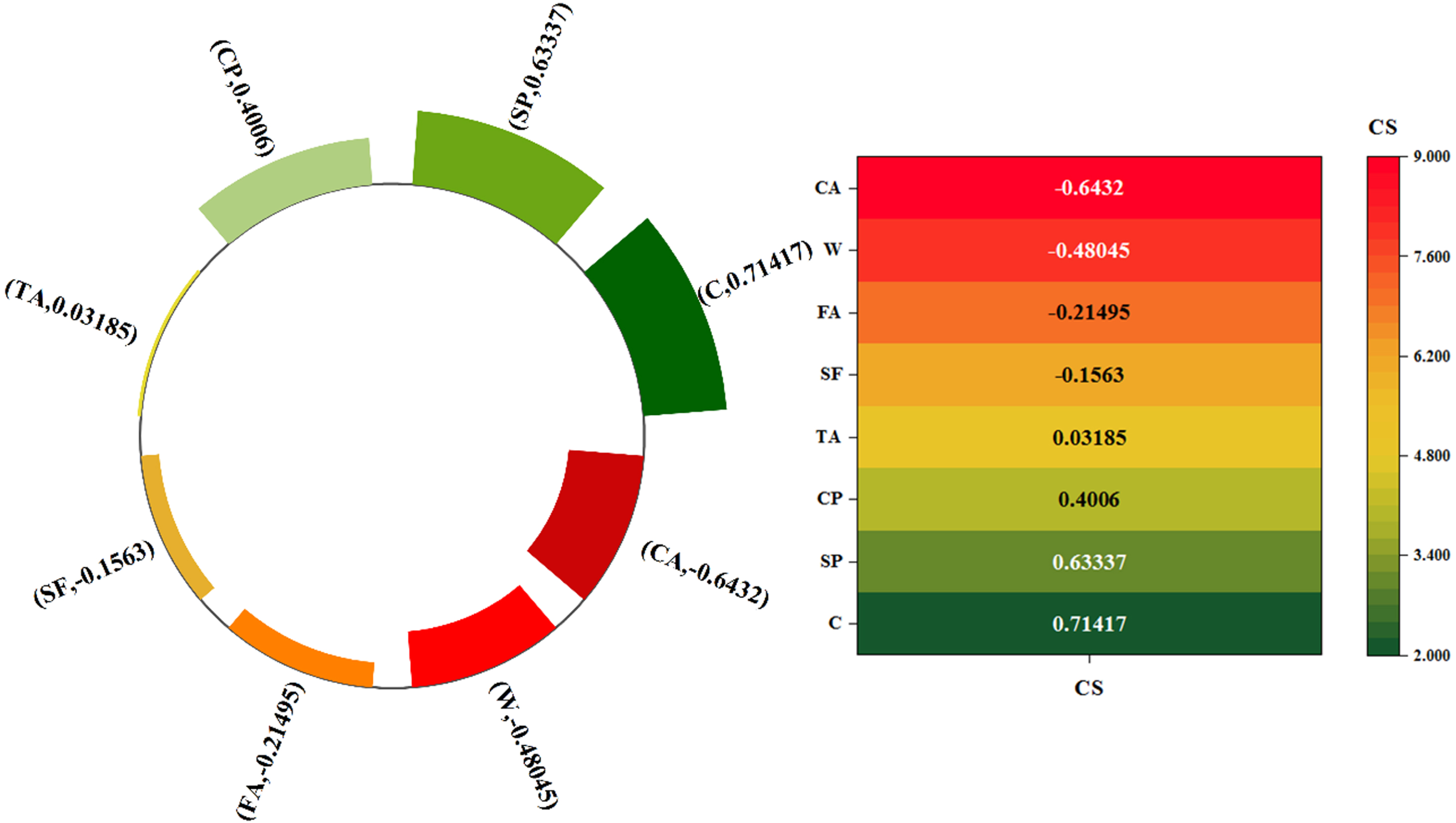
The input heat map of admixtures rate of impacts on compressive strength.

The histogram of input and output variables.
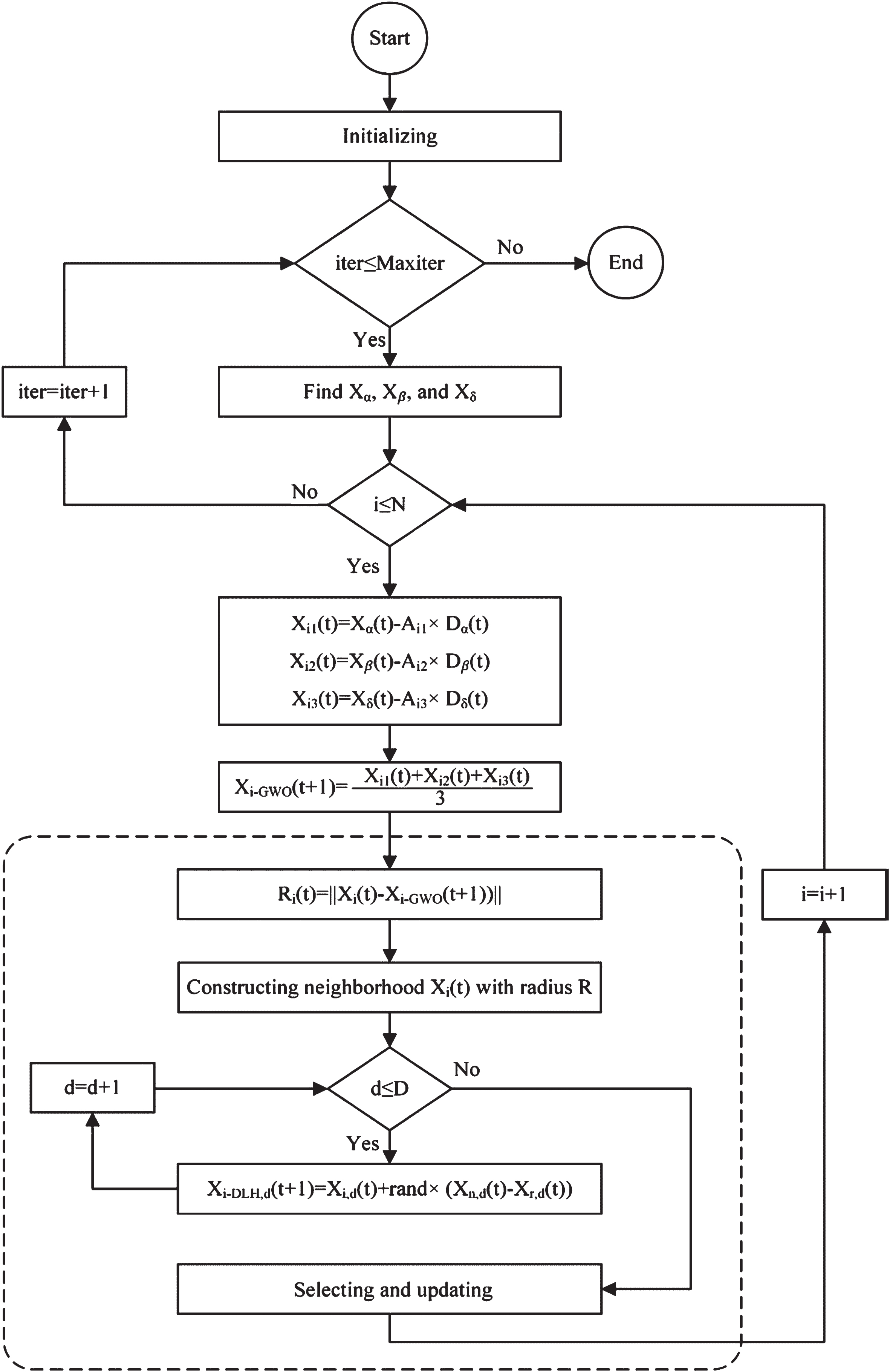
The flow chart of the I-GWO algorithm [35].
In Grey Wolf optimizer, αβ, δ, and ω wolf lead to areas of promising to explore space to find the optimal answer. The locally optimal solution may contain this demeanor. The cause of GWO falling within the local optimal range is reduced population variety. This section proposes an improved Gray Wolf Optimizer (I_GWO) to solve these problems. Improvements contain new explore strategies related to the update and selection procedures outlined in the dashed box in the I_GWO Fig. 4’s flowchart. Next, I_GWO contains three steps: initialization, motion, selection, and update.
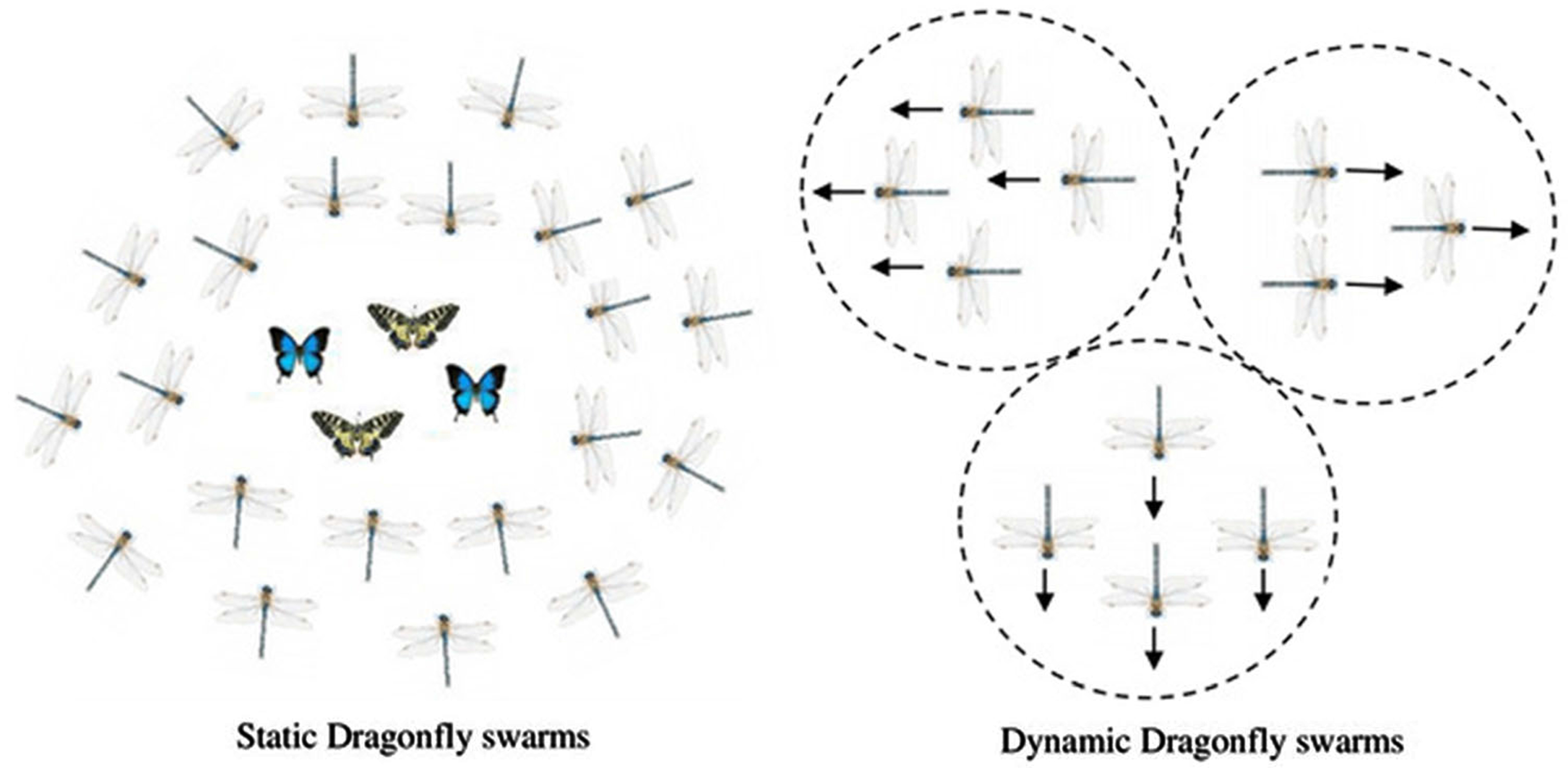
The dynamic and static swarming dragonflies’ demeanor [36].
Initialization step: In this step, n wolves are randomly placed in the explore space of a specific area [t j , v j ] according to Equation (1)
The ith wolf’s location in the tth iteration is defined as a real number of vector Y i (t) = { yi1, yi2, . . . , y id } , that d is the dimension number in the issue. The entire wolf population is stored in the n-by-d matrix Pop. By the fitness function f (Y i (t)), The Y i (t) the fitness value is computed. Motion Step: Moreover, to group hunting, lonely hunting is another interesting aspect of social grey wolves’ demeanor that is the motivation for improving GWO. I_GWO includes an additional mobility method called the Dimension Learning-Based Hunting (DLH) search method. At DLH, each wolf learns from its neighbors to be another candidate for a new location in Y i (t). How a legitimate GWO and DLH explore strategy can generate two different candidates in the following steps. Regular GWO explores method: GWO considers the top three wolves in pop to be α, β, and δ.
Then the linearly reduced coefficients a and the coefficients e and F are given by Equations (2–4). The siege of the prey is then specified by determining the Yα, Yβ, and Yδ positions by equations (5 and 6). In general, Yi-GWO (t + 1) is the first candidate for a new position in wolf Y i (t) and given in equation (7):
p1, p2: random vectors in the range [0,1].
e: the vector’s elements are linearly decreased from 2 to 0.
Dimensional Learning-Based Hunting (DLH) Explore method: The original GWO creates a new location for each wolf with the three pop leader wolves’ help. Thus, GWO converges slowly, population diversity is lost too quickly, and wolves are trapped at the local optimum. The proposed DLH foraging strategy considers the individual wolves’ hunting learned to address these deficiencies from their neighbors.
The new location in each dimension of the wolf Y i (t) is given by Equation (8) in the DLH explore method. This single wolf learns from a randomly chosen wolf learns from pop and its various neighbors. Next, in addition to Yi-GWO (t + 1) the DLH explore method will generate another candidate for a new location in the wolf Y i (t) named Yi-DLH (t + 1). For this purpose, the radius P i (t) is first computed according to equation (9) utilizing the Euclidean space between the Y i (t)’s current location and the candidate’s location Yi-GWO (t + 1):
Next, the neighborhood of Y i (t) represented by M i (t) is given by Equation (10). It is related to the radius P i (t), where B i is the Euclidean distance between Y i (t) and Y j (t):
When the Y i (t)’s neighborhood is produced, the multi-neighborhood learning is given by Equation (11). Here, the d-dimension of Yi-DLH (t + 1) is the d-dimension of the random neighbors YN,D (t) selected from M i (t) and the random wolf YN,D (t) is computed by used in pop:
Selection and update step: In this step, the better candidate is first selected by comparing the goodness of fit values of the two candidates Yi-GWO (t + 1) and Yi-DLH (t + 1) according to equation (12), increase:
After that, to update the Y i (t + 1)’s the new location, if the selected candidate’s fitness value is lower than Y i (t), then Y i (t) is updated by the selected candidate. Y i (t) is pop and unchanged. In general, after this process has been run for all individuals, the repetition counter (Iter) is incremented by one, and the exploration can be repeated until the predefined number of repetitions (MaxIter) is reached.
Developed by Mirjalili in 2016, Dragonfly Algorithm (DA) is a new, interesting, and naturally inspired metaheuristic optimization algorithm e to solve optimization’s various issues [34]. A dragonfly is a small flying carnivorous insect that hunts and eats a small insect variety such as bees, butterflies, mosquitoes, and ants. There are 3000 dragonfly types, and their life cycle has two phases: nymphs and adults. DA is according to the natural static (eating) and dynamic (moving) swarm dragonfly’s demeanor. Static and dynamic herds are shown in Fig. 5. Form a DA exploration or utilization stage. At the prey stage, the dragonfly moves the flock over long spaces in one direction, distracting the enemy. Nevertheless, during the exploration stage, dragonflies form small groups and move back and forth between small areas to attract flying prey in search of food.
The dynamic and static swarming dragonflies’ demeanor [36].
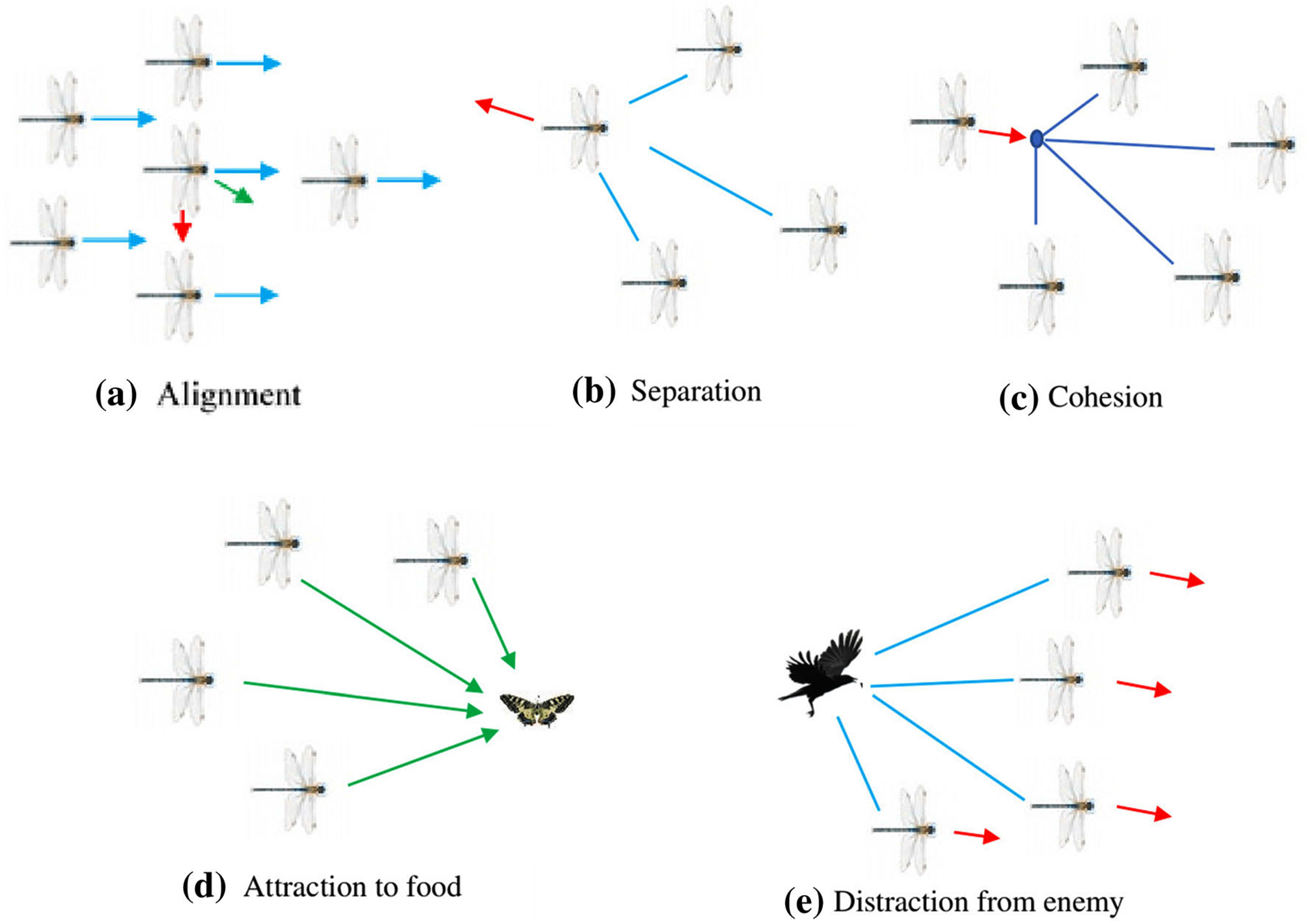
Using the five basic principles shown in Fig. 6, model the dragonfly swarm demeanor as follows: The Equation follows, Y represents the current position of the individual, Y j Indicates the location of the jth adjacent individual, and n represents the adjacent individuals’ number.
Separation represents static collision avoidance that an individual follows to avoid collisions with another individual in the neighborhood. It is modeled mathematically by equation (12).
The alignment shows an individual’s speed match among adjacent individuals in the same group. The alignment is expressed by equation (13). Where W i indicates the velocity of the ith individual.
Cohesion shows an individual’s tendency towards a group of herds’ centers. This is described in equation (14).
The attraction to food sources (A) is mathematically modeled by equation (15). Where A i represents the food source for the ith individual and Y+ is the location of the food source.
Deflection from the enemy is mathematically modeled by equation (16). Here, D i indicates the location of the ith individual’s enemy, and Y- indicates the position of the enemy.

RBF neural network [37].
The position of the artificial register mark in the search space is updated, taking into account the vector’s step ΔY and the Y position vector. The ΔY step vector is similar to the velocity vector of the PSO algorithm. It is stated and updated in the following:
Here, f defines the split point, F i defines the split point of the ith instance, e, E i defines the ith association and split points, respectively. s, S i determine the association score and the association score of the ith instance, respectively. a, A i determine the food agent and food source of individual ith, respectively. d, D i determine the agent of the enemy and the location of the enemy of the ith instance, respectively. g, as in the PSO algorithm, defines the inertial weight. n defines the number of iterations.
Next, the ith dragonfly’s location at t + 1 is updated in the following:
Exploration is ensured by employing high association and low coherence weight. Nevertheless, mining is guaranteed by employing low linking and high consolidation weights. The rate of convergence of the DA can be controlled by adaptively adjusting the weights (f), (e), (s), (a), and (d). To improve the search, randomization, and artificial dragonflies’ exploitation, a random walk (Levy flight) is introduced in the absence of an adjacent solution. Therefore, the position of the ith dragonfly at repetition t + 1 is updated in the following:
Where D represents the dimensionality of the position vector, the sample flights are computed from:
p1andp2 define random numbers in the range [1,0]. α defines a constant value.
δ is given by equation 21 below:
Here, μ (x) = (x - 1)
Radial basis function neural network (RBFNN) is employed in several control methods, including predictive model control and sliding mode control. It is known as a useful strategy to solve control problems in the indeterminate model system. To overcome the previous passivity problem in traditional teleoperation systems with the energy signals’ transmission, a unique communication mode has been developed in the communication channel to transmit estimated environmental parameters without energy. Accordingly, RBF neural networks aim to address master modeling uncertainty and parameter variability, model environmental dynamics through slave manipulator dynamics, and estimate ecological parameters by discussing performance improvements for different neural networks and experimenting with other neural network types, and future research may be possible.
The first definition is the feedforward radial basis function neural network is designed to include three layers: n inputs, n hidden nodes, and 1 output, as shown in Fig. 7. The variables are just weights from the hidden layer to the output layer.
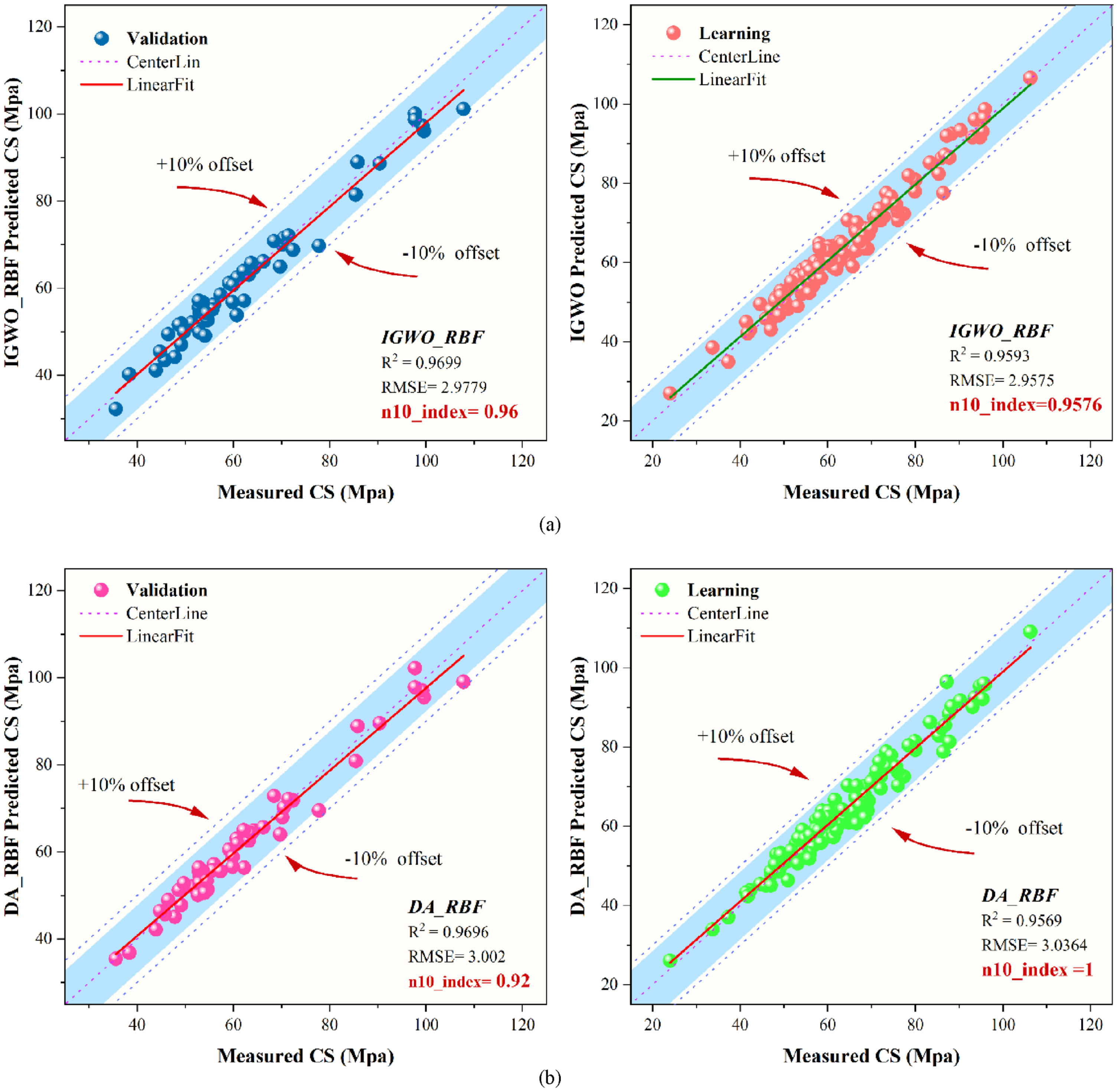
The scatter presentation of the correlation between measured and predicted values of compressive strength.
Describe input u = [u1 … u2 … u n ] P and can get the Gaussian function as follows:
L i indicate the Known parameters of the Gaussian function, v i = [vi1 … v ij … v in ] P
u - vi2: Shows the Euclidean Norm, K i = [K1 … K i … K n ] P
To describe the vi’s choice:
I = [v1 … v j … v n ] P : indicates to include different v i indifferent layers.
Next, the output of the RBF neural network is the linear weighted the n’s sum basis functions derived in the following:
t i : the weights of output.
F l : the output value.
Table 2 calculates various indicators to evaluate the model’s performance that produces compressive strength (CS) values for HPC samples during the calibration and validation phases. The indicator contains the coefficient of determination (R2):
Root means square error (RMSE):
Scatter index (SI):
RMSE-observations standard deviation ratio (RSR):
Coefficient of persistence (CP):
n10_index:
Here, p
i
shows the ith estimated CS employing models, t
i
indicates the ith observed CS. In addition, n indicates the sample number,
Results and discussion
Predicting the compressive strength of high-performance concrete needs advanced models, algorithms, and enhancements. As already mentioned, the RBF model and the two algorithms I_GWO and DA, are used as the optimizer for this model. Furthermore, the response and output of the 2 combined models, I_GWO_RBF and DA_RBF, are compared to choose the simple model and algorithm. There are 3 levels of this model: input, hide, and output. This estimate and model use parameters that indicate each modeling error and the min and max size. As already mentioned, the two models are a combination of two parts, learning and validation, and are compared utilizing the figures and shapes of two parts and two models. The learning part accounts for 70% of the sample, and the validation part makes up 30% of the sample. Therefore, the error rate in the field of education will be much higher than in the field of testing. Nevertheless, it is important to note which hidden layer algorithm performed better optimizations on the RBF model and achieved satisfactory performance and output.
To compare the present work fairly with the literature, some papers that utilized the same dataset in their implementation were chosen. The R2 and RMSE values are selected to enlighten the robustness of the present work. According to the evaluator parameters, the present work shows better values.
Table 3 shows the modeling done according to evaluators. The estimators include R2, RMSE, SI, RSR, CP, and n10_index. For the R2 parameter, which is the highest value indicating the best state, the IGWO_RBF model has the highest value of 96.99% in the validation section. On the other hand, DA_RBF in the learning section had the lowest value, equal to 95.69. In this parameter, both models have performed closely in both sections and have obtained acceptable values.
In terms of RMSE, SI, RSR, and CP parameters, unlike R2, the lowest value represents the best state. In RMSE and SI, the lowest values are 2.9575 and 0.0459, respectively, belonging to IGWO_RBF in the learning section. Also, the highest value of these two parameters belongs to DA_RBF in the learning section, with a value equal to 3.0364 for the RMSE parameter and SI with a value equal to 0.0478 in the validation section. RSR in the validation section related to the IGWO_RBF model is equal to 0.1751, which is the most suitable value, and the weakest performance related to the DA_RBF model in the learning section is equal to 0.2072. However, on the other hand, for the CP of the DA_RBF model in the learning section, the best value is equal to 142.73, and also the worst case for this model, but in the validation section. In the n10_index parameter, like the R2 parameter, the highest value indicates that the best mode belongs to the learning section in the DA_RBF model, and the weakest performance is related to the same DA_RBF model in the validation section. In general, according to Table 2, it is clear that the combined IGWO_RBF model has been able to show better performance.
Comparison of present work with similar research in the literature
Comparison of present work with similar research in the literature
Developed models’ assessment results by evaluators

Figure 8 indicates the scatter presentation of the correlation between measured and predicted compressive strength values in the learning and validating phase. Each point in this figure shows the measured and predicted samples. The center line is in the coordinate of X = Y, and if the points were close to the center line, that determined the suitable performance. Furthermore, the linear fit denotes all samples’ midpoints, and the angle difference between the linear fit and center line indicates the weak or strong performance of the respective models. In addition, there are two support lines below and above the center line. If the sample intersects the top or bottom of the related lines, the points are said to be overestimated or underestimated, respectively, according to three parameters, R2, RMSE, and n10_index. A high R2, n10_index, and a low RMSE illustrate low variance and high density.
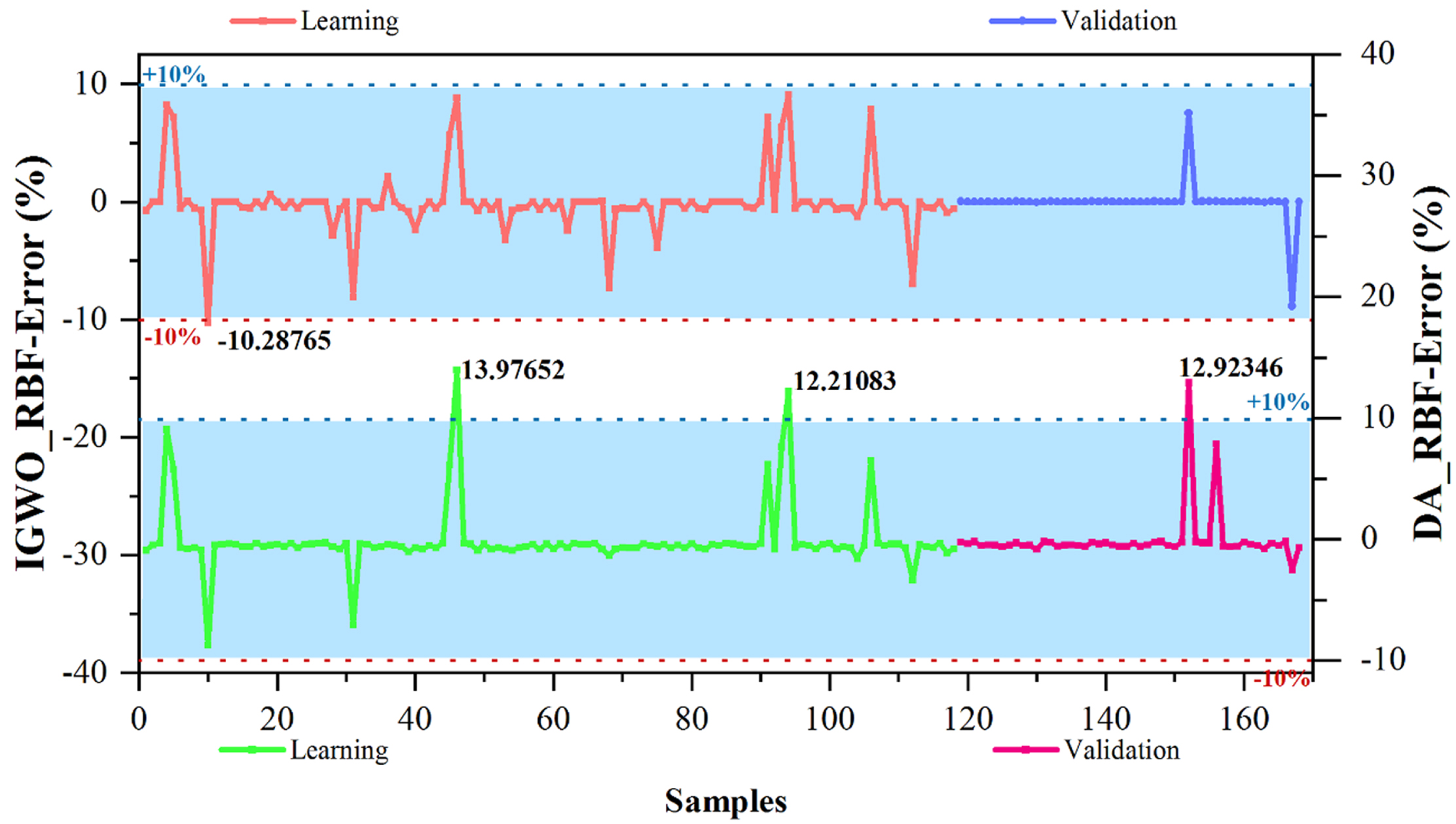
The error percentage diagram of developed models.
In general, R2 and RMSE determine the points’ location and the points’ dispersion in the series, respectively. According to the figure shown, it can be seen that the models had almost the same performance. In the comparison of the models in the validation section, due to the fact that the values of the parameters in IGWO_RBF were more suitable than DA_RBF, as a result, less dispersion was observed in IGWO_RBF. Also, DA_RBF has been underestimated in some places. On the other hand, in the learning section, despite the fact that DA_RBF has obtained high values in R2 and n10_index but has more RMSE, it has relatively high dispersion compared to IGWO_RBF.
Figure 9 indicates the percent error percentage diagram of developed models. The relevant diagram has been evaluated in the learning and validation section, and as mentioned, 70% and 30% of the samples have been allocated to these sections, respectively. Fluctuations in this diagram are desirable to be between the 10 and – 10 percent range. If any fluctuation is outside these numbers, it indicates an excessive error. In the learning part DA_RBF model, the highest value obtained in this section equals 13.97%, which has improved its performance to 12.92% in the validation section. The significant point in the values obtained in the two sections is that if the performance improvement is seen in the validation section, the result was a good training of the examples in the learning section. In IGWO_RBF, the highest error percentage was equal to 10.28%, almost 3% lower than DA_RBF. In addition, IGWO_RBF has reduced its error below 10% by improving its performance and better training, which was almost 9%. In general, comparing the two models, it can be concluded that the error of IGWO_RBF in the two parts of learning and validation is more than that of DA_RBF, which is the result of the high accuracy of the model.
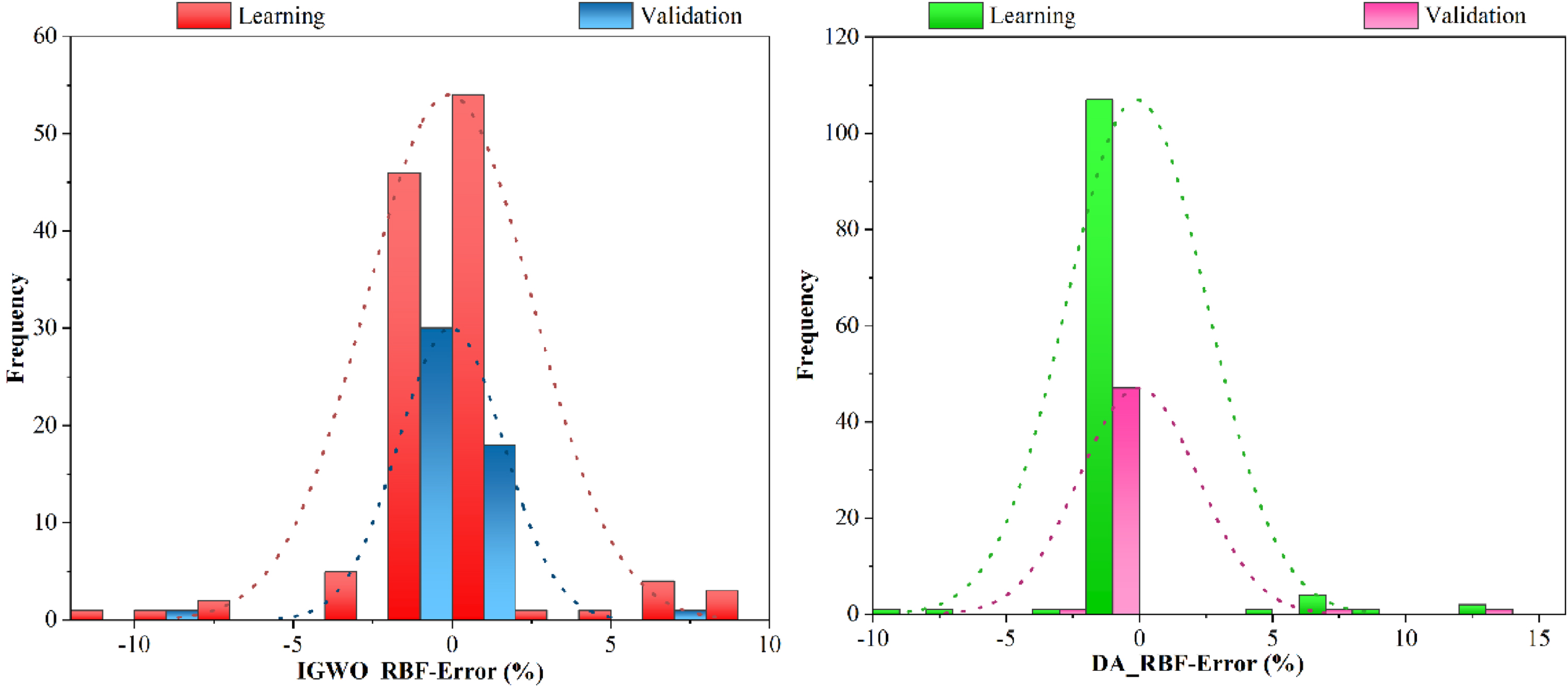
The error percentage density histogram.
Figure 10 shows the error percentage density histogram in both combined models of this article. In the specified figure for the IGWO-RBF model, the error density was in the middle and was approximately in the range of – 2.5 to 2.5. The highest error percentage, equal to 12%, involved only approximately 1 frequency in the learning section. The validation section, as well as the learning section, has a sharp normal distribution and follows the normal state, which indicates the low dispersion of errors in the two relevant sections, and the frequency of errors in the validation section was close to zero percent. On the other hand, for DA_RBF in the learning section, as it is clear in the figure, the dispersion of errors is much higher, which has caused a slight right skew. But most of the frequency of errors was in the zero interval, which obtained the normal distribution of sharpness. In the validation section related to DA_RBF, it can be seen that it performed like the learning section, so that most of the frequency of errors was in the zero percent range, but the dispersion of errors created a flatter normal distribution than IGWO_RBF. In general, it was observed that the performance of IGWO_RBF in both sections was more appropriate than DA_RBF, considering that it has more density in the zero percent range and a sharper normal distribution.
High-performance concrete (HPC) is compared to conventional concrete, which exhibits superior durability, workability, and strength performance. Its improved attributes are chemical additives and the addition of additional cement-based material. Supplemental cement-based materials like crushed blast furnace slag, silica fume, and fly ash can help reduce costs, save energy and resources, and protect the environment from impact while significantly improving concrete properties. CS is a function of 8 inputs, including water, coarse and fine aggregate, silica fume, cement, superplasticizer, fly ash, and concrete age. The model’s results are more exact than those using nonlinear regression analysis. ANN models were built at different ages to predict the fly ash HPC’s compressive strength. The model was trained on the Portland cement’s weight and utilizing sample age, fly ash, water, a highly efficient water-reducing agent, two crushed stone types, sand, and a 1 concrete cubic meter lime fraction. Artificial neural network (ANN) was developed in architecture with artificial intelligence’s expansion. The result was more accurate for predicting concrete strength than classic regression analyses. Using RBFNN to predict the fly ash concrete’s strength, it was found that the prediction method was easy, feasible, accurate, and could have a wide range of applications. The RBF model is used to predict the compressive strength of high-performance concrete. Two optimization algorithms are used to optimize this type of modeling and achieve results close to the laboratory sample. Both use innovative Improved Grey Wolf optimizer (I_GWO) and Dragonfly optimization algorithms (DA) to achieve better optimization results. These two optimizers are described in detail below. The results of the two combined models are as follows: For the R2 parameter, the IGWO_RBF model has the highest value of 96.99% in the validation section. On the other hand, DA_RBF in the learning section had the lowest value, equal to 95.69. For RMSE, the lowest values are 2.9575, which belongs to IGWO_RBF in the learning section. Also, the highest value of this parameter belongs to DA_RBF in the learning section, with a value equal to 3.0364. For SI, the lowest value is 0.0459, which belongs to IGWO_RBF in the learning section. Also, the highest value of this parameter belongs to DA_RBF, equal to 0.0478 in the validation section. RSR in the validation section related to the IGWO_RBF model equals 0.1751, which is the most suitable value, and the weakest performance related to the DA_RBF model in the learning section is equal to 0.2072. For the CP of the DA_RBF model in the learning section, the best value equals 142.73, and the worst case for this model, but in the validation section. In the n10_index parameter, the highest value indicates the best mode belongs to the learning section in the DA_RBF model equal to 1, and the weakest performance is related to the same DA_ RBF model equal to 0.92 in the validation section.