
Abstract
Pedestrian trajectory prediction plays a crucial role in autonomous driving, as its accuracy directly affects the autonomous driving system’s comprehension of the environment and subsequent decision-making processes. Current trajectory prediction methods tend to oversimplify pedestrians to mere point coordinates, utilizing positional information to infer interactions among individuals while overlooking the temporal correlations between them, thereby excessively simplifying pedestrian characteristics. To address the aforementioned issues, this paper proposes a trajectory prediction model for autonomous driving applications, that takes into account both pedestrian motion characteristics and scene interaction. The model optimizes the LSTM unit structure twice, serving to learn correlations among long trajectories of pedestrians and to integrate multiple forms of information into the neighborhood interaction module. Furthermore, our model introduces dual attention mechanisms for individuals and scenes, focusing on the key motion points of individual pedestrians and their interactive behavior with others in busy scenarios. The efficacy of the model was validated on the MOT16 pedestrian dataset and the Daimler pedestrian path prediction dataset, outperforming mainstream methods with 8% and 10% reductions in Average Displacement Error and Final Displacement Error respectively.
Introduction
As autonomous driving technology continues to advance, pedestrian trajectory prediction has become a critical component in the domain of autonomous driving [1]. Its primary objective is to forecast the future positions of individuals. The growing complexity of modern traffic scenarios heightens the risk of accidents driven by delayed driver reactions or inaccurate judgements regarding pedestrian movements on the streets. Pedestrian trajectory prediction methods, when deployed in autonomous driving systems, are capable of making swift and precise decisions [2], significantly enhancing the safety performance and decision-making of self-driving vehicles. Consequently, accurately predicting pedestrian future location information bears great significance. Autonomous vehicles need to accurately anticipate future pedestrian trajectories to improve their predictive capabilities regarding road conditions, thereby enhancing road safety.
Predicting pedestrian group trajectories in complex traffic scenarios remains a challenging task. The difficulty lies in addressing issues such as diversity, dynamics, and temporal dependence of trajectories [3]. Pedestrian behavior diversity stems from individual habits and social norms. Dynamics indicate the variability of pedestrian behavior with environmental changes. Moreover, pedestrian actions exhibit temporal dependency, potentially influenced by past behavior. Although predicting individual behavior poses challenges, advanced machine learning algorithms have made significant strides in handling these uncertainties. Topal et al. [19] have contributed to autonomous vehicle technology by detecting vehicles using FR-CNN and drawing lane lines with Canny edge detection and Hough transform, where such positional data are used to assess driver intent and prevent potential accidents. However, trajectory prediction in the context of autonomous driving requires consideration of additional pedestrian and environmental factors, such as speed, walking direction, intent, and interpersonal relations. Furthermore, pedestrians typically do not make decisions in isolation but must consider interactions with nearby vehicles and other pedestrians.
Figure 1 illustrates the influence of different information factors on predicting pedestrian trajectory in traffic scenarios. For agent 1, Fig. 1(a) shows the trajectory prediction using only historical pedestrian data (historical trajectory and size of the pedestrian). Figure 1(b) includes both pedestrian history and vehicle motion in predicting the future trajectory. In addition to historical and vehicle motion data, Fig. 1(c) also considers agent 1’s head direction, indicating intent. Experimental results demonstrate that the prediction in Fig. 1(c) is the closest to the actual scenario, achieving the smallest error. Thus, incorporating additional information factors, such as head direction and vehicle data, is crucial for improving prediction accuracy.
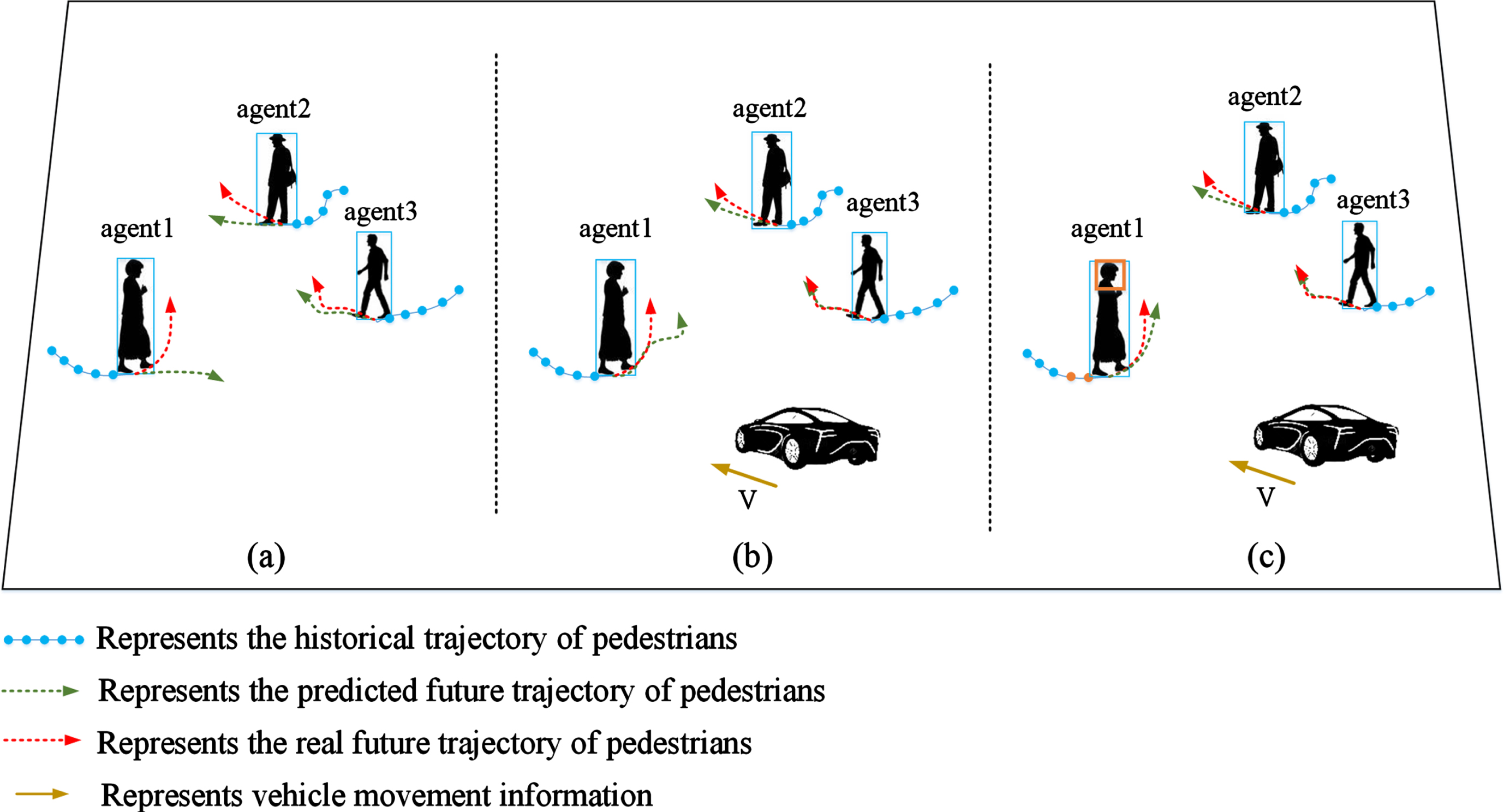
Historical trajectory and future trajectory of the agent in different scenarios.
Current pedestrian trajectory prediction methodologies predominantly rely on pedestrian positional data [4–6], which often inadequately leverage pedestrian and contextual scene information, failing to integrate pedestrian dynamics with the spatial-temporal context. Therefore, it is imperative to delve into this area for more effective predictive frameworks. This article introduces the SGPN trajectory prediction model that amalgamates CNN and LSTM with a dual-attention mechanism to holistically encapsulate individual pedestrian attributes and the pertinent environmental cues for future path estimation. The model specifically accounts for individual pedestrian information, such as historical trajectories and physical dimensions, head pose data, and contextual scene details, including interactions with proximate pedestrians and vehicles. SGPN optimizes the LSTM for individual pedestrian feature representation as well as group interaction, introduces a dual attention mechanism to highlight key motion information, resets the neighborhood, and incorporates the pedestrian’s head direction and speed vector into the interaction module. This approach caters to both the temporal feature information of individual pedestrians and the spatial interaction information of neighboring pedestrians from the driver’s perspective. The main contributions of this paper are as follows: 1. Addressing the discrepancy between vehicular perspective and actual three-dimensional spatial distances by proposing a predictive module that combines multiple feature information sources. This module learns from pedestrian trajectories and size, considering the impact of pedestrians’ head intention data and the vehicle’s own motion information. 2. Acknowledging the dual impact of individual features and group interaction on trajectory prediction, the Motion Feature Module and Scene Interaction Module are employed to achieve integration of information in both temporal and spatial domains. The Motion Feature Module uses a Tree-LSTM [7] structure to document pedestrian feature information at different times. The Scene Interaction Module addresses spatial interaction issues amongst nearby pedestrians. 3. To focus on the key movement of pedestrians and key spatial interaction information, self-attention mechanism and scene attention mechanism are respectively introduced to strengthen the model’s ability to learn the key information.
Pedestrian trajectory prediction method based on shallow learning
Early trajectory prediction techniques involved coupling elementary kinematic models (constant velocity/acceleration/turning), Probabilistic models [13], and Bayesian filters [8] or their extensions to anticipate the future positions of pedestrians. Helbing and Molanari [9] proposed a social force model based on Newtonian Mechanics, a method that has proven effective for predicting pedestrian trajectories. However, relying solely on manually designed features makes it difficult to capture interactive behaviors in complex scenarios. Schneider et al. [10] carried out a comparison between singular Kinematic model and multi-model-based approaches, which, while reducing location errors, was at odds with reality as it assumed constant speed. Pavlovi et al. [11] developed the Switched Linear Dynamical System (SLDS) model, a Markov chain-based probability transition model utilizing multiple linear motion model switching for predicting actual non-linear motion. The drawback is, this model relies on switching between movement characteristics of different states, falling short in scenarios involving multifaceted and interwoven mathematical descriptions. Bhaskara et al. [12] introduced a novel trajectory prediction model dubbed FlowMNO, which integrates a Markov process with optical flow as a pivotal component, delivering fresh perspectives within pedestrian path forecasting.
Pedestrian trajectory prediction method based on deep learning
Unlike shallow learning, deep learning does not require an established mathematical model. Instead, the network can learn sensible mapping relationships through large-scale datasets. With the recent advancements in deep learning, a wide range of models for processing temporal data have been proposed, making neural network-based trajectory prediction algorithms [14–16] mainstream, delivering significantly improved results in comparison to traditional algorithms.
Recurrent Neural Networks (RNN) [17], including variants such as LSTM and Gated Recurrent Unit (GRU) [18], have yielded significant results in trajectory prediction tasks [20]. Alahi et al. [22] first proposed the Social LSTM (S-LSTM) for trajectory prediction. This data-driven deep learning method achieved promising results on public datasets like ETH [23] and UCY [24]. Inspired by this, many have pursued similar research, the Group LSTM (G-LSTM) [26], an improved method of S-LSTM, leverages motion consistency to gather trajectories with similar motion trends and group pedestrians. However, the presumption of S-LSTM and G-LSTM that individual influences are determined by their locations is overly simplistic and cannot reflect the realities of traffic scenarios. Recently, Rashmi et al. [25] proposed the Social Group LSTM model (SG-LSTM), utilizing group dynamics for pedestrian trajectory prediction, but it only functions within short distances and disregards environmental information. Finally, Takuma Yagi et al. [33] used CNN to extract pedestrian and environment information and integrate them, proposing the FPL network model, which demonstrated impressive prediction results. The standalone application of CNN networks faces challenges in attending to the temporal and spatial sequence data of pedestrian motion, resulting in constrained predictive power for complex traffic contexts.
Addressing these limitations, we propose the SGPN model. The significant departure from previous research lies in our model’s integration of pedestrian characteristics with environmental information. It adeptly combines pedestrian features and group interactions into a cohesive framework and assigns tailored attention mechanisms to each module, thereby facilitating a more comprehensive understanding of the scene and decision-making process. Consequently, this enables a more effective prediction of pedestrian future trajectories.
Problem definition
The pedestrian trajectory prediction problem is defined as follows: predicting the trajectory of the target pedestrian i (i ∈ N, N represents the set of all pedestrians in the scene) at time t. At this time, all the feature information of the target pedestrian i can be denoted as
In our methodology, a pedestrian’s current state is determined by features encompassing their historical trajectory, dimensions, speed, and head direction. The predicted location is realized through our model, which takes the pedestrian’s existing state as input. Initially processed by Feature Fusion Module, the input is then subjected to trajectory forecasting by our prediction module, yielding the most precise prediction of position. It is imperative to emphasize that the process of decision-making for each action does not rely on traditional methods, such as Q-learning or policy iteration; instead, it is accomplished through the deep learning model SGPN designed in this study. These concepts will be elaborated upon in Section 4, dedicated to explicating the operational principles and implementation specifics of SGPN.
The proposed model
SGPN focuses on the individual pedestrian’s characteristics and interactions within the crowd. The overall network prediction framework is presented in Fig. 2. Specifically, the SGPN is composed of five modules: the Feature Fusion Module (FFM), the Motion Feature Module (MFM), the Scene Interaction Module (SIM), the Dual Attention Mechanism (DAM) and the Decoding Function Module (DFM). From Subsection 4.1 to 4.4, we elaborate on the features and functions of each module, as well as how they interact towards the goal of predicting pedestrian trajectories. A detailed description of the SGPN framework follows:

General overview of the SGPN model.
Initially, our SGPN model extracts key information from observed motion sequences of pedestrians and vehicles, including position, velocity, and direction. This information is then fused into a sequence of length A N via a one-dimensional fully convolution network, serving as input for the subsequent prediction module. Furthermore, we employ an enhanced Tree-LSTM as our principal information updating framework, which utilizes contextual data to more precisely capture pedestrian characteristics. The model assigns variable weights to individual pedestrian features and constructs feature outputs based on the significance of the outputted hidden states. Subsequently, the updated sequential information is processed by the SIM, which captures the complex spatial interactions between pedestrians, and between pedestrians and vehicles, through an elliptical neighborhood matrix. Our work specially designs a dual attention mechanism comprising both an intrinsic attention, focusing on the internal state changes of the pedestrians, and a contextual attention, dedicated to capturing detailed interactions between pedestrians and their surrounding environment. This enables the model to identify and emphasize important features. Lastly, the prediction module concatenates the encoder’s final hidden features with the latent variable z and generates the motion prediction sequence Z N through an LSTM decoder.
The objective of this study is to predict future pedestrian positions. Towards this goal, multiple influential factors need to be considered. Firstly, a pedestrian’s historical trajectory serves as a crucial determinant of their future positions. Given the inconsistency between the perspective distance in the shooting video and the actual physical space, we adopt a joint learning approach to process the information of the pedestrian’s trajectory and size. Additionally, the status of a vehicle could influence a pedestrian’s route. Therefore, we employ an egomotion algorithm to capture the vehicle’s self-movement. Lastly, to gain a more refined understanding of pedestrian movement, we incorporate information about the pedestrian’s head direction. This data is encoded and included in our analysis, the details of which will be explained later.
We perform joint learning on pedestrian position and size to mitigate the influence of perspective effect. Initially, we preprocessed the input video sequences to obtain the position coordinate information
Pedestrians may have to adjust their walking routes due to the movement of a driving car, especially when the vehicle is in close proximity, to avoid potential collisions. To enhance the positioning performance of the first-person perspective videos, we have utilized the egomotion algorithm to acquire the vehicle’s self-motion information. We can get t under the moment of rotation matrix r t (ψ, ∅ , θ) and translation vector v t (v x , v y , v z ), vehicle since the movement information is expressed as e t = (r t T , v t T ) ∈ R6.
The direction in which a pedestrian’s head is positioned can specifically indicate their movement direction. The head direction is defined using head rotation angles with values ranging from ωϵ (0, 360°). Hence, the head direction problem can be treated as a classification-regression problem. The method of Histograms of Oriented Gradients (HOG) and Support Vector Machine (SVM) is used to divide a pedestrian’s head into eight directions, represented as 0–7, where the head direction differs by 45° between two adjacent categories. First, the HOG feature describing pixel intensity gradients is applied, followed by the SVM classification method. If the pedestrian’s head image at time t is represented as p
t
, where d = 0, 1, … 7, then the probability of head direction can be expressed as follows:
Head direction classification.
The network architecture of FFM is depicted in Table 1. The input dimensions, denoted as D, vary for each stream. For instance, D = 3 for the position-scale stream, D = 6 for the egomotion stream, and D = 1 for the head direction. A fully convolutional network, equipped with four One-Dimensional (1D) convolution filters, processes the data feature series, each followed by a ReLU activation function and a Batch Normalization (BN) layer. This design augments the non-linearity of the network model, stabilizes training, accelerates convergence, and reaps better results. The position scale information, vehicle self-motion information and pedestrian head information were respectively obtained by four-layer convolution neural network to obtain 128 × 2 historical feature vectors, which were denoted as M in , E in , P in . By concatenating these three historical feature vectors end to end, the total input feature vector A N with a size of 384 × 2 is obtained. The total feature vector is put into the subsequent prediction module for further processing.
Feature fusion network framework of FFM
The MFM introduced in this study is designed to process a plethora of feature information from the FFM, thereby enhancing the model’s capability to represent pedestrian characteristics through effective information assimilation. Within the MFM, a Tree-LSTM structure is employed to handle diverse feature information in parallel, substantially improving processing efficiency. During each iteration, the feature queue is updated by incorporating the latest frame’s characteristics, ensuring continuous refinement of pedestrian feature representation.
To overcome the limitations of traditional LSTM models in learning long-term dependencies, this study employs a Tree-LSTM structure to enhance the modeling capability for complex, long-duration sequential data. Unlike LSTM models which process information in a sequential manner, the Tree-LSTM leverages its hierarchical structure to process and optimize multiple input features in parallel, rendering it more adept at capturing intricate and prolonged temporal correlations, thus boosting efficiency and model performance. In this study, the Tree-LSTM model has been refined, assigning variable weights to the feature information of individual pedestrians. These weights are predicated on the significance of the output hidden states, formulating a tailored feature module for each pedestrian.
In the MFM, the latest frame’s features are added to the queue to update it in each iteration within the features information from FFM transferred to the Tree-LSTM unit. Multiple forget gates are used to control the flow of frame information in the queue. If a pedestrian’s motion exhibits instability or discontinuity in temporal continuity with historical states, the self-adjusting ability of Tree-LSTM’s adaptive forget gate becomes crucial, Tree-LSTM can automatically adjust the degree of forget gate opening according to the input information. Consider the historical state [t0 - T
his
, t0] as a substate of the current state time t0. We first calculate the sub-state hidden in the final frame’s overall characteristics, this is represented by the formula
Where φ
a
is a multi-layer perceptron with the ReLU activation function. W
a
represents the weight matrix of φ
a
, and b
a
represents its bias matrix. The cell structure diagram of MFM is shown in Fig. 4, and the calculation formula is as follows:

The structure of Tree-LSTM.
Among them, the sigmoid function is denoted as σ,
This study builds upon the foundation of the Tree-LSTM model, enhancing its capability to process multiple features. A Tree-LSTM based feature extraction is utilized for each pedestrian, and a weighted construction of individual pedestrian feature modules is facilitated according to varying levels of importance of the hidden states output by the Tree-LSTM. The structure diagram of MFM is shown in Fig. 5, and the specific construction process is as follows: Following feature fusion via the FFM, the sequence A
N
= (a0, …, a
t
) is forwarded to the Tree-LSTM for further processing. The Tree-LSTM model structure yields a sequence of hidden state outputs h
i
= (h0, …, h
t
). Weights are applied to all hidden states at each input time step, transforming them into outputs at different time points. The corresponding distribution α
i
, for i ∈ [0, t], is then determined based on the comparative effectiveness of those states. The calculation formula for α
i
is expressed as:
Through the computation facilitated by the MFM, pedestrain i’s weighted feature information at each moment from time 0 to t is calculated as

The structure of MFM.
The SIM is utilized to simulate the motion variations of pedestrians during locomotion, which arise due to environmental factors and interactions with other pedestrians. SIM defines the vicinity of an agent, factoring in the pedestrian’s position, velocity and head orientation to characterize the interactive effects with their neighbors. Upon acquiring information on neighborhood interactions and spatial attention vectors, SIM inputs these into an LSTM network, resulting in updated cell states and hidden states.
A pedestrian’s trajectory within a crowd is heavily influenced by the behaviors of others and environmental conditions. Different people can have varying degrees of impact on one’s movement, even when they share the same pedestrian distance. This is due to individual differences, the mutual influence between two pedestrians who are facing each other in close proximity can be significantly stronger than two passing by back-to-back. This suggests that pedestrian interactions are not only dependent on distance but also on factors such as orientation and walking direction. Combine the above factors, in the SIM, we have refined our scene interaction module, redesigning it to include features that more accurately represent the factors influencing future pedestrian trajectories.
In contrast to existing research on rectangular grid maps, which identify an agent’s neighborhood as a m × n grid parallel to the absolute coordinate axis without considering the direction of the agent’s movement, our study adopts a unique approach. We establish an elliptical neighborhood matrix N0 for each pedestrian, encapsulating their positional coordinates, velocity data and heading details. This novel methodology ensures a more comprehensive and accurate analysis of pedestrian dynamics.
In defining the neighborhood of an agent, occupancy grid maps are customarily employed, with rectangular and circular grid maps centered on the agent’s current position being particularly prevalent. Figure 6(a) illustrates a typical rectangular grid map, where the grid always runs parallel to the x and y axes, regardless of the agent’s movement direction. There’s a standard assumption that pedestrians distribute their attention evenly across all directions within their neighborhood. However, the agent’s field of vision tends to be broader in the direction of travel, often resulting in greater attention to neighbors upfront and an extended visible range. Contrarily, the rear neighborhood’s impact on the agent is lesser, reciprocally reducing the agent’s rearward focus. Hence, to capture more holistically in the model how a neighbor might influence an agent’s future trajectory, we introduce the concept of anisotropic neighborhoods after conducting a coordinate transformation. As depicted in Fig. 6(b), such neighborhood settings yield neighborhoods in front and behind the agent symmetric to the y - axis, making it more representative of an agent’s perceptual reality. The neighborhood N0 is defined as:

Neighborhood size definition. (a) Rectangular grid map neighborhood; (b) This paper presents the elliptic graph neighborhood.
Among them, (x, y) are points in relative coordinates. a, b are parameters that define the neighborhood, where a > b > 0. The Y - axis of the neighborhood is consistent with the speed direction of the pedestrian at the current moment, and the neighborhood design simulates the attention of the pedestrian in the actual walking process.
Velocity, head information and position information are used to model interactions among pedestrians. By integrating the cell states of surrounding pedestrians from the previous moment, the interactive scenario within a pedestrian’s neighborhood at time t is obtained. This is designated as the neighborhood pedestrian information sharing module, denoted as
Among them, N
i
refers to the ith individual corresponding neighborhood set, and j is the pedestrian in the neighborhood corresponding to N
i
, j ≠ i.
Put
Where

The structure of SIM.
The DAM is designed to enhance focus on salient information regarding both pedestrians and the environment, thus refining the accuracy of pedestrian trajectory prediction. Tailored to the distinct characteristics of the MFM and SIM modules, an intrinsic self-attention and an extrinsic scene attention mechanism have been implemented. The self-attention mechanism correlates the historical motion states of pedestrians to capture individual behavior traits, enabling the model to concentrate on pivotal movement patterns. Conversely, the scene attention mechanism delves into the analysis of interactions between pedestrians and their surroundings, scrutinizing the influence of neighboring pedestrian dynamics on a target individual’s state.
When pedestrians are walking, their attention is mainly focused on the road conditions ahead, surrounding pedestrians and vehicles, and other potential hazards. This involves the brain’s filtering of important information and the allocation of attention to ensure that pedestrians can safely and efficiently reach their destinations. In pedestrian trajectory prediction models, introducing a self-attention mechanism first extracts information from the FFM, associates the pedestrian’s historical motion states, and approaches from a temporal perspective, enabling the model to learn how to focus on the key points of pedestrian movement.
We extract
Among them, φ
k
(·) denotes a multi-layer perceptron with ReLU as the activation function and W
k
represents its weight matrix. K
i
represents the intrinsic dynamic relationship of changes in the motion state of pedestrian i from time t0 - 1 to t0. It is a quantitative measure of the relationship between the current behavioral state and past behavioral state, aiding the network’s understanding and learning of pedestrian movement characteristics. The larger the value of K
i
, the more it indicates that the movement state of pedestrian i has maintained a high level of continuity from time t - 1 to t. Additionally, the network sets up an independent self-attention mechanism for each pedestrian in the scene, and the score of i’s self-attention mechanism at time t can be expressed as follows:
Among them, Scoreα (·) is the scoring function of this module. Since pedestrians are local elements in the scene, local attention employs the conventional scoring function, as shown in the formula (20):
Where, W
a
is the weight parameter matrix of the regular scoring function. At this point, we add the product of the self-attention score and the hidden state of pedestrian i to obtain the context propagation vector G
i
of this module:
To describe scene information in more detail, we introduced a scene attention mechanism. This measure aims to avoid the problems of insufficient scene description and inadequate description of pedestrian status caused by a single attention mechanism. It further enhances the accuracy of pedestrian trajectory prediction. The participants walking in the scene constitute the scene information. To describe the influence of interactions between pedestrians on the target pedestrian’s state, we introduce the spatial attention vector
Among them, φ
l
(·) Representing a multi-layer perceptron with ReLU as the activation function, and W
l
as the weight parameter matrix for φ
L
. Where,
Scoreβ is the scoring function of this module. In the SIM, what is calculated is the attention of the target pedestrian i to all pedestrians in the scene. Dot multiplication intuitively reflects the similarity between pedestrians, hence the scene attention mechanism employs point multiplication for scoring, as shown in formula (24).
By accumulating the product of the scene attention score and the context propagation vector of all other pedestrians j in the neighborhood, we can obtain the scene attention vector

The structure of DAM.
We connect the last hidden feature in the encoder with the latent variable to predict motion through the LSTM decoder.
In this section, we have introduced the experimental datasets, experimental environment, evaluation metrics, and parameter settings. Subsequently, we conducted cross-validation experiments, ablation experiments, and model training. Cross-validation experiments for model performance evaluation and generalization ability estimation, ablation experiments to help understand the functions of various components of the model, and model training through parameter adjustment and optimization to enhance model prediction accuracy, constitute major processes in validating the efficacy of the model and exploring the performance thereof.
Dataset description
The datasets used in this experiment are pedestrian video datasets shot from a first-person perspective: The Daimler Pedestrian Path Prediction Benchmark Dataset [28] and the MOT16 pedestrian dataset [29]. The shooting frames of Daimler dataset under different scenes.

The configuration of the experimental environment in this study includes Windows 10 operating system, an Inter Xeon E5-2620 v4 CPU, and an NVIDIA GeForce RTX 2080Ti GPU. The experiment was carried out in the Python programming language with PyTorch 1.7.1 serving as the deep learning framework, and CUDA version 11.0 for building our network model training.
Overfitting is one of the common issues encountered when training deep learning models; at its core, it stems from the model excessively focusing on the details within the training set, thereby neglecting the true patterns and structures. To mitigate this problem, the present study employs L2 regularization. The training of the model utilized the Adam optimization algorithm, which integrates the advantages of momentum and adaptive gradient methods. It adjusts the learning rate by updating both the first-order and second-order moment estimates, thereby enabling more efficient parameter updates. The computational formula for the Adam algorithm is as follows:
Where m
t
and v
t
represent the estimates of the first and second moments, respectively; β1 and β2 are hyperparameters that control the exponential decay rates for these moment estimates;
The initial learning rate of the model was set to 0.001 with hyperparameters β1= 0.9, β2 = 0.999, and a regularization coefficient of 0.001. The batch size was designated as 64, and the momentum was configured to 0.99. A total of 200 iterations were planned for the training of the model. To further enhance the model’s performance, a learning rate scheduling strategy was implemented: the learning rate was scaled down by a factor of 0.5 and 0.1 upon reaching the 50th and 150th training epochs, respectively. This adjustment technique assists in extricating the model from local minima and steering it towards the global optimum. Observations from our experimental outcomes indicate that such modifications significantly augment the model’s rate of convergence and its eventual performance.
In order to evaluate the performance of the proposed model, the evaluation indexes commonly used in trajectory prediction research were adopted in this paper: Average Displacement Error (ADE) and Final Displacement Error (FDE). ADE: In trajectory prediction, the average value of the predicted position at each moment and the Euclidean distance corresponding to the true trajectory position. The calculation process is shown in formula (32):
FDE: In trajectory prediction, the Euclidean distance between the predicted position of the final trajectory and the real final destination. The calculation process is shown in formula (33):
The training and validation dataset were randomly divided in a 4:1 ratio, followed by cross-validation experiments to validate the performance of the proposed model and to assess it. The evolution of the model’s training loss function value on the dataset is depicted in Fig. 10. Each set of cross-validation experiments were executed through 200 epochs. The five differently colored curves in the figure represent the changes in the training loss function value for the five cross-validation experiments respectively. In these, both the cross-validation experiments and the model training process utilize the Mean Squared Error (MSE) as the loss function. MSE is a regression loss function employed to calculate the mean square error between predicted values Y
i
and actual values
As can be seen from Fig. 10, the model incurs a high loss value at the beginning of training as it has not yet learned from the data, hence a significant difference between the predicted and actual results. As the number of training epochs increase, the model commences learning the features of the data, leading to a sharp decrease in the model’s loss value, which eventually flattens and stabilizes. The training loss of the model shows a declining trend and ultimately stabilizes under each cross-validation. In summary, the loss function value of the model gradually decreases and slowly converges with the increase in training epochs, suggesting that its prediction results on the dataset become more accurate and stable.
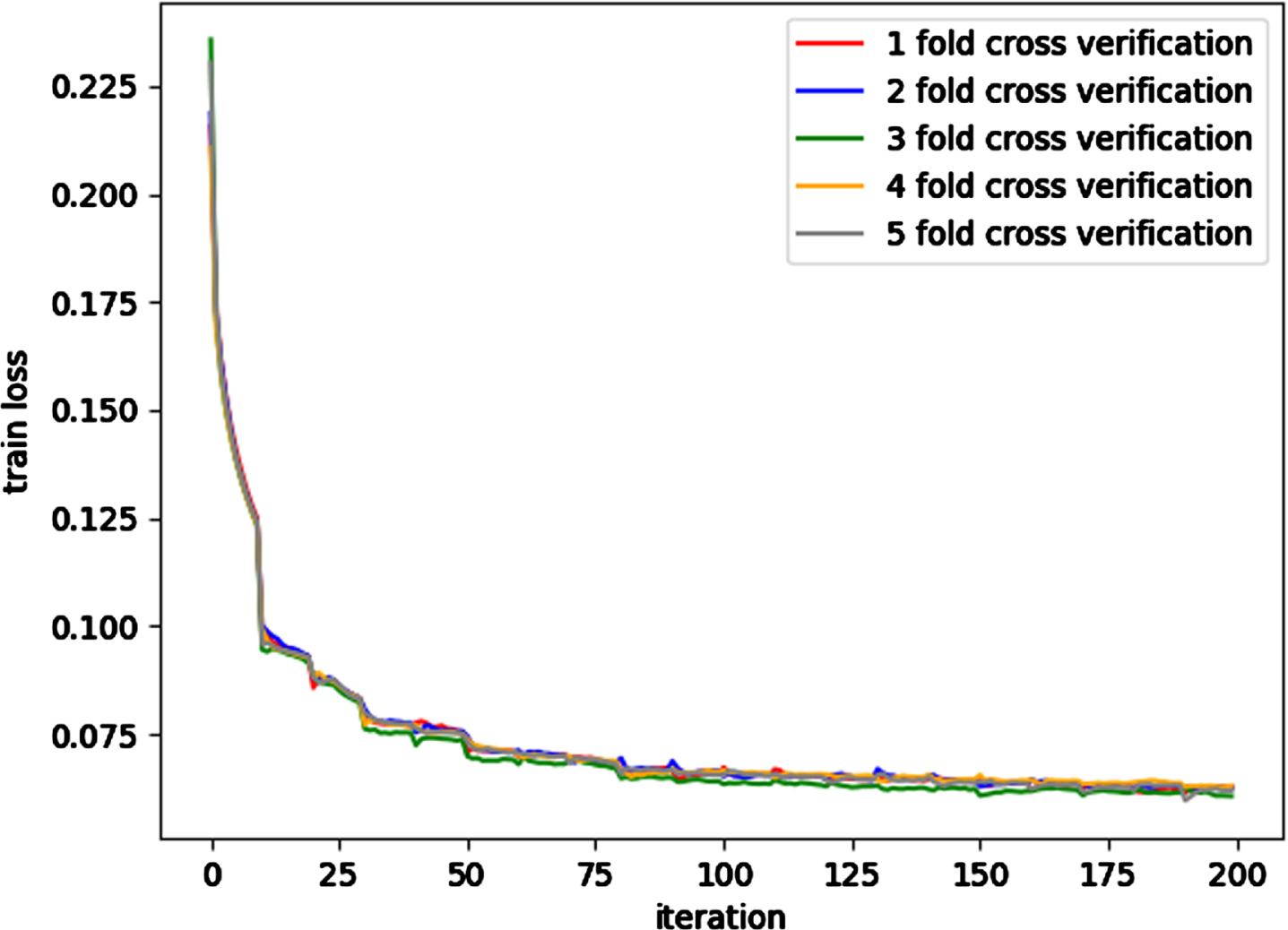
Cross-verify the variation diagram of experimental training loss function values.
In Section 4, we proposed the integration of pedestrian position, size information, pedestrian head direction, and vehicle self-motion information as crucial components of our trajectory prediction model, and subsequently proposed our predictive network. To validate the efficacy of these modules in processing the aforementioned information, This study featured a series of ablation experiments on the MOT16 pedestrian dataset and Daimler dataset, testing the performance of remaining parts when certain network structures within the model were removed, in order to assess whether the model can better utilize this information to achieve more accurate pedestrian trajectory predictions. We compared the following four experimental groups: Group A: only considered the location and size of pedestrians; Group B: considered the position, size information of the pedestrians, and the direction of pedestrian’s head; Group C: considered pedestrian position, size information, and vehicle self-motion information; Group D: considered pedestrian position, size information, pedestrian head direction, and vehicle self-motion information (our proposed model).
Table 2 presents the results from the ablation experiment:
Ablation experiment table
Ablation experiment table
Following the design and analysis of these experiments, the performance of Groups B and C exceeded that of Group A, attesting to the effectiveness of adding pedestrian head direction and vehicle self-motion information. Group D exhibited the optimal prediction performance, with significantly lower ADE and FDE compared to the other groups. The ADE index of group D decreased by 7.5% and the FDE index dropped by 5.8% when compared to Group A. These experimental outcomes demonstrate that an improved trajectory prediction model can be achieved by integrating these three strategies.
Following the introduction of our proposed methodology, both ADE and FDE indices exhibited improvements, with ADE metrics showing the most significant enhancement during testing. The ADE index reflects the variance of the prediction error at diverse points during the prediction process. This suggests that the proposal of feature fusion for pedestrian features and vehicle self-motion information, in addition to the feature addition to the interaction module, can efficiently decrease the prediction error at various time points.
In this subsection, we performed 1000 iterations of network training. After each iteration, we used the validation set to calculate the change in the loss function of the current network on the validation set. The changes of the loss function values on the training and validation sets with respect to the training iterations are depicted in Fig. 11. In the figure, the solid blue line signifies the change in the training set’s loss function, while the solid orange line represents the change in the validation set’s loss function. The horizontal axis represents the training iterations, and the vertical axis represents the loss function value of the corresponding training iteration. The experimental results show that as the number of training iterations increases, the training set loss function decreases from 0.22 to below 0.05, indicating that the model’s training has reached a relatively stable convergence state. During the early training phase, the loss function of the validation set also decreases with an increase in training iterations. However, after roughly 200 iterations, the validation set’s loss function stops declining, demonstrating that the model has reached convergence. Hence, to ensure the model’s generalization capability, training should be ceased once the iterations reach 200, and the model parameters at this point should be used as the final parameters.
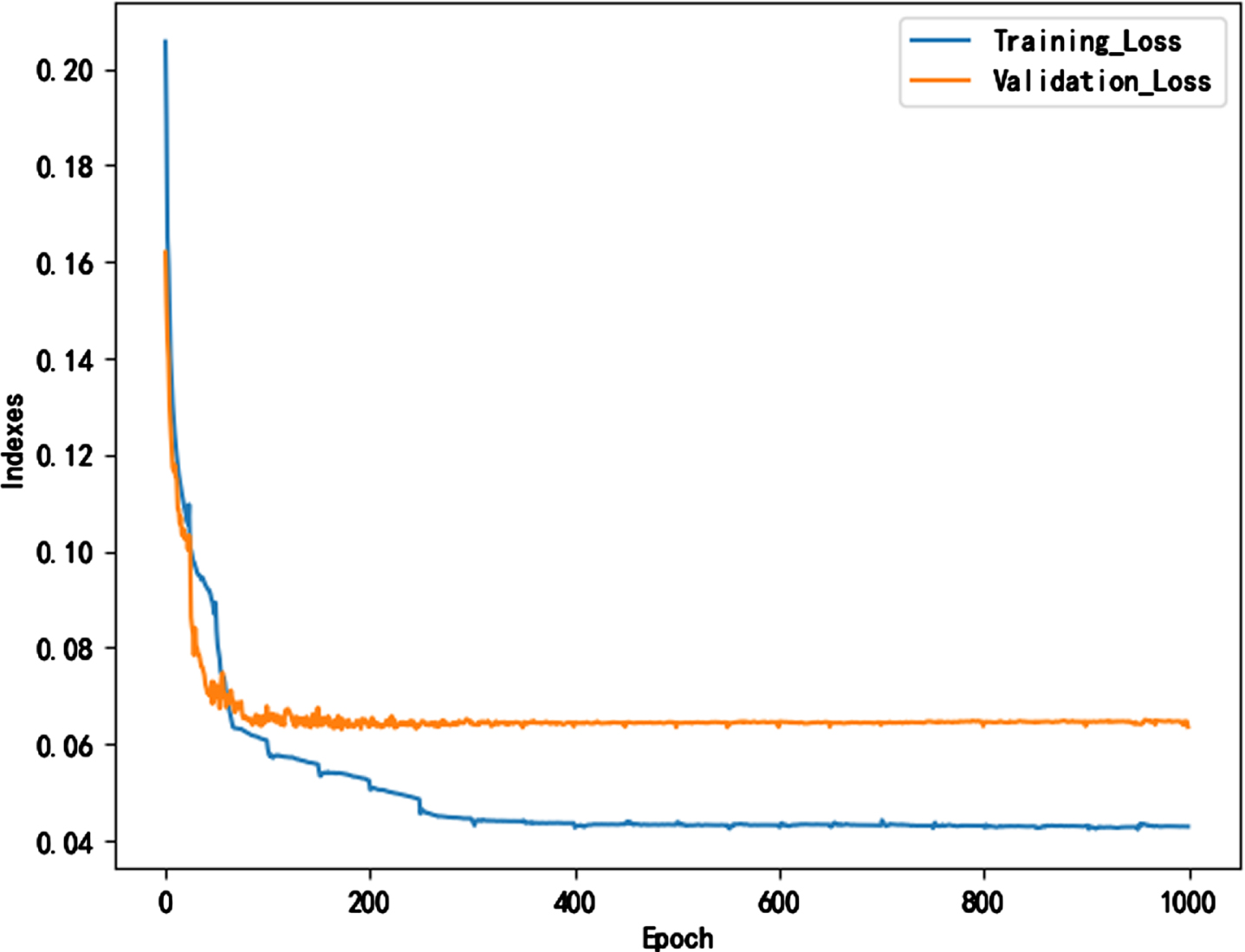
The changing process of model training loss function value.
Comparative analysis of experiment results
To fairly evaluate the accuracy of trajectory prediction between the proposed algorithm and other algorithms, we have selected eight different deep learning-based pedestrian trajectory prediction algorithms for comparison. The performance of our proposed model was measured using ADE and FDE indices, as presented in Table 3. To ensure the fairness of the comparative experiments, all models were fed with video inputs of the same duration and tasked to predict pedestrian trajectories over an identical time span (input video length of 3.2 seconds, forecasting pedestrian trajectory for the subsequent 3.2 seconds), guaranteeing that different algorithms are evaluated under equivalent conditions. In terms of learning parameter selection, we referred to the recommended settings in the original papers for each model and, from that baseline, we fine-tuned the parameters. Multiple adjustments were carried out to identify the optimum model parameters.
Experimental results comparison of several methods to our proposed model SGPN are shown
Experimental results comparison of several methods to our proposed model SGPN are shown
As can be seen from Table 3, our methodology significantly outperforms other trajectory prediction methods. The predictive performance of all algorithms is notably superior to that of traditional LSTM algorithms. S-LSTM, through social pooling, utilizes the LSTM states between adjacent pedestrians, lowering ADE and FDE slightly, but it doesn’t consider the characteristic information of pedestrians themselves in the scene, resulting in a lack of pedestrian intent expression. If the effect of self-motion on the position of people in the frame is not explicitly considered, temporal models like S-LSTM and S-GAN will fail to learn meaningful temporal dynamics, resulting in their predictions being highly unstable. SR-LSTM, which incorporates global context information, predicts group movement trajectories better. ADE and FDE are modestly lowered, but it likewise neglects the feature information of individual pedestrians and is insufficient in capturing crucial movements, lacking an expression of pedestrian intent. FPL has the best prediction result among these eight algorithms, it fully utilizes pedestrian feature information but overlooks interaction between pedestrians, ADE and FDE for the predicted model are 0.43 and 0.76 respectively. Our method takes into consideration the features of pedestrians themselves. We introduce a double attention mechanism into our model and include pedestrian feature information and vehicle self-movement information into the trajectory prediction module. The proposed SGPN outperforms all other models, with FDE at 0.68, significantly lower than the second-best model FPL, and FDE error decreased by about 10.5%.
The task of pedestrian trajectory prediction necessitates real-time applicability in autonomous driving systems, thus, a real-time performance evaluation of proposed algorithms is essential. This article comparatively investigates the operation speeds of several deep learning network-based models. The real-time performance evaluation was conducted on a platform with Inter Xeon E5-2620 v4 CPU and NVIDIA GeForce RTX 2080Ti GPU, as indicated in Table 4.
Comparison of inference speeds of different trajectory prediction models
The results reveal that the proposed algorithm functions rapidly, thus implying superior real-time performance. Specifically, the SGPN model can generate pedestrian trajectories in merely 0.089 milliseconds, which is 29.33 times and 25.33 times faster than the S-LSTM model and S-GAN model, respectively. Although the FPL model solely employs a CNN network, its operation speed decreases due to the use of a skeleton extraction algorithm during feature extraction. Compared to the relatively high-speed operation of FPL, SGPN operates at 2.33 times the speed.
This section primarily qualifies the predictive performance of the model, demonstrating the visualization results of pedestrian trajectory predictions for the Daimler dataset and MOT16 pedestrian dataset, as shown in Fig. 12 and Fig. 13. In this study, we utilized YOLOv7 in conjunction with deepsort for pedestrian detection and tracking. We have distinguished between single and multiple pedestrian scenes based on different pedestrian densities.

Examples of single pedestrian trajectory predictions of video. Figure 12(a) to Fig. 12(d) demonstrate trajectory predictions for four different types of pedestrian movement on the Daimler dataset, namely Bending In, Stopping, Crossing, and Starting; Figure 12(e) and Fig. 12(f) show the trajectory predictions for specified pedestrians from part of the MOT16 pedestrian dataset.

Examples of trajectory predictions for multiple pedestrians in video. Figure 13(a) to Fig. 13(d) illustrate the trajectory predictions for groups of pedestrians or specific multiple pedestrians in the MOT16 pedestrian dataset.
Each row represents the visualization of pedestrian trajectory sequences within a sequence of video frames. Figure 12 includes four image frames, and Fig. 13 includes three. For each frame, the left indicates the frame at time t - 10, and the right indicates the frame at time t + 10. Each image displays the historical trajectory sequence, actual future trajectory sequence, and predicted future trajectory sequence of the target pedestrian. For Fig. 12, we give both the position of the pedestrian at time t0 and the predicted future trajectory sequence at this time. For Fig. 13, the middle image demonstrates the predicted future trajectory sequence at time t0. In these diagrams, blue lines depict the pedestrian’s historical trajectory sequence, green lines represent the actual future trajectory sequence, and red lines illustrate the predicted future trajectory sequence.
In studies related to pedestrian trajectory prediction, traditional prediction methods based on shallow learning have achieved satisfactory prediction results in handling simple or standardized problems. However, when faced with real-life complex traffic scenarios, the prediction accuracy would be limited and the generalization capability of the shallow learning model is relatively weak. Most trajectory prediction methods based on deep learning overly simplify the pedestrian and environment feature information; some models lack a description of crucial movement information. For instance, S-LSTM and G-LSTM methods overly rely on location information and cannot adequately express the actual conditions in complex traffic scenarios.
In contrast to a single prediction network, our research breaks away from prior studies on pedestrian trajectory prediction, proposing a newly developed deep learning-based SGPN model. Firstly, this model combines the feature extraction capability of CNN and the superior handling of sequence data by LSTM, thereby adapting better to the trajectory prediction task. The design of LSTM network has been revised, and LSTM was optimized twice to resolve the feature expression issue of an individual pedestrian in the time domain and a group of pedestrians in the space domain respectively. Secondly, we introduced a dual attention mechanism for the model to itself and the scene, aiding the model in adaptive feature selection and weighting allocation of the information in history. The dual attention mechanism avoids insufficient scenario descriptions and inadequate descriptions of pedestrian states potentially caused by a singular attention mechanism.
Four structural parts of SGPN have undergone deep optimization and are provided with specific mathematical formulas. These improvements will help enhance the accuracy of prediction. Our model possesses high accuracy when predicting pedestrian trajectories and has been supported through numerous experimental investigations. Section 6.1 and 6.2 provide a quantitative and qualitative analysis of the model respectively, enabling a precise evaluation of the strengths and weaknesses of the model. The prediction accuracy errors ADE and FDE of our model are 0.40 and 0.68 respectively, significantly superior to other algorithmic models. This paper surpasses traditionally oversimplified prediction models, accurately depicting pedestrian movement patterns in real-life scenarios.
Understanding and modeling the uncertainty in individual behaviors is crucial for enhancing the accuracy of pedestrian trajectory predictions. Although our SGPN model, with its dedicated modules, learns the interactions between pedestrians and their environment from historical data, thus effectively handling some uncertain factors and predicting trajectories in complex scenarios, there is still room for improvement in learning efficacy under data scarcity conditions. Tutsoy et al. [35] introduced an improved genetic algorithm coupled with fractional-order polynomial models for long-term multidimensional prediction, which has been particularly successful in addressing uncertainties in sparse data scenarios, and they have provided a stable polynomial parameter update mechanism to accommodate annual data refreshes. Their methodology offers insights into potential strategies for augmenting the adaptability of our model in uncertain contexts. For future work, we will consider incorporating a similar mathematical framework or algorithm within the FFM of our SGPN model to further enhance predictive accuracy under uncertainty.
Conclusion
In the context of autonomous driving, accurate prediction of pedestrian trajectories is crucial for mitigating road safety risks. While existing deep learning models have made advancements in many aspects, they typically fall short in adequately addressing pedestrian interactions in complex environments. Our proposed SGPN model employs an innovative LSTM cell structure optimization and an advanced dual-attention mechanism, substantially improving the accuracy of pedestrian trajectory predictions.
To enhance the comprehensive value of our study, a comparative analysis with other scholarly works was conducted. In the realm of pedestrian trajectory forecasting, deep learning-based methods such as S-GAN, S-LSTM, and FPL predominate. However, these models reveal constraints when addressing complex pedestrian interactions within intricate scenarios. Specifically, the existing models warrant enhancement in the domain of capturing pedestrian characteristic features and key interactive dynamics. In contrast, our research bolsters the learning capabilities of pedestrian features and delves deeper into pivotal interactions between pedestrians and environment. Utilizing datasets like the MOT16 pedestrian dataset and the Daimler pedestrian benchmark dataset, our SGPN yielded an average FDE of 0.68, which represents a notable improvement in performance over other models, with the next best model FPL achieving an average FDE of 0.76. These outcomes distinctly manifest the superior proficiency of SGPN in interpreting complex individual behavioral dynamics, as well as making a significant contribution to modeling spatial interactions, which includes both inter-pedestrian interaction and the pedestrian-environment interplay.
The model and methods proposed in our study have various potential extensions and applications for future research. Considering the integration of spatial and temporal information, our work holds significance for related research, providing theoretical support and practical insights. In future work, we plan to incorporate richer scene information and consider integrating the latest advancements in deep learning to enhance feature extraction effectiveness, thereby further improving the predictive performance and generalizability of our model.
Footnotes
Acknowledgments
Research supported in part by grant for the Key Research and Development Program of Shaanxi Province of China (2019GY-097, 2021GY-131), Yulin Science and Technology Plan Project (CXY-2020-037), Xi’an Science and Technology Plan Project (2020KJRC0068), and Innovation Capability Support Program of Shaanxi (2020TD-021).