
Abstract
In view of the problem that the traditional LANDMARC location algorithm has low indoor location precision and needs to arrange a large number of reference tags, this paper proposes an RFID positioning algorithm based on the integration of the electronic tracking and positioning system (ETPS), which uses the Gauss filter to carry out the sampling data of the reference label. Using the electronic tracking and positioning algorithm to estimate the signal strength of other locations to expand the signal database. The experimental results show that the algorithm improves the accuracy of the indoor location and reduces the workload of the layout of the reference labels. The completeness and effectiveness of the proposed algorithm are verified.
Keywords
Introduction
In order to achieve the deep intelligent information processing, many organizations build larger processing models (Preston, 2015). RFID Positioning Algorithm Based on the Integration of Electronic Tracking System can effectively improve the accuracy of indoor positioning. This algorithm can carry out positioning work in a short period of time and has positive and practical significance for indoor high-efficiency positioning. In recent years, there has been an increasing demand for indoor location information services such as personalized information delivery, medical services, target discovery, etc., both outdoor and indoor location information are indispensable (Cheng, 2014; Hamidi and Liveryman, 2017). Traditional satellite-based positioning technology such as the global positioning system (GPS) can well meet the needs of outdoor positioning, but when used in indoor positioning, the positioning capability is greatly limited due to the influence of buildings on satellite signals (Cheetahs and Sadeh 2011; Al and Cul-de-Sac, 2016; Angus, 2014). Positioning technologies widely studied at present include infrared technology, visual positioning technology, ultrasonic technology, ultra-wide band (UWB) technology, wireless sensing networks (WSN), radio frequency identification (RFID), Beige and wireless local area networks (WLAN) positioning technology, etc. (Bains and Cadenza, 2016; Melodramas, 2013) Among them, radio frequency identification (RFID) positioning technology, with its advantages as non-contact, non-line-of-sight, high sensitivity and low cost, has become a hot technology of indoor positioning system and received more and more attention from people (Bu, 2015; Apostolic and Torres, 2011). At present, the common electronic tracking and positioning technologies include infrared-based positioning technology, ultrasonic-based positioning technology, ultra-wide band-based positioning technology, radio frequency identification and positioning technology and so on. RFID identification and positioning technology is easy to implement, with relatively high positioning accuracy and low cost. Hence, it is relatively suitable for use in the indoor positioning systems. Among them, it is especially suitable for ZigBee technology. However, the design improvement of ZigBee indoor positioning system still needs further research and development. It will be a good case study and application of the RFID technology.
In view of the problem that the traditional LANDMARC location algorithm has a low indoor location precision and needs to arrange a large number of reference tags, this paper proposes an RFID positioning algorithm based on the integration of the electronic tracking and positioning system (ETPS). This algorithm which replaces the linear interpolation method with the ETPS can better meet the actual signal propagation loss; meanwhile, when constructing the relationship between physical location and RSS value function, through differential evolution improved genetic optimization algorithm (DEIGOA) optimizing the parameters of support vector regression (SVR) it improves the precision of the positioning algorithm.
RFID algorithm principle of electronic tracking and positioning system (ETPS)
Gaussian filter
When selecting certain reference label for RSS value collection, to ensure data accuracy, multiple groups of collections are required to better acquire the real data of the signal intensity affected by various factors of the indoor environment. However, RSS distance measurement may be interfered by many factors. In different environments the external interference factors are also different, which leads to the fact that the same RSS value may correspond to a number of different locations. These phenomena have destroyed the correspondence between the distance and the signal strength value, causing great error to the measured distance. Assuming each measurement is independent, RSS value can be regarded as a normal distribution. Through Gaussian filter method, some mutational small probability interference terms can be filtered out to finally obtain a RSS Value which can smoothly and truly reflect the sampling point attributes so as to provide precise data support for the next stage of the estimation interpolation and database expansion. The fitting processing function is shown in formula (1) ∼ (3):
Where: μ represents the mean of the value of signal RSS received at this position; σ represents the standard deviation of the signal RSS value that this position receives; f (x) represents the density function of the measurement results at this position. Substitute the signal RSS value received at this position into the formula (1), when 0.6 ≤ f (x) ≤ 1, the signal strength value weighted average that meets the requirement is obtained as the final signal strength value of the reference label.
Aiming at the problem that intensive reference label assisted positioning is required in the LANDMARC, which has increased the interference of indoor signal propagation, the use of electronic tracking and positioning system (ETPS) is more flexible and inherited. After the interpolation nodes are increased, it only needs increasing part calculation on the original ones, and the residuals of the interpolation are also easier to be estimated. Therefore, the RSS value obtained by the ETPS is more in line with the actual environment, also improves the precision of the whole algorithm. Hence, the ETPS expansion signal database is adopted in this paper.
ETPS polynomial:
Where:
When the reader reading the RSS value of the labels, there are differences in all directions. Therefore, when calculating, take the reader as the center of the circle, divide each 90°area into 6 equal parts, that is, every 15°is taken as a calculation unit. The interpolation process is as follows:
After the establishment of the signal database, the key to solve the positioning problem is to obtain the functional relationship between the physical location and the signal strength. In the actual indoor positioning environment, due to the multiparty and shadow effects, the RSS values from the reference labels in the RF reader show nonlinear features. At present, in the mainstream methods, machine learning methods such as neural network, support vector machine etc. are adopted to fit the nonlinear relationship between the location and the signal strength. As a typical learning algorithm, the artificial neural network has the strong adaptability to the environment and low complexity, but poor generalization ability and low positioning precision. This paper adopts the support vector machine regression algorithm to build the nonlinear mapping relationship between signal RSS value and physical location and effectively improve the precision of positioning algorithm by lower algorithm complexity.
Assuming s = [s1, s2, …, s
n
]
T
is the vector composed by the signal strength received by the reference label from n RF readers at the location (x, y). The RSS signal and the physical location show a non-linear mapping relationship. Assuming that the relationship between the physical coordinates and the RSS is as shown in formula (5):
Where: f (·) and g (·) are both non-linear functions, with the y-axis coordinate as an example. Through a nonlinear mapping φ (s) the data input into the sample space are mapped to a high-dimensional feature space. In this case, transform the nonlinear function to a linear relationship, in high-dimensional feature space construct regression estimation function:
Where: w is the weight vector, its dimension number is the same as φ (s), is biased constant. The training goal is to solve the optimal value of w and b, so to make the generalization performance of SVR best. The generalized performance of regression learning function can be estimated by expected risk function R (w) of regression study.
In formula (8): {f (s, w)} is a set of predictive functions that can represent any set of functions; L (y, f (s, w)) is the difference caused by predicting the output y with {f (s, w)}, that is, the loss function. The ɛ insensitive SVR is introduced to correct the loss function; when the difference ɛ between the predicted value and the actual value less than the loss function value equals to 0, it improves the sparseness of regression estimation to a certain extent. F (s, y) is the joint probability density distribution between the signal strength and the y coordinates. We can apply the principle of structural risk minimization to obtain the optimal value of the expected risk function and introduce the relaxation factors ξ
i
and
Where: ∥w∥ controls the size of the confidence range,
Where: NSV represents the samples x
i
on the ɛ- band boundary, namely the standard support vector set; α
i
is Lagrange Multiplier. φ (s)
T
φ (s
i
) can be obtained by the kernel function calculation instead of the explicit calculation. Gaussian kernel has a good local feature extraction ability to accurately describe the relationship between RSS and the physical location, so this paper selects the Gaussian kernel as the kernel function of SVR.
Where: K (,) and g are the kernel function and the corresponding kernel parameter, respectively. Formula (10) can be transformed to:
Given parameters C, g, ɛ convex quadratic optimization is performed on formula (9), can get the global optimum of support vector machine weight w. The solving process of x coordinate is similar to the above method.
In the SVR modeling process, the penalty parameter C, kernel function parameter g and insensitive coefficient ɛ are the main factors affecting the performance of SVR. The so-called SVR parameter optimization selection is to identify the optimal combination of parameters (C, g, ɛ), make SVR have the best regression performance and improve the SVR learning and generalization ability. In view of the SVR parameter optimization problem, this paper uses differential evolution improved genetic optimization algorithm (DEIGOA) to optimize SVR parameters.
GWO optimization algorithm features simple structure, few parameters to be adjusted, etc. At the same time, its convergence precision and convergence speed are superior to those of the other swarm intelligence algorithms. In the GWO algorithm, the genetic algorithm is mainly divided into four levels as α, β, δ, ω, of which the α wolf level is the highest, responsible for the control decision-making in the optimization process. The algorithm mainly realizes optimization purpose by the process of wolf pack tracking, surrounding, chasing, attacking prey etc.
In the hunting process the wolf pack firstly surrounds the target, the mathematical model of the process is as follows:
Where: A and C represent coefficient; t represents the current number of iterations; X
p
represents the prey location; X represents the genetic location. The mathematical calculation formula of A and C is as follows:
Where: Itermax is the maximum number of iterations, the value of a decreases linearly from 2 to 0; r1 and r2 are random vectors in the interval [0,1]. After surrounding the prey, genetic pursuit is carried out. To better search for the location of the prey, this process is usually led by α, β and δ, in this phase, the wolf pack location updating expression formula is:
Where: D α , D β , D δ are the distance between other genetics and α, β, δ; X (t + 1) is the genetic location after the update.
When attacking prey, the genetics ceaselessly decrease the value of the parameter a linearly. And random values are also taken for A in the interval [–2a, 2a]. When |A| ≤ 1, the wolf pack focuses on attacking the prey. When |A| > 1, the genetics abandon the prey and look for other prey i.e. local optimal solution.
In this paper, the differential strategy of differential evolution algorithm is introduced. Through the mutation, crossover and selection process in this algorithm, it makes the algorithm jump out of the local optimum, and makes full use of the advantages of the differential evolution algorithm in local optimization to improve the optimization precision of the algorithm. The mutation operation of the DE algorithm is as follows:
Where: vi,G+1 is the new individual mutated by the G generation of individuals; F is a scaling factor, which makes zoom in and out control for the difference vector.
To improve the diversity of the population, the cross-operation mode is:
Where: ui,G+1 is the new individual produced by the G-th generation of genetic mutant and (G+1)-th generation of genetics crossing; rand (j) is a random number between [0,1]; CR represents the cross probability factor in [0,1]. Larger CR is conducive to the local search and faster convergence; smaller CR is conducive to the global search and maintaining population diversity.
Simulation environment
In order to verify the performance of the proposed RFID positioning algorithm based on the electronic tracking and positioning system (ETPS), this paper uses MATLAB on PC with main frequency as 2.50 GHz and 2.49 GHz and Inteli5 dual-core CPU and 3.89GB memory for positioning simulation experiment. Simulink is a visual simulation tool in MATLAB. It is a block diagram design environment based on MATLAB and a software package for dynamic system modeling, simulation and analysis. It is widely used in linear systems, nonlinear systems, digital control and digital signal processing modeling and simulation. The simulation layout is as shown in Fig. 1: arrange 4 readers and 16 reference labels in a space of 8 m×8 m, the adjacent reference labels evenly spaced apart by 2 m, arrange 16 labels to be positioned and 4 readers on the boundary of the indoor environment, assuming able to detect all the labels. The readers respectively measure the RSS value of each reference label and the label to be positioned for experimental simulation.
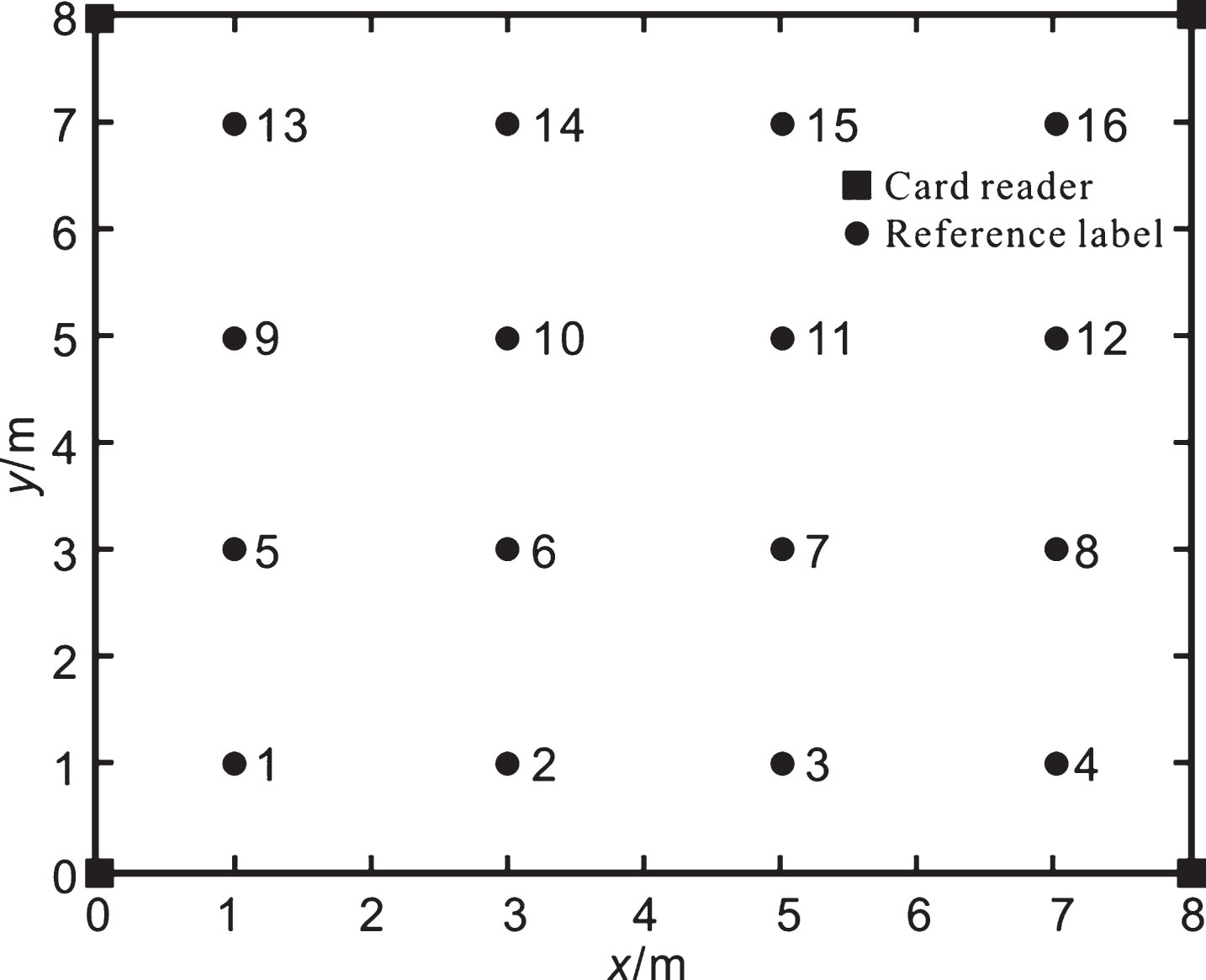
Simulation Layout Chart.
In order to verify the positioning performance of the proposed algorithm, this paper also adopts the traditional LANDMARC algorithm and VIRE algorithm for positioning simulation. In ETPS algorithm, the population number is set as 50, the maximum number of iterations is 200, the interval of the scale factor F is [0.2, 0.8], and the crossover probability CR is 0.2. LANDMARC neighboring reference label number is set as 4. In the VIRE algorithm N is set as 3. The LIBSVM toolbox is used in the experiment.
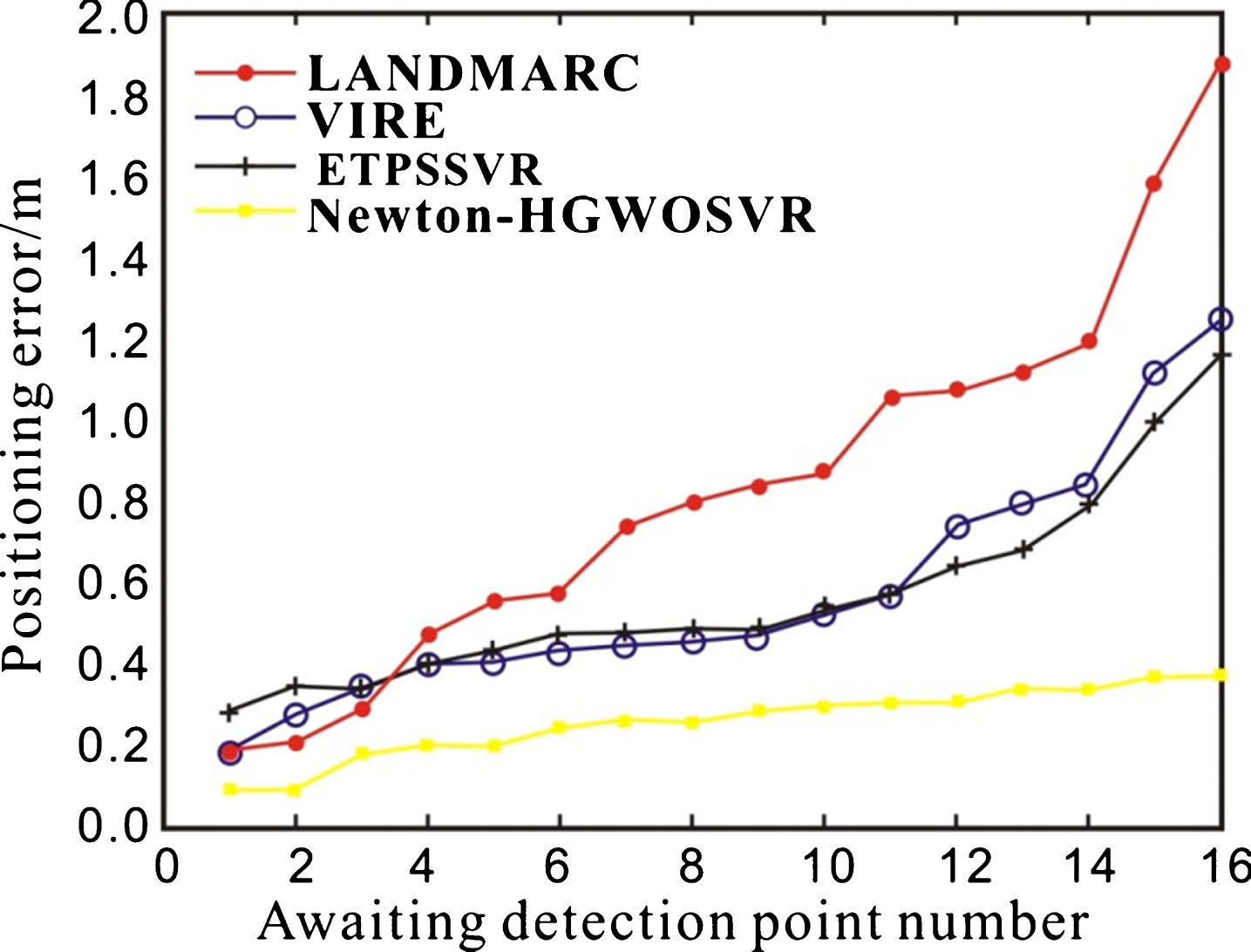
Figure 2 shows the positioning error diagram for the sorting of the positioning error of each label to be detected in an ascending order. From Fig. 2 it can be seen that compared with LANDMARC algorithm, great improvement has been achieved in several algorithms. Among them, the ETPSSVR algorithm has the smallest positioning error, and the positioning error has been significantly improved compared with that of the SVR algorithm using grid search. It indicates that adopting DE to improve GWO method and optimize the SVR parameters can effectively reduce the positioning error. However, due to the limited number of reference labels for offline training, the precision of grid search SVR method is not as high as that of VIRE algorithm.

Positioning Error Comparison Chart.
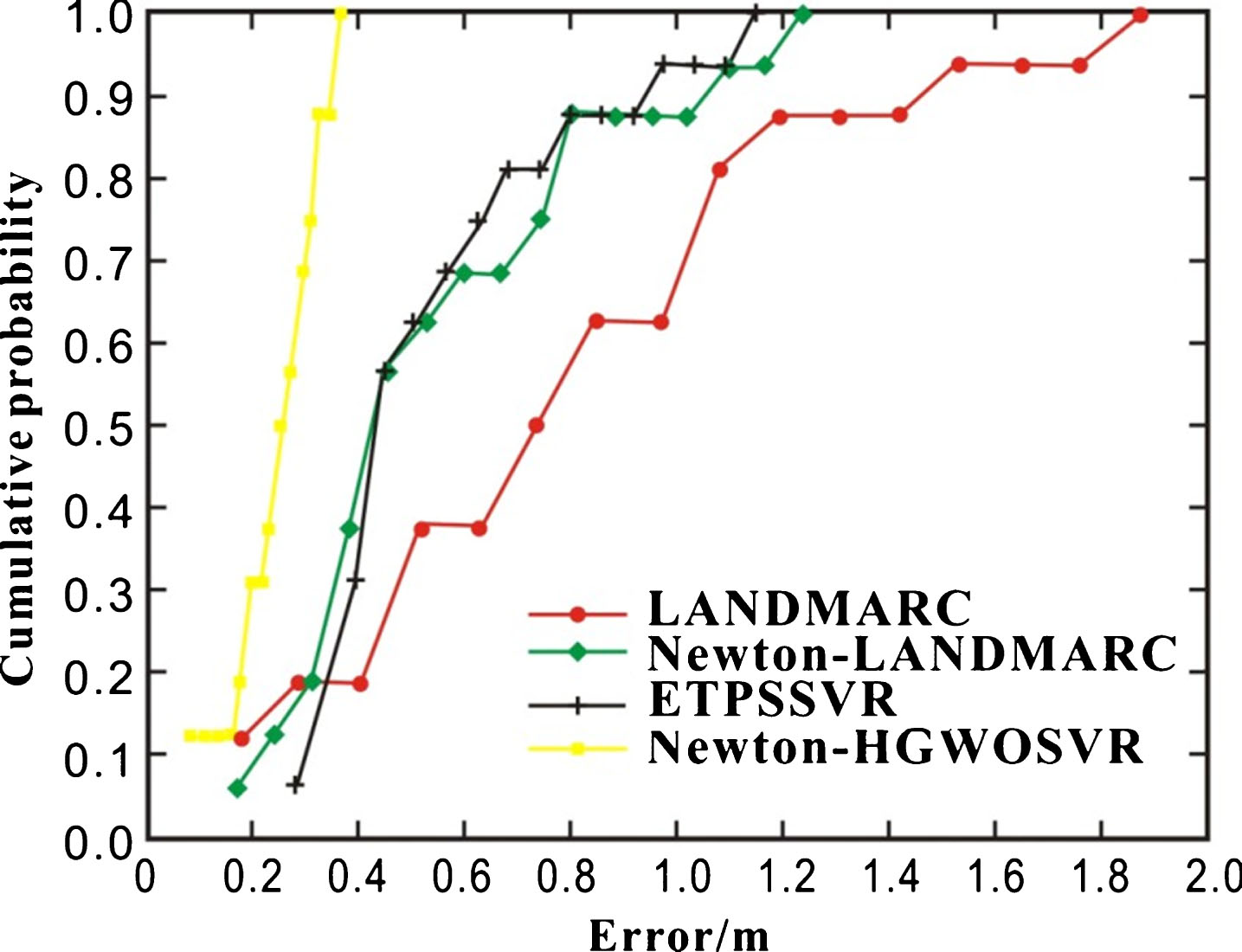
Figure 3 is the positioning error cumulative probability curve for various algorithms. When the average error is within 0.8 m, the cumulative probability of ETPSSVR algorithm is about 80%, while the cumulative probability of grid search SVR, VIRE and LANDMARC algorithm are respectively 60%, 65%, 50%. Although the ETPSSVR algorithm is inferior to the other three algorithms in the waiting fixed point number, the ETPSSVR algorithm has good positioning performance.

Positioning Precision Comparison Chart.
Figures 4 and 5 show the comparison of the error and positioning precision before and after expanding the RSS database by the LANDMARC algorithm and ETPSSVR algorithm adopting electronic tracking and positioning system (ETPS). From Fig. 4, it can be seen that after adopting ETPS expansion database the positioning error is reduced, the error of RFID algorithm of ETPS is obviously less than that of ETPSSVR. However, the positioning precision is lower than that of the LANDMARC algorithm. In Fig. 5, the algorithm proposed in this paper can reach more than 95% within 0.4 m error, while the positioning precision of the three algorithms as Newfoundland, ETPSSVR and LANDMARC are 40%, 30% and 15% respectively. It indicates that using Newton expansion database can improve the positioning performance of the positioning algorithm, and means that under the premise of ensuring the positioning precision it can decrease the number of arranging reference labels by ETPS mode.
Comparison of Positioning Error Before and After Expanding Database.
Comparison of Precision Before and After Expanding Database.
Comparison of algorithm comprehensive performances
To compare the comprehensive performance of the algorithms, Table 1 sets out the indicators such as the maximum error, average error, training time, prediction time, etc. of several algorithms. It can be seen that the RFID algorithm based on electronic tracking and positioning system (ETPS) proposed in this paper has much smaller positioning error than that of the other algorithms. The positioning precision is also superior to that of the other algorithms. However, the proposed method requires training the collected sample data in the offline phase to construct a reasonable ASS-location model, thus consuming part of the computational expenditures. However, compared with the other algorithms, the prediction time is not long. Although the real-time performance is slightly lower, the effect of improving the positioning precision and reducing the workload of arranging dense reference labels is very good. In summary, the proposed RFID algorithm based on electronic tracking and positioning system (ETPS) has better positioning performance.
In view that the traditional LANDMARC location algorithm has low indoor location precision and needs to arrange a large number of reference tags and other problems, an RFID positioning algorithm based on the electronic tracking and positioning system is put forward in this paper. According to the analysis of the principle of RFID algorithm based on the electronic tracking and positioning system, the algorithm firstly performs interpolation expansion on the pre-processed RSS value during the offline phase through the ETPS; then uses ETPSSVR to construct the nonlinear predictive relationship between the physical location and RSS, and perform optimization on the SVR parameters of the ETPS algorithm. The experimental results show that the positioning precision of the proposed RFID positioning algorithm based on electronic tracking and positioning system (ETPS) algorithm is higher than that of the traditional LANDMARC, VIRE algorithm and grid search SVR positioning algorithm. It not only improves the positioning precision, but also reduces the number of reference labels for arranging to a certain extent, thus has a better positioning performance.