
Abstract
Most people primarily rely on subjective opinions and action assessment from others in the process of learning badminton, which leads to biases and unreliable assessment of player performance. This paper presents a method of deep learning-based recognition and quality assessment of badminton actions to accurately identify player actions and assess player performance. In this research, we construct a video dataset of standard badminton actions for training networks and design a human pose estimation and tracking network to detect keypoints of individual players in the video dataset and track their trajectories. Furthermore, badminton action recognition is carried out based on the SlowFast network framework, and a Siamese network with it as the backbone network is proposed for automating the quality assessment of badminton actions. Experimental results demonstrate that the mean average precision (mAP) of human body pose estimation reaches 83.2%, the Multiple Object Tracking Accuracy (MOTA) of pose detection and recognition in badminton games reaches 81.4%, and the Multiple Object Tracking Precision (MOTP) reaches 90.7%. The accuracy of professional players in identifying badminton strokes is 83.08% for Top-1 and 96.89% for Top-3. Therefore, the proposed method can be effectively applied to badminton action recognition and quality assessment.
Introduction
Badminton is a prevalent racquet sport, with a significant number of people getting involved every year. However, during the learning process, placing excessive reliance on subjective opinions provided by coaches can lead to biases and unreliable assessment of player performance. This results in significant variations in the basic badminton actions among different players. In reality, during the early stages of learning badminton, the correctness and standardization of movements are crucial, as they will determine the potential for future improvements in technical skills. Therefore, there is a need for an objective and reliable method to assess badminton actions in order to enhance training and teaching effectiveness.
Deep learning has increasingly been applied in sports science, offering promising solutions for action recognition and quality assessment.1–3 Due to its capacity to identify patterns within data using multi-layered neural networks, deep learning is particularly effective at evaluating the actions of badminton players. This allows for objective and quantifiable assessments of performance, which can be used to provide personalized feedback and improve player development. By enabling access to more accurate and detailed information, deep learning has the potential to revolutionize the field of badminton training and teaching.
However, deep learning-based action recognition for badminton faces the challenge of insufficient annotated data, which is crucial for training models and ensuring accuracy and generalization ability. The types of badminton action data primarily encompass data derived from wearable sensors and video-based data. While wearable sensor data holds potential in badminton action recognition,4,5 it also comes with certain limitations. Wearable sensors have limited perspectives and information dimensions, which can result in partial information loss or difficulty capturing specific actions. Moreover, sensor data can be susceptible to noise and drift, leading to inaccurate action recognition outcomes. More importantly, acquiring wearable sensor data necessitates players to wear sensors actively, which can affect their comfort during sports. The use of video-based badminton action data can universally address these issues.
Another key challenge is the absence of a suitable network model for autonomously identifying and quantitatively assessing badminton actions. Badminton actions come in various forms, encompassing different strokes, footwork, and postures. Developing a matching deep learning model capable of encompassing and accurately recognizing all these actions is complex.
To address above challenges, our work is dedicated to exploring and developing novel deep learning models and methods for recognizing and evaluating badminton actions. In this work, we first set up a video collection environment to collect standard badminton action videos of players, and standardized action cutting and labeling are performed on the collected video data to build a preliminary dataset of standard badminton action videos. Next, we design a deep network model based on Convolutional Neural Networks (CNN) for human keypoints detection of players and design a human pose tracking network based on the Spatial Temporal Graph Convolutional Network (ST-GCN) 6 to match the motion trajectory of a single individual for better recognition of specific badminton actions. In order to further reduce background interference caused by inaccurate action recognition, we use the SlowFast 7 network structure, which analyzes the static information in the video using a slow high-resolution CNN channel (Slow pathway) and analyzes the dynamic information in the video using a fast low-resolution CNN channel (Fast pathway). Finally, in the quality assessment stage of badminton actions, we design a Siamese network with the SlowFast network as the backbone network to compare the input actions with those of professional badminton players, and thus obtain reasonable scores. The actions of professional players have been validated through extensive training and competition, demonstrating a high level of technical proficiency and stability, which provides a reliable benchmark for our assessment. The deep learning framework we have developed not only helps coaches to assess badminton actions of players, but also allows players to make pose corrections according to the changes of keypoints.
Our main contributions are summarized as follows:
We preliminarily construct a video dataset of standard badminton actions and use it to train and validate our badminton action recognition and quality assessment network. We have constructed an end-to-end quality assessment network framework of badminton actions based on deep learning. Specifically, we design a human pose estimation and tracking network to detect the keypoints of individual players in the video dataset, and use the analysis of keypoint differences to guide players to make correct badminton actions. We use the SlowFast network framework for badminton action recognition and propose a Siamese network with it as the backbone network. We use this Siamese network to compare the differences between actions of players and standard actions, thereby achieving automated quality assessment of badminton actions. Experimental results show that our work is reasonable and can be applied effectively in deep learning-based badminton action recognition and quality assessment.
Related works
Sports dataset construction
Currently, the relevant datasets for sports scenes are not yet complete. In order to use deep learning networks for the recognition, detection, and other related tasks of specific sports actions, it is necessary to construct specific sports datasets further. Parmar et al. 8 created a multitask dataset including seven tasks like diving and skiing. They used the C3D network as the backbone network to predict scores for the seven sports. Shao et al. 9 proposed a large-scale, high-quality, hierarchical annotated dataset for fine-grained gymnastic actions named FineGym. They also analyzed existing action recognition methods from multiple levels and perspectives. Xu et al. 10 constructed a fine-grained competitive sports video dataset, FineDiving, and designed a more reliable and transparent scoring method. FineDiving focuses on various diving events. The dataset constructed by Ban et al., 11 BadmintonDB, includes multi-stroke rallies, stroke actions, and outcome annotations from nine real badminton matches between top players, which can be used for predicting professional players’ performance. However, since it does not contain action samples from non-professional players, BadmintonDB has certain limitations in terms of action recognition and quality assessment. The dataset proposed by Li et al. 12 focuses on badminton videos, providing a diverse, action-centric data. In our work, we focus on badminton action recognition and quality assessment and construct a video dataset of standard badminton actions.
Human pose estimation and tracking
According to the different processes of image processing, human pose estimation is generally divided into top-down methods13–17 and bottom-up methods.18–22 Sun et al. 13 proposed the HRNet, a high-resolution network that achieved a reliable high-resolution representation through parallel multi-resolution subnets and repeated multi-scale fusion. Jingdong Digital Technology team 15 designed a Siamese Graph Convolution Network for human pose tracking, which effectively captured the similarity of human poses based on skeletal representation. Snower et al. 16 designed a simple and efficient tracking network, KeyTrack, based on Transformer, 23 which used only the detected keypoint information in the tracking phase. Raaj et al. 21 proposed a spatiotemporal affinity field (STAF) structure that can encode across video sequences, as well as a novel cross-limb temporal topological graph.
Action recognition and quality assessment
Action recognition and quality assessment are essential and challenging tasks in computer vision. Deep learning-based approaches have achieved state-of-the-art results in Action Recognition24–31 and Quality Assessment.32–34 Pallabi Ghosh et al. 24 proposed a spatial-temporal graph convolutional network (GCN) that learns to capture the long-term dependencies between body parts for action recognition. Reference 26 proposed PoseConv3D, a novel skeleton-based action recognition method. PoseConv3D is more effective in learning spatiotemporal features, more robust to pose estimation noise, and demonstrates better generalization in cross-dataset settings. Rahmad et al. 28 developed an automatic badminton action recognition model based on a deep learning pretrained AlexNet convolutional neural network (CNN) for feature extraction, with features classified using an SVM. However, this work only supports the recognition of two action classes. Gao et al. 32 modeled the asymmetric interactions among agents for action quality assessment. They proposed an asymmetric interaction module (AIM) to explicitly model asymmetric interactions between intelligent agents within an action, where they grouped these agents into primary and secondary ones. Bai et al. 34 proposed a temporal parsing transformer to decompose the holistic feature into temporal part-level representations. They utilized a set of learnable queries to represent the atomic temporal patterns for a specific action, and adopted the state-of-the-art contrastive regression based on the part representations.
Our approach
Our research utilizes deep learning techniques in computer vision to analyze badminton technical actions. It involves constructing a standard technical action video dataset for badminton, designing a baseline for human pose estimation and tracking, action recognition and quality assessment. The dataset is constructed by collecting and annotating videos of technical standard actions. Subsequently, a series of deep neural networks are trained for human pose estimation, tracking, action recognition, and action quality assessment. Our work represents a significant advance in the automated recognition and quality assessment of badminton actions, demonstrating the potential of deep learning techniques in enhancing badminton education.
Badminton action video dataset construction
We construct a video capture environment to shoot videos of professional players and non-professional badminton enthusiasts. The advantages of our dataset over existing datasets are reflected in the multi-angle video capture, standardized action annotation, the inclusion of negative samples, and the classification of actions specific to badminton. We use a multi-angle method for professional players, capturing videos from the front, back, left, and right perspectives. These videos, along with those of famous badminton players from major international competitions, are used to construct the badminton technical standard action video dataset. Non-professional badminton enthusiasts use phones or cameras to capture videos with a single fixed viewpoint, which are only employed as negative samples in training the action scoring network model.
We adopt VoTT software 35 for both image-level and video-level annotation in the manual data labeling process. For image-level annotation, the position of each professional player in the multi-angle videos is labeled using VoTT software, along with ground truth labels for the coordinates of each keypoint for pose estimation. The image-level annotation adheres to the same standards as the COCO dataset. 36 Video-level annotation involves labeling successive frames in multi-angle videos of professional players using VoTT software. This process enables the representation of comprehensive technical action annotation. The video-level annotation categorizes actions into six categories 27 : serve a ball, hit a high ball, smash a ball, lob a ball, forehand pick a ball, and backhand pick a ball. Table 1 and Table 2 present the specifications of the video-level standard dataset. We employ a stratified sampling method to ensure that the training and validation sets contain an equal distribution of stroke categories. Specifically, we randomly select samples within each stroke category and divided them according to an 80:20 ratio, which prevents certain categories from being overly scarce in either the training or validation set.
Statistics on the number of stroke categories in the badminton video dataset.

Statistics on the number of stroke categories in the badminton video dataset.
Badminton video dataset video clip statistics.

Based on the human skeleton keypoint sequence, we perform pose estimation on labeled data captured from professional remote movements in front, back, left, and right views. The human skeleton keypoint sequence adopts keypoints consistent with the COCO dataset, with the skeleton diagram of these keypoints presented in Figure 1.
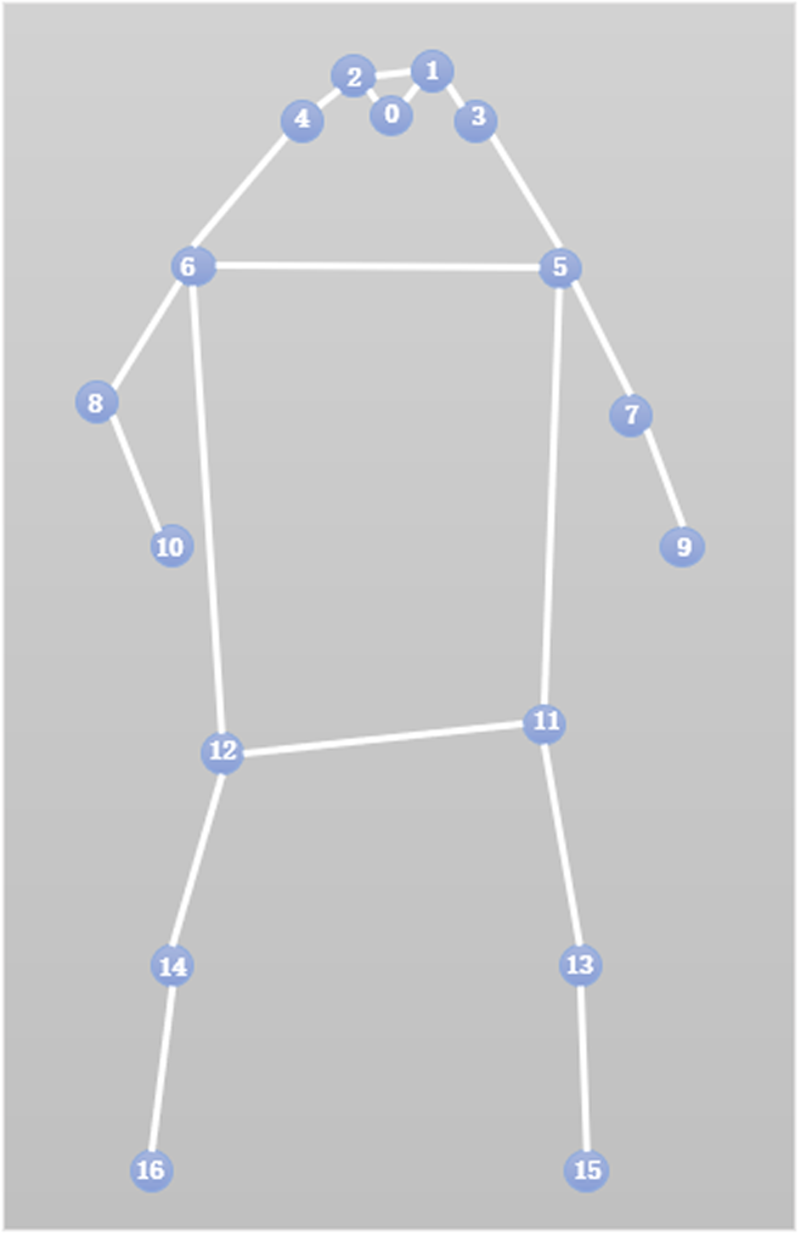
Keypoints of COCO dataset.
We adopt a top-down structure for the deep learning-based human keypoint pose estimation network utilized in this study. 37 In this paper, we introduce the use of the YOLO-v3 network 38 for human detection, which provides the human bounding box required for pose estimation. The image information within the bounding box is then upsampled or downsampled using functions from the OpenCV library to unify all images into human bounding box images of the same resolution size. This unified human bounding box is used as the input for the pose estimation framework.
To implement human pose estimation, we utilize the HRNet. 18 First, the pre-trained model obtained from the COCO dataset is employed to train the badminton technical action video dataset constructed in this study, obtaining the keypoint pose of badminton players. This approach helps prevent overfitting because the pre-trained model can learn more generalized features, improving its performance on smaller datasets. The fully convolutional layer outputs 17 keypoint heatmaps in the final output layer. Nevertheless, due to the limitation of HRNet in producing a heatmap resolution that is merely 1/4 of the original picture resolution, it becomes necessary to upsample the heatmap in order to acquire a heatmap with a higher resolution. The coordinate information of the keypoint is then obtained by taking the local maximum value of the obtained high-resolution heatmap. Figure 2 illustrates the structure of the HRNet, where the feature map is formed by stacking multiple frames of input images and is upsampled and downsampled through vanilla convolution operations to obtain the final output feature map.
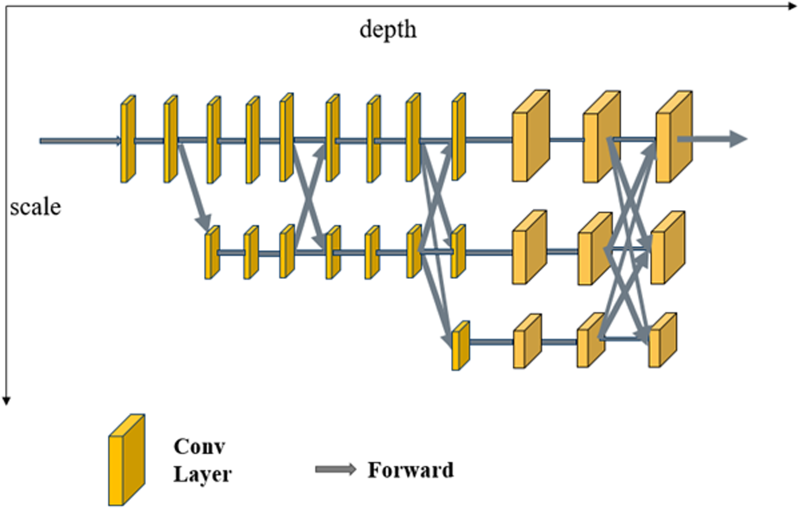
The structure of high-resolution network.
Considering spatial and pose-related dependencies, we propose a human pose-tracking network based on the Spatial-Temporal Graph Convolutional Network (ST-GCN). 6 The structure of the ST-GCN is shown in Figure 3.

Spatial-temporal graph convolutional network.
The proposed spatial-temporal convolutional network architecture is built upon the skeletal graph, where each node represents a human keypoint. As illustrated in Figure 3, the input skeletal feature data is first batch-normalized, with the input data being the keypoint coordinate vector on each graph node. The feature data is then sequentially fed into nine ST-GCN blocks, each comprising an attention module (ATT), a graph convolutional module (GCN), and a temporal convolutional module. Finally, a pooling layer is utilized to extract high-level features of 256 dimensions, followed by a fully connected layer for classification and label output. In the nine layers of ST-GCN blocks with identical structures, the outputs of the first three, middle three, and last three layers have 64, 128, and 256 channels, respectively. Additionally, after each ST-GCN block, a dropout operation with a random probability of 0.5 is employed to prevent overfitting. 39
A matching model is utilized for person re-identification following a spatial-temporal graph convolutional network. The matching model extracts features related to human pose, giving the results greater interpretability. Furthermore, the strong relationship between bounding boxes directly constrains them. Improved tracking performance is achieved by using the keypoints of the person to obtain the region of interest (ROI) while ensuring the distinction between candidate regions and employing pose features for skeleton-based pose matching.
This work collects video scenes with two distinct parts: static regions with little or slow changes and dynamic regions with continuous changes. Despite locating specific individuals using tracking models, irrelevant background regions still exist. To address this issue, the SlowFast 7 network is adopted for badminton action recognition.
The SlowFast network utilizes a slow high-resolution convolutional neural network channel (Slow pathway) to analyze the static content of the video while simultaneously utilizing a fast low-resolution convolutional neural network channel (Fast pathway) to analyze the dynamic content. The network structure is depicted in Figure 4.
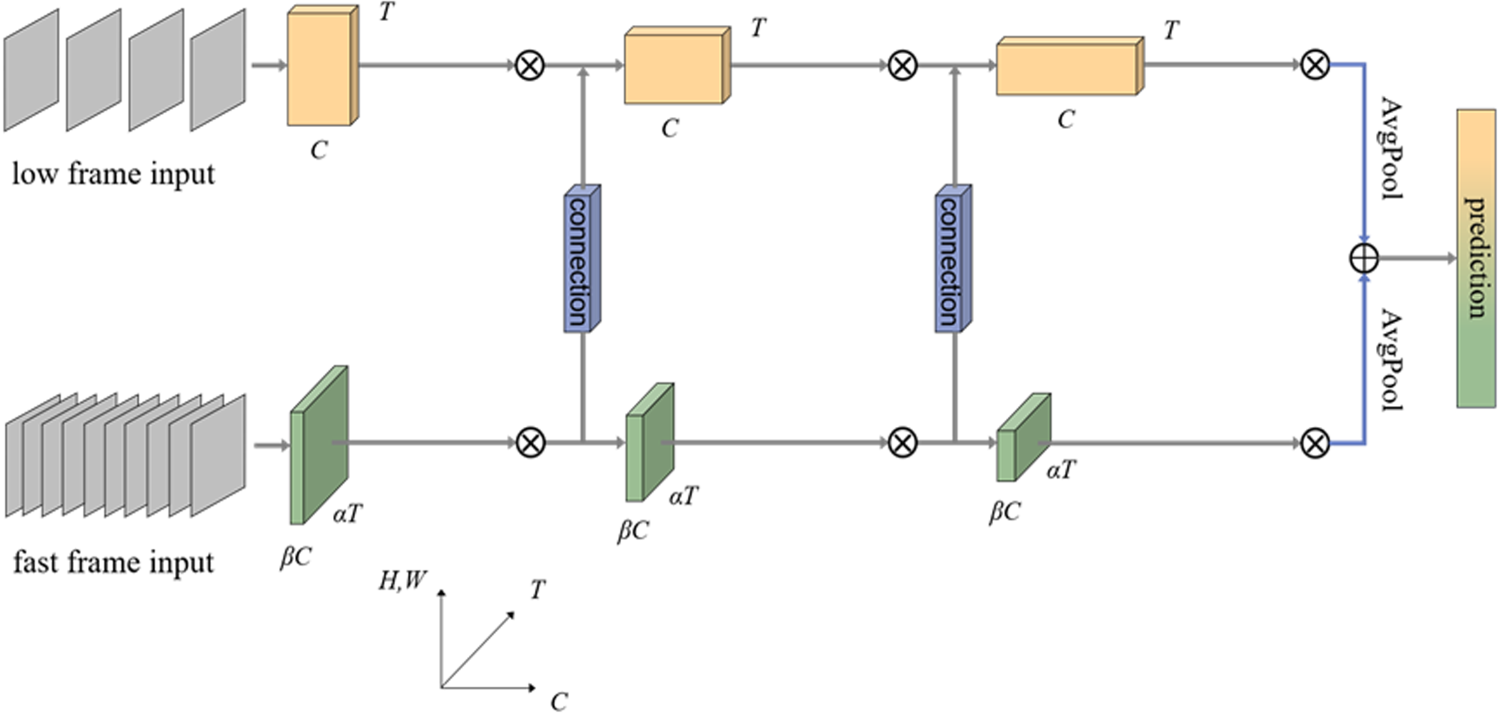
The structure of slowFast network.
Both the Slow pathway and Fast pathway use the 3D ResNet 40 model to extract features from the input continuous video frames after subsampling. The Slow pathway uses a larger temporal stride (the number of frames skipped per second), usually set to τ=16, which means that every 16 frames from the original continuous video frames are sampled and fed into the model. 7 The Fast pathway uses a very small temporal stride τ=16/α, where α is set to 8, meaning that every two frames from the original video frames are sampled. 7 To remain lightweight, the Fast pathway uses a significantly smaller convolutional width (number of filters) than the Slow pathway, usually set to β = 1/8 of the convolutional width in the Slow pathway. 7 The reason for using a smaller convolutional width is that the computation required by the Fast pathway is much less than that of the Slow pathway. As shown in Figure 4, where T represents the number of frames and C represents the feature dimension, the Fast pathway has eight times as many frames as the Slow pathway, but the feature dimension is reduced by 1/8. It can be inferred that the Fast pathway learns more temporal information from video frames, while the Slow pathway mainly learns spatial information.
For the badminton action quality assessment network, we regard professional players as positive samples, with their scores set as the maximum value achievable. Data from non-professional players is regarded as negative samples. For each action category, both positive and negative samples are fed into a Siamese network, whose backbone is the aforementioned trained badminton action recognition network. Through training with a contrastive loss function, the feature representations of negative samples closer to the standard form of professional players are pulled towards higher scores. In contrast, samples further from the standard are pulled towards lower scores. The scoring is based on the feature distance between the sample and the positive sample, with the mapping or scaling of this distance ensuring that scores fall within a reasonable range. Hence, a new sample of badminton action can be scored by comparing it with the standard form of professional players. Figure 5 shows the architecture of the action quality assessment network.
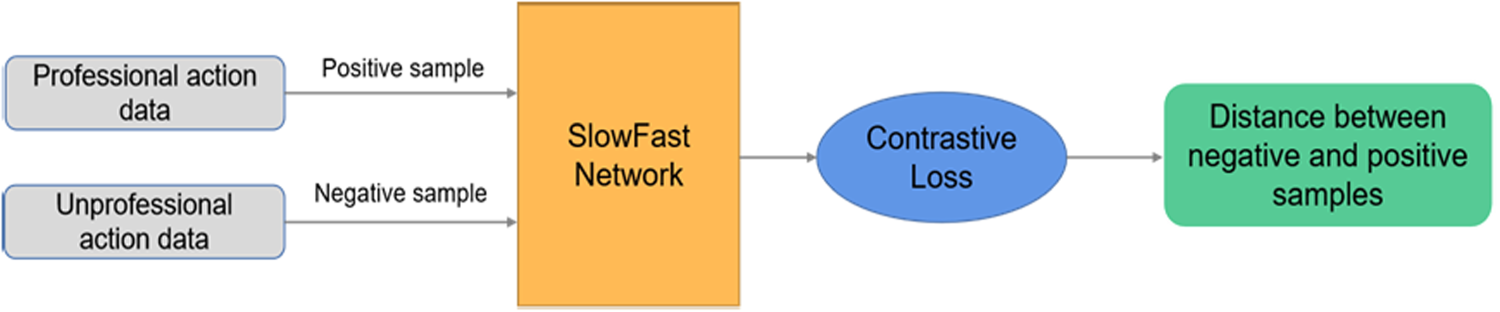
The structure of badminton action quality assessment network.
Evaluation metrics
Experiments utilize Mean Average Precision (mAP) 13 to measure the accuracy of multi-person pose estimation within frames, and multiple object tracking (MOT) metrics 15 are employed to evaluate pose tracking for all human joints independently. The primary metrics used to evaluate the performance of the human pose tracking network include Multiple Object Tracking Accuracy (MOTA) and Multiple Object Tracking Precision (MOTP).
The calculation of mAP involves averaging all AP metrics. To calculate the AP, assuming there are M positive samples among N samples, M recall values can be obtained, representing the proportion of correct results judged by the model out of the total observations. For each recall value, the corresponding maximum precision 
MOTA evaluates the tracking accuracy, which measures the ability to detect and maintain object trajectories. The calculation for MOTA is as follows:

In (2), 
In (3),
Our approach employs the badminton technique standard action video dataset to train the HRNet using a pre-trained model on the COCO dataset. The estimation accuracy of different human keypoints is shown in Table 3. The mean average precision of pose estimation is as high as 83.2%, indicating that our model can accurately estimate pose keypoints of badminton players in video datasets. As a result, our approach can achieve a superior human pose tracking effect. This capability is beneficial for subsequent keypoint-based pose tracking.
Human pose estimation results for badminton motion.

Human pose estimation results for badminton motion.
* The pose estimation accuracy of each part is listed in the table, and the final mean average accuracy is calculated.
According to the training results of our network on the dataset in Table 4, the MOTA of our model is reported to be 81.4%, with a MOTP of up to 90.7%. These indicate that our network can effectively and consistently track the position of each target during the hitting process of badminton players.
Human pose tracking and human action recognition results for badminton motion.

* Top-1 accuracy is the largest one in the last probability vector of the predicted label, which is taken as the predicted result. If the classification with the largest probability is correct, the prediction is correct, otherwise the prediction is wrong. Top-3 accuracy is taking the Top three probabilities with the largest final probability vector among the predicted labels. If the three probabilities contain the correct classification, the prediction is correct, otherwise it is wrong.
In the action recognition task, we focus on detecting and tracking the badminton strokes of players. Through parameter settings and training with appropriate data, our model is designed to detect and track the actions of the target-hitting player, achieving our expected effect. Building on this foundation, our work aims to recognize the strokes of the detected target-hitting player. We utilize both positive and negative samples to accomplish this aim. When assessing the quality of positive sample actions, we set the actions of professional athletes as the full score standard, and other samples are scored based on their similarity to professional actions. We input these samples into the Siamese network for badminton action recongnition and quality assessment.
Table 4 shows the results for action recognition. The Top-1 accuracy is calculated at 83.08%, indicating that our model correctly detects the label with the highest probability of 83.08%. Similarly, the measurement of Top-3 accuracy yields a value of 96.89%, denoting that the top three recognition probabilities, which encompass the true label, exhibit an accuracy rate of 96.89%. These results demonstrate the effectiveness of our approach, which achieves high recognition accuracy for badminton actions of players.
Figure 6 illustrates the confusion matrix for the badminton action recognition model. Each cell displays the model's recognition performance for different action categories in decimal format. The values on the diagonal represent the model's correct recognition rates for each category, with the ‘Smash a ball’ category achieving the highest recognition rate of 85.0%. In comparison, the ‘Hit a high ball’ category has the lowest recognition rate at 80.0%. As shown in Figure 6, the model performs well across most action categories, but there is notable confusion in the ‘Hit a high ball’ category. This information provides valuable insights for further model improvement and data processing optimization.
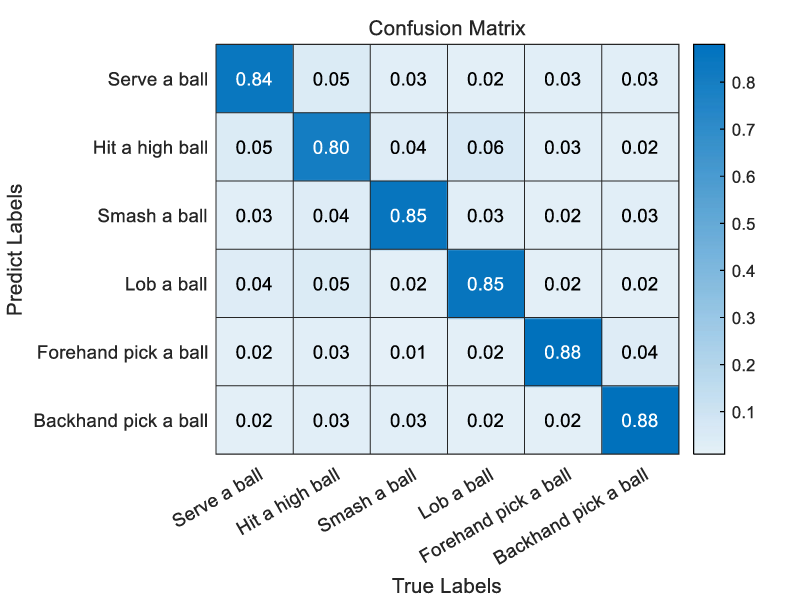
Confusion matrix of badminton action recognition.
In this work, we assess the quality of badminton actions in the test videos using a standardized dataset. Results of our quantitative experiment are presented in Figure 7–13, where each human target is identified and evaluated based on the consistency of their badminton movements. The higher the standard and consistency of the movements, the higher the final quality score. However, when we applied our action quality assessment method to professional players in actual competition (Figure 12, left), we observed a lower quality score of only 78.74%. This indicates that strokes can vary to different degrees in real-life competitions, unlike the standardized dataset used in our study. Our dataset is based on the most standardized and optimal physical condition of players, and our research has implications for both badminton training and quality analysis of competition actions.
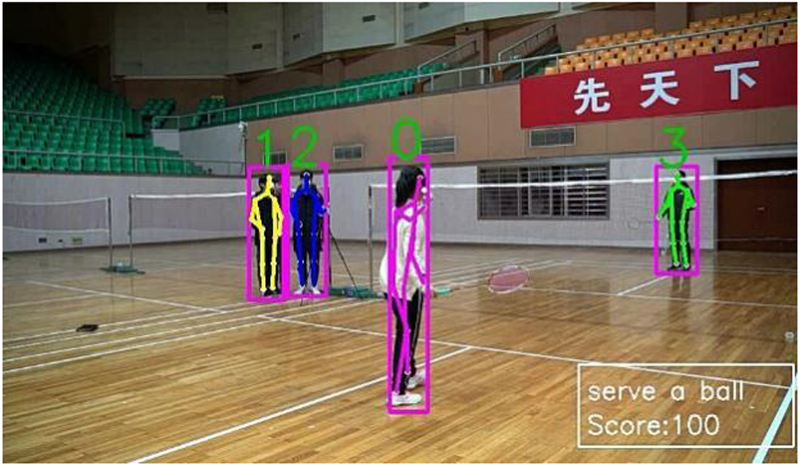
Positive sample serve and score.
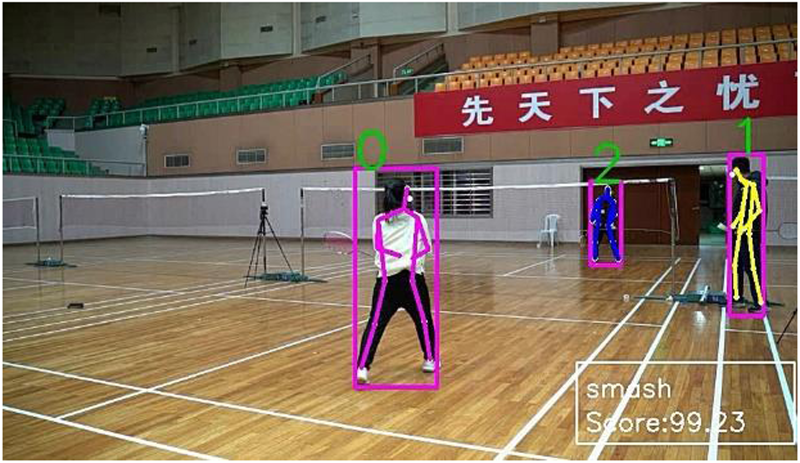
Positive sample smash and score.
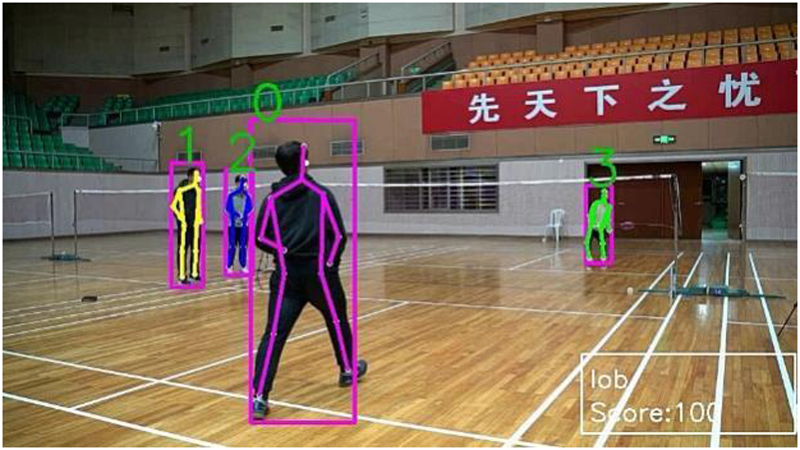
Positive sample lob and score.
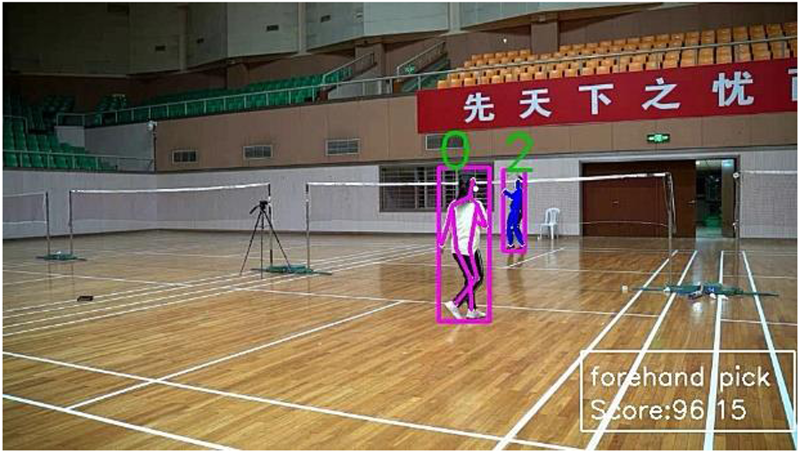
Positive sample forehand pick and score.
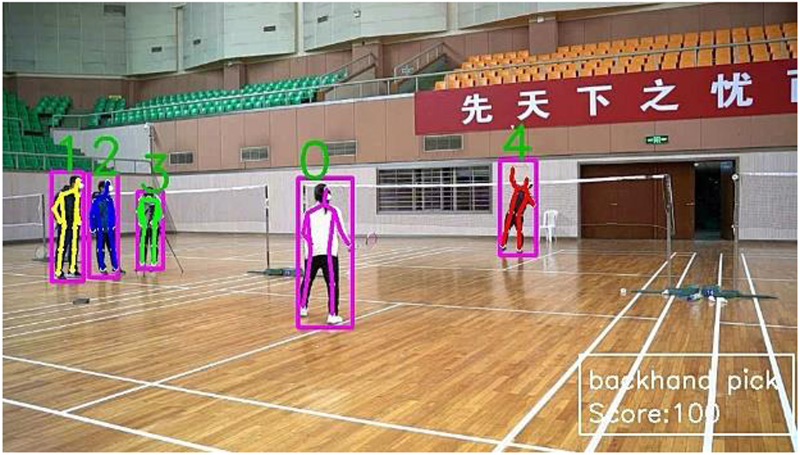
Positive sample backhand pick and score.
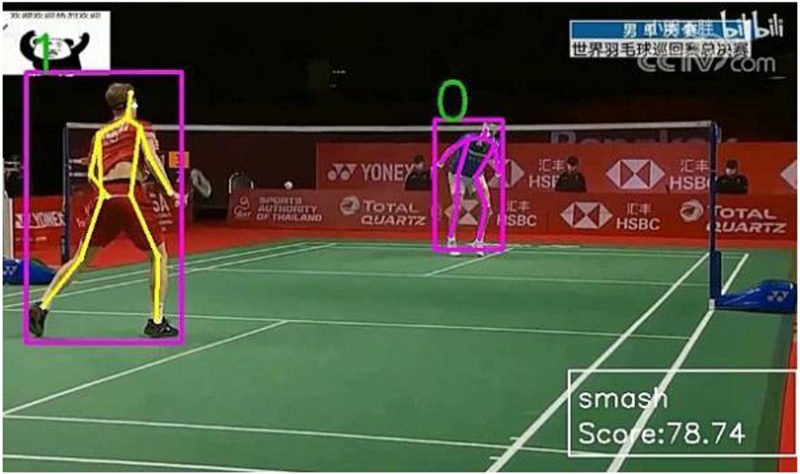
Negative sample smash and score.
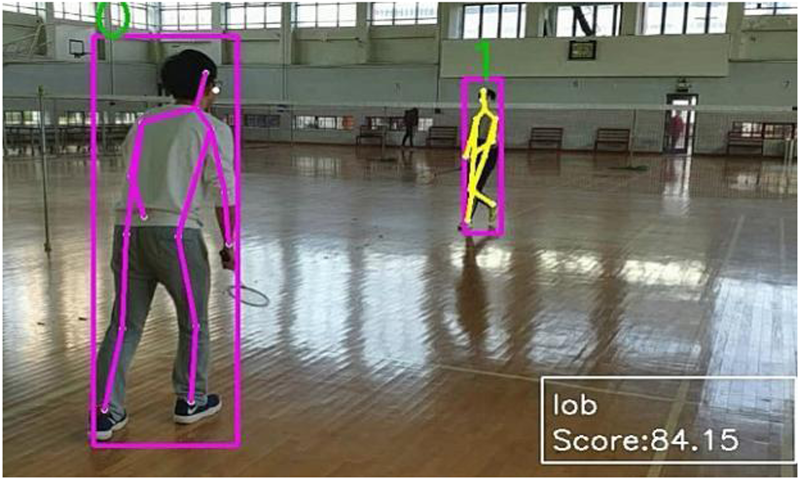
Negative sample lob and score.
This work constructs a preliminary dataset of standard action technique videos for badminton players and develops models for player pose estimation and tracking. The badminton action of the target players is detected, recognized, and evaluated based on its quality. The trained model structure using the constructed dataset exhibits excellent generalization performance and accomplishes the expected results with high precision and accuracy. Consequently, a quantitative and qualitative intelligent actions assessment system for badminton players is established, which positively impacts research on badminton action, teaching quality assessment and providing guidance to train and enhance competitive skills for badminton players.
Footnotes
Acknowledgements
This work was supported in part by the Sports Technology Project of Shanghai Administration of Sports under Grant 21C001.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.