
Abstract
In this paper, the development of action and event detectors over the past three decades is summarized. The detectors are divided into 2D detectors, 3D detectors and deep learning detectors according to whether they contain spatial information and whether they use deep learning. This paper briefly introduces the typical detectors of the different types mentioned above, and explains the advantages, disadvantages and characteristics respectively, and compares them. Comparing traditional feature detection methods with ones based on deep learning, we found that the method of first detecting microscopic details such as point, line, surface angle, etc., and then performing action and event recognition is no longer the mainstream of current research. Due to the strong generalization ability, end-to-end action and event recognition methods based on deep learning perform better than traditional methods. Finally, this paper proposes three research directions for action recognition and event recognition based on feature detectors.
Introduction
The rich video data on the Internet is a very significant data source for video processing research. Feature detectors focus on detecting and identifying the features of interest in static images or dynamic videos. For example, in the application of behavioral action and event recognition in surveillance videos, it is necessary to detect and identify the local or global information required from surveillance videos containing various chaotic elements. Due to its wide application scenarios, action and event recognition has attracted more and more researchers’ attention in the field of computer vision.
The difference between action and event [46] includes: action mainly refers to the movement process of the human body; an event is a combination of multiple actions, which can also include multiple individual actions. So events are more complex than basic actions. For example, running and jumping are two actions; the hurdle can be seen as an event that combines running and jumping [28].
In order to achieve high recognition accuracy of actions and events, the challenges faced by feature detectors are how to obtain robust recognition results under variable illumination conditions, visual angle changes, regional occlusion, camera motion and scaling, and geometric scale changes of detection objects. Few of the traditional feature detectors will take the time information or global information of the action and event into account in the calculation. Compared with the traditional feature detectors, most of the detectors with deep learning consider the time information and the global information of the action, or both, i.e., Spatio-Temporal Progressive action detector [67], structured segment network detector [69] and Coarse-to-Fine Action detector [35].
In the field of action and event recognition, there is no article to summarize and compare the traditional detectors and deep learning detectors. In this paper, the deep learning detectors and the traditional classical detectors in the past decade are analyzed and compared in detail at the algorithm level, which will help relevant researchers to further improve the performance of existing detectors and improve the efficiency of action and event recognition. The main contributions of this paper are as follows:
The main traditional detectors and deep-learning based detectors of the last few decades are summarized in detail; The specific applications of various detectors at the algorithm level are described in detail; Three future research directions in action and event recognition are proposed.
Feature detectors represent static images or dynamic video clips as combinations of interest points or interest regions and are suitable for recognizing targets with sharp extrema and stable lighting conditions. Depending on whether temporal information is involved, feature detectors can be further classified into 2D detectors, such as Harris corner detector [21], Harris–Laplace detector [43–45], difference of Gaussian detector [40,41] and deformable parts model detector [14,16], 3D detectors, such as Harris3D detector [32,33,37], cuboid detector [9], Hessian3D detector [64], and spatiotemporal DPM detector [55], and deep learning detectors, such as faster R-CNN detector [47], T-CNN detector [22], STEP detector [67], SSN detector [69], TACNet detector [52], privacy-preserving detector [49], coarse-to-fine action detector [35], TxVAD detector [65] and TubeR detector [68].
In this paper, we concentrate on reviewing the most popular proposed feature detectors, which are from either top conferences or top journals in computer vision and pattern recognition, for event and action recognition during recent years. These proposed feature detectors can be firstly classified into three categories, which are 2D detectors, 3D detectors and deep learning detectors, as shown in Figure 1.
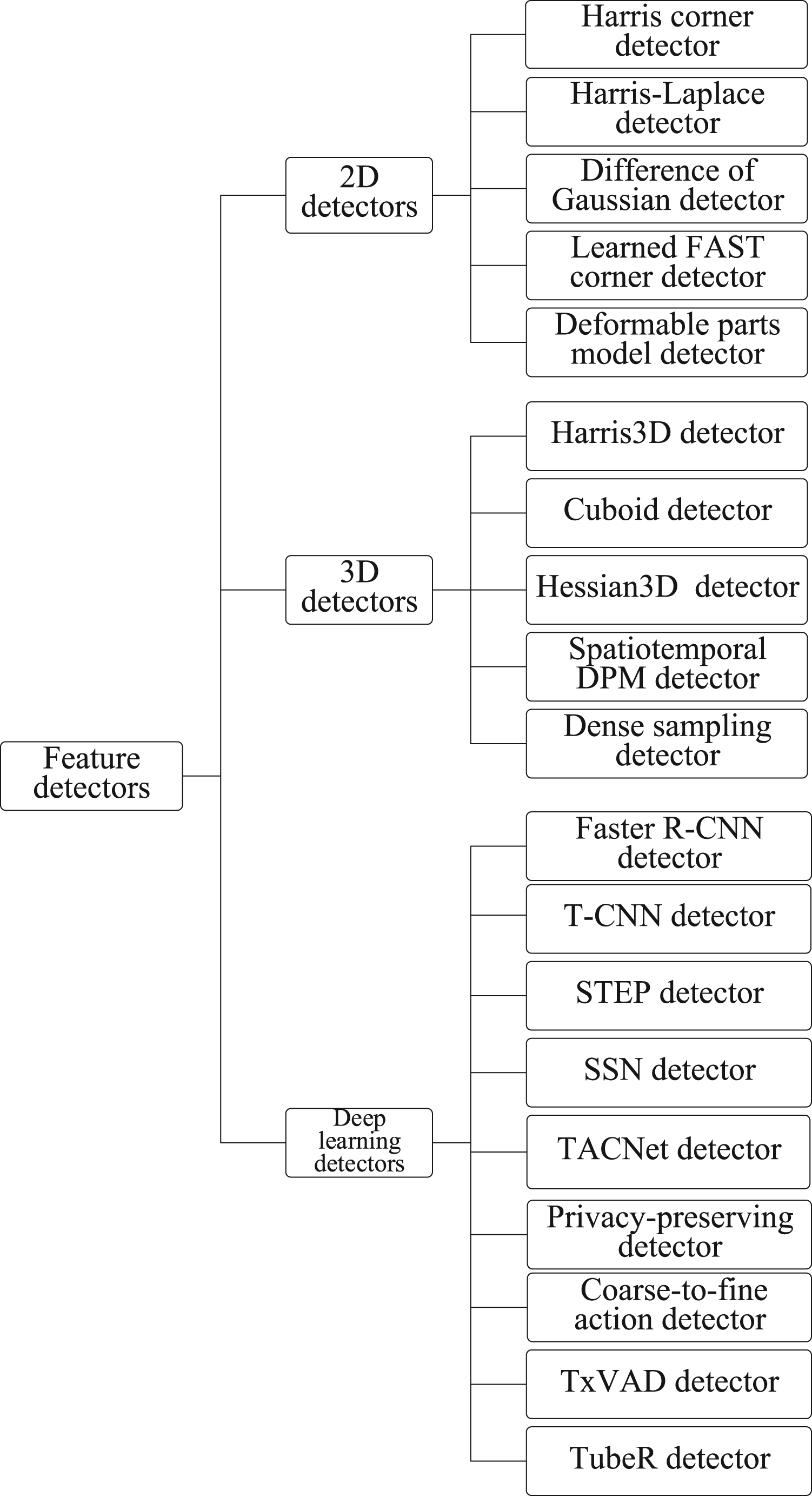
The hierarchical taxonomy of this review.
By all accounts, 2D and 3D detectors are traditional methods using manual features. Since 2014, in video understanding, due to hardware development, sufficient data, and excellent performance of deep learning, traditional methods have been replaced by deep learning methods [13,51]. In this paper, the deep learning methods discussed are mainly convolutional neural networks (CNN) and Transformer. Compared with convolutional neural networks, Transformer has achieved competitive performance in the field of computer vision in the past two years [42,66]. However, due to the lack of inductive paranoia, the transformer’s performance is not as good as CNN on small-scale data sets (such as UCF101-24) from scratch. After large-scale data pre-training, Transformer can get better results than CNN on iconic data sets (such as Kinectics-700 data sets) [10,56].
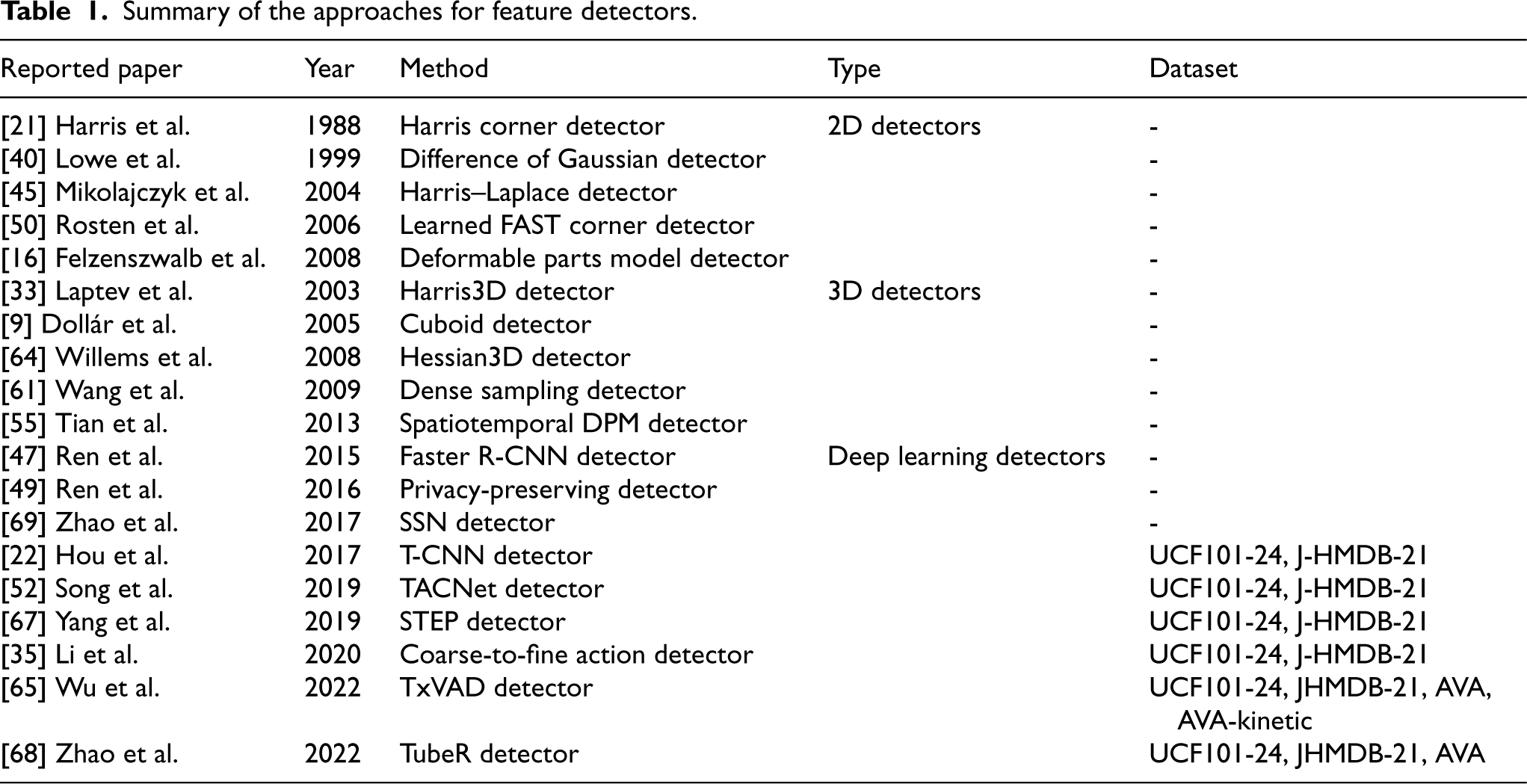
The rest of the review paper is organized as follows. Firstly, approaches for feature detectors are reviewed in Section 2. Then, Section 3 briefly introduce 4 mainstream video datasets, and Section 4 covers approaches for 2D detectors. In addition, Section 5 presents approaches for 3D detectors and Section 6 for deep learning based approaches. Finally, Section 7 concludes the review paper, as shown in Table 1.
Summary of the approaches for feature detectors.
As a data-driven approach, deep learning methods have become mainstream in the field of computer vision. Therefore, datasets have a great impact on the performance of deep learning methods. The brief introduction about several mainstream video datasets for action recognition and event recognition as follow:
2D detectors
Harris corner detector
Overlapping with interest point detection, corner detection is frequently used in event and action recognition, where the Harris corner detector [21] is one of the most classic algorithms in the corner detection.
Let I be one image, 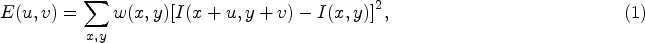

Furthermore, Harris and Stephens [21] proposed a corner response function R, which is defined as
compute first image derivatives compute products of derivatives [21] at every pixel by
compute the corner response matrix [21] in Eq. (3), where compute local maxima in windows of R above a threshold. For example, if the size of the window is 5-by-5, then non-zero elements [21] in the matrix



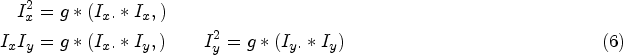
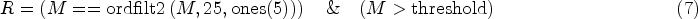
It is well known that the Harris corner detector [21] is variant to detection scales. Mikolajczyk and Schmid [43–45] solved the issue by proposing a Harris–Laplace detector.
Let I be one image. Then, the measure of the Harris–Laplace detector [43–45] is
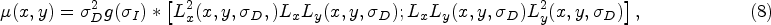
They select 
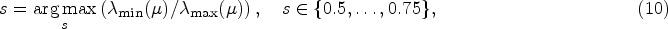
Finally, they take points
Lowe [40,41] proposed an efficient scale space extremes detection algorithm, called Difference-of-Gaussian (DoG) as a close approximation of the scale-normalized Laplacian of Gaussian to identify potential interest points that are invariant to scale and orientation.
Let 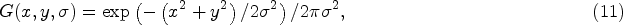
Then, the DoG function 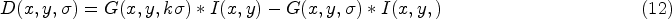
A sample point is selected as the local maxima or minima only if it has a largest or smallest DoG function value within all 3-by-3-by-3 neighbors. Furthermore, the efficient and scale invariant DoG has been widely used in interest point detection.
Detectors based approaches can be also used in realtime frame rate applications. However, most traditional detectors, such as DoG detector and Harris detector, are not suitable for those realtime applications due to their computationally complexity. Under this particular background, Rosten et al. [50] proposed a high-speed machine learning based corner detection algorithm, called learned FAST (Features from Accelerated Segment Test) corner detector. The approach involved mainly two steps:
Firstly, use their segment test criterion to detect initially all corners from a set of target images T. Specifically, let x be one of sixteen pixels in a circle around the candidate corner p,
Secondly, selected the x which yields the most information [50] by
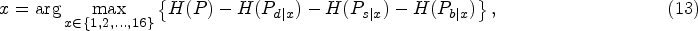

Besides, Rosten et al. [50] also verified by experiments that their detector can not only improve the speed, but also obtain the quality for realtime corner detection applications.
Object detector, like the interset point detector, can be also used as the feature detector. Recently, Felzenszwalb et al. [14,16] proposed a state-of-the-art latent SVM object detector, which is also a mixture of deformable parts model (DPM).
Let
Then, they construct the classification function of the latent SVM object detector [16], as

In order to use the classification function of the latent SVM model for object detection, they trained the model parameters β by minimizing the 
Object detection by using the latent SVM object detector has already achieved state-of-the-art results on many datasets, such as the PASCAL and INRIA person datasets.
Harris3D detector
Laptev and Lindeberg [32,33,37] proposed a Harris3D corner detector, which is a spatial temporal generalization of the well-known Harris corner detector [21], for extracting 3D interest points from key frames of given video clips.
Let 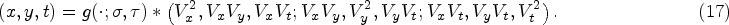
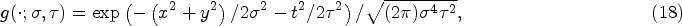
The two parameters can be obtained by maximizing a normalized spatial-temporal Laplace operator [33], as

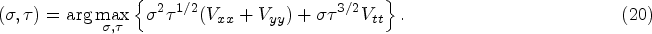
Let
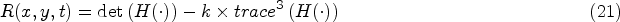
Although the generalized Harris3D is quite effective at detecting spatio-temporal corners, there are mainly two issues [9], which are:
true spatio-temporal corners are quite rare.
spatio-temporal corners are not always the features one needs for general action recognition.
Dollar et al. [9] solved these issues by proposing a spatio-temporal Cuboid detector for the action recognition. The Cuboid detector is based on both spatial Gaussian filters and temporal Gabor filters.
The response function of the Cuboid detector has the form

Besides, they use
According to Willems et al. [64], the generalized Harris3D [32,33,37] is a time-consuming algorithm for sparse features and the Cuboid [9] generates scale variant features.
Thus, Willems et al. [64] proposed a spatio-temporal efficient dense yet scale-invariant feature detector, namely Hessiand3D detector. They searched for local dense extrema on the determinant of the Hessian and approximated all 3D convolutions by box-filters based on the integral video for the efficient purpose.
Let 
Then, the spatio-temporal Hessian [64] is defined as


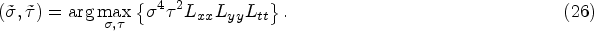
Furthermore, they let correct scale parameters σ and τ be
Tian et al. [55] proposed a spatiotemporal deformable part model (SDPM) for action detection by generalizing the state-of-the-art 2D deformable part models [14,16]. The SDPM detector selected automatically the most discriminative 3D sub-volumes as parts and employed the volumetric HOG3D [29] descriptor.
Let
Then, the score of a detection volume at 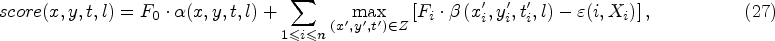
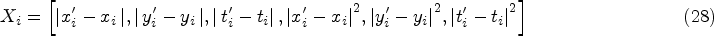
Based on the sliding sub-volume approach, an action is detected at the given spatiotemporal location if a detection volume scores above a threshold.
Both Fei-Fei et al. [11] and Jurie et al. [26] have shown that, for natural scene recognition tasks or natural object recognition tasks, dense sampling detector plus unsupervised learning or explicit discriminative feature selection usually give better results than key-point detector based approaches, since the latter were unable to select the most informative regions. In order to select informative regions in three-dimensional video clips, Wang et al. [61] recommended to use dense sampling detector.
Let V be a video clip,
Firstly, set 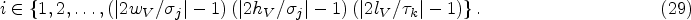
Faster R-CNN detector
During the past decade, the convolutional neural network, known as CNN, has witnessed the rapid knowledge renew in many reasoning based research areas, such as machine learning and computer vision. In 2012, Krizhevsky et al. [30] relied on their Deep CNN to win the image classification task on ILSVRC 2012 dataset. In order to bridge the gap between image classification and object detection, Girshick et al. [19] proposed an R-CNN (Regions with CNN features) detector in 2014. Once was supervised pre-trained and domain-specific fine-tuned, the R-CNN can be adopted to detect interested objects based on three steps: (1) Take an image as input. Then, generate category-independent region proposals based on Selective Search [58]. After that, warp those regions to fixed size. (2) Extract a fixed-length feature vector from each of the warped region proposal using the Caffe CNN [1], and use non-maximum suppression together with bounding box regression to return revised region proposals. (3) Classify extracted feature vectors using the pre-trained linear SVM. The R-CNN has improved the object detection performance dramatically, compared to previous best result on Pascal VOC 2012.
However, Girshick [18] pointed out that R-CNN is slow because it performs multi-stage expensive training without sharing computation. As a result, fast R-CNN was born, which performs a single-stage less expensive training based on a multi-task loss. Operation procedures of the approach are: (1) Take an image as input and adopt Selective Search [58] to generate region proposals. (2) Use CNN to extract a fixed-length feature vector from each of the region proposal with several convolutional layers and max pooling layers. (3) Apply CNN to output both a probability estimate and a four-dimension bounding box position for each of the candidate object classes, based on an integrated softmax estimator and an integrated bounding box regressor. Compared to designated work, fast R-CNN does improve training and testing speed while maintain an increasing detection accuracy.
Ren et al. [47] found that the inelegant object proposal extraction is the computational bottleneck of the fast R-CNN detector. They further design a new detector, called faster R-CNN [47], which replaces the time consuming Selective Search in the previous proposed fast R-CNN with their new integrated region proposal network (RPN). Their contributions lie mainly in two folds: (1). Instead of generating region proposals with graph-based complex image segmentation approach [15] together with a hierarchical greedy region grouping strategy, the RPN simply collect features from the output of convolutional layers by a 3-scale-3aspect ratio sliding network, i.e. total 9 different sliding windows. (2). The integrated RPN can also share those convolutional layers with the CNN. The authors verified by experiments that the faster R-CNN detector produces not only detection accuracy better but also detection speed faster, than the strong baseline.
Faster R-CNN detector has also been applied in related action and event recognition tasks and shown excellent performance. Weinzaepfel et al. [63] proposed a weakly-supervised method for action localization, which adopts firstly faster R-CNN detector to extract human tubes from videos, secondly improved dense trajectories [60] to describe those tubes, and finally multi-fold MIL [6] to select most possible tubes as action localization.
T-CNN detector
Hou et al. [22] proposed Tube convolutional neural network (T-CNN) for action detection, which is a unified deep net-work based on 3D convolutional network (ConvNet) features [57]. To capture the spatio-temporal information in the video and detect the differentiated action, T-CNN generalizes faster R-CNN [47] from 2D image regions to 3D video tubes. The approach involved mainly three steps:
Firstly, an 8-frame video is divided into clips of equal length, and the clips are input into tube proposal network (TPN) [22]. In particular, according to the conv5 feature cube of 3D convolutional network (ConvNet), a set of bounding box proposals is generated for each clip in the video. K-means clustering is applied to select anchor bounding boxes. It is also suitable for different datasets. An “actionness” score related to each bounding box is used to measure the correlation of the content to a valid action. Bounding boxes with actionness scores greater than or equal to the threshold are selected as positive bounding box proposals. Since temporal max pooling concentrates time from 8 frames to 1 frame, the time series of the original 8 frames is lost. So temporal skip pooling is used to inject temporal ordering for frame-level detection. Tube of interest (ToI) Pooling merges variable-sized tube proposals and bounding box proposals into a fixed feature shape. Finally, the synthesized tube proposals are output as the TPN, which also marks the spatiotemporal action localization of the input video.
Secondly, considering the actionness scores of each clip and the overlap between adjacent proposals, each tube proposal is calculated with a score defined as follows [22]:
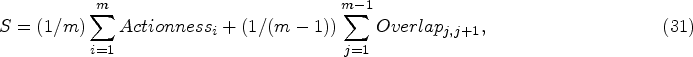
Lastly, the linked tube proposal sequences are sorted by size. Then, in order to perform spatio-temporal action detection, tube of interest (ToI) pooling [22] is used to extract feature vectors of a fixed shape and a fixed duration as an action label.
Besides, Hou et al. [22] also verified by experiments that their detector can not only classify and locate actions in videos but also improve the better performance through extensive assessment of T-CNN action detection in clip and un-clipped videos compared to state-of-the-arts.
Spatio-temporal-action detection requires recognize target action categories in videos and locating them both spatially and temporally. For the deep learning framework, it brings some new challenges, which is the need for action tube-based proposals to include spatial displacement. Therefore, it increases the difficulty of proposal generation and more accurate localization, and in order to obtain more accurate action classification, a network model framework with robust temporal modeling capability is required, since multiple actions can only be recognized when temporal context information is available. Under these challenges background, Yang et al. [67] proposed a progressive learning framework for spatio-temporal action detection in action videos, called spatio-temporal progressive (STEP) action detector. It mainly includes the following two steps:
Firstly, for the initial 11 proposals Yang et al. [67] gave for each clip, an additional regression branch that can achieve adaptive temporal expansion through position expectation is additionally trained, based on the assumption that there is only a small residual between two adjacent clips. Let x [67] be the feature sent to the position regressor



Secondly, two different branches are used for spatial refinement, a global branch for the task of action classification on the input video sequence clips, and a local branch for the task of bounding box regression for each frame. ROI pooling is used for regional feature extraction and input into the global branch to generate global features, global features encoding the contextual information of the pipeline are used to output classification predictions
In summary, Yang et al. [67] achieved excellent performance on spatio-temporal action detection by using only a small number of proposals in the proposed STEP detector.
In the temporal action detection in untrimmed videos, the detector not only needs to accurately determine the category, but also needs to determine that the current action instance is a complete instance, i.e., the time when the action begins and ends needs to be accurately detected. In the previous detectors, the features are often built on the average pooling without any stage attributes, resulting in the detection of each discriminative fragment related to the target action instance, which cannot accurately locate a complete action instance. Zhao et al. [69] proposed a structured segment network (SSN), a framework for modeling each action instance using a structured temporal pyramid (STTP). They divide each proposal into three stages in SSN, i.e., starting, course and ending. Then two classifiers are applied to category classification and whether it is a complete instance. The main steps are as follows:
For each input video V is divided into T snippets, each snippet is divided into N proposals [69], i.e.,

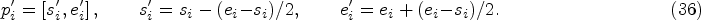
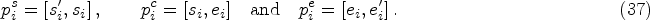

In the action class classifier, they limit the detection range to the course stage, so the
The SSN detector proposed by Zhao et al. [69] achieved more excellent performance than state-of-the-art by using STTP and two classifiers used to predict the activity category and action completeness, respectively. The SSN detector can not only locate the temporal boundary of the complete action instance more accurately, but also be applied to the action category detection with multiple temporal structures.
Extracting valid long-term action context information and enabling the model to accurately learn accurate action states, rather than ambiguous action states (before and after the target action state time and similar to the target action state), are important factors for improving the accuracy of spatio-temporal action detection. In the previous method proposed by Kalogeiton et al. [27], only short-term action context information of up to 10 frames can be extracted, and the problem caused by the ambiguous action state cannot be solved, i.e., if the ambiguous action state is regarded as the target action state Or the background to let the model train, which will greatly reduce the performance of the model detection. Song et al. [52] defined this ambiguous action state as “transition state” and proposed Transition-Aware Context Network (TACNet), in which the two parts of temporal context detector and transition-aware classifier solve the above two questions.
Song et al. [52] designed the temporal context detector based on the standard SSD [38] framework, and used the same two-stream SSD structure as the action tubelet detector (ACT) [27] to build the action detection pipeline. The difference is that Song et al. [52] embed a Bi-directional Conv-LSTM(Bi-ConvLSTM) [36] between every two adjacent different scales to construct a recurrent detector capable of extracting temporal contextual features for action detection. At the same time, considering that the input video will appear forward and backward, the Bi-ConvLSTM used by Song et al. [52] is a pair of Bi-ConvLSTM with temporal symmetry. They changed the activation function of Bi-ConvLSTM from tanh to ReLU to get better performance, and used a
The main purpose of the Transition-aware classifier is to classify the action category and the action state, and to be able to distinguish whether the current motion state is a “transition state”. In order to solve the optimization conflict and coupling problem between the training objectives of action classification and action state classification, Song et al. [52] used 

TACNet showed excellent performance on two public datasets UCF101-24 and J-HMDB-21 and surpassed the state-of-the-art, and Song et al. [52] also embedded the temporal context detector and transition-aware classifier. It also achieves better performance than the original on other detectors, i.e., SSD and Deconvolution-SSD [17].
A privacy-preserving detector proposed by Ren et al. [49] can learn to obscure faces in the videos and ensure the accuracy of action detection. It has more advantages than traditional manual anonymous methods. Through this action detection, the facial privacy information can be protected, and the action can be identified by the detector.
The network framework of the privacy-preserving detector mainly includes a face modifier from Johnson et al. [25], a spatial action detector, and a face identity classifier. The face modifier can change the face image in the video. The spatial action detector can accurately detect the action in the video. Besides, the face identity classifier uses the adversarial classification loss to ensure that the modification of the face classifier is unable to be identified. The specific process of the privacy-preserving detector is as follows:
(1) Face detection is performed from input frames of a given video set to obtain face regions and face images. Put the collected face area into the face modifier facial modifier [25] and modify it to a new face image.
(2) The Spatial Action Detector generates an action detection loss function by using Fast R-CNN [48] networks to accurately detect the actions in the video.
(3) The face identity classifier performs adversarial classification to ensure that the modified face cannot be identified as the real identity. Among them, the classifier uses the angular softmax loss [39] to continuously optimize anonymous face and achieve the high accuracy of face verification. In addition, the modified video uses a photo-realistic loss: L1 loss [23,70], which preserves human-identifiable information such as scene actions.
(4) Add three loss functions to form the final complete objective formula. The formula iteratively updates the values of the face modifier and the action detector and the face classifier to realize privacy protection. The three loss functions are added to form the final complete formulation. The formulation iteratively updates the values of the face modifier and the action detector, then continuously adjusts the face classifier to achieve privacy protection.
Coarse-to-fine action detector
In previous spatial-temporal action detection, most of them are frame-by-frame detection and then connect the frame-by-frame detection results, so that not only local information is used but also frame-by-frame computation results in very low efficiency. Li et al. [35] proposed a trained end-to-end framework, called coarse-to-fine action detector (CFAD), which can efficiently detect spatial-temporal actions. They proposed a new concept that firstly estimates a coarse spatio-temporal pipeline for the video stream, and then refines the corresponding pipeline by using the key timestamp. The main modules to achieve this concept are coarse module and refine module. The specific steps are as follows:
In coarse modules, Li et al. [35] defined each action instance in the input video stream as a set of



After completing the calculation of
The CFAD proposed by Li et al. [35] not only has a new paradigm concept, but also does not require frame-by-frame dense detection, which can be said to be a very efficient detector. They not only achieved state-of-the-art results on benchmark data such as UCF101-24, and JHMDB-21, but also tripled their speed.
Due to the complexity of video datasets, most action recognition with detector methods in recent years is very complex and contains many specific components, such as person detector and region proposal network (RPN). Transformer was designed to process time series data and was first used in the field of natural language processing [59]. Since transformer has been proven to outperform other convolutional neural network-based methods in the image field, it has received more and more attention in the field of computer vision [10]. Video is a kind of time series data. For temporal modeling capability of transformer, Wu et al. [65] proposed a simple framework without using specific components, named transformer-based video action detector (TxVAD).
TxVAD consists of three parts: 3D-CNN backbone and two pure transformers for action location and action recognition. Given a consecutive sequence of (2L + 1) video clips, a 3D-CNN (I3D [5] or SlowFast [12]) backbone computes feature map
TxVAD reduces many complex components and proposes a simple action recognition with detector framework, but it only uses a transformer instead of the detector or RPN function, and still needs to use ROI pooling. It is difficult to optimize TxVAD containing two transformers, and the training strategy for TxVAD is not an end-to-end strategy.
TubeR detector
An end-to-end approach is able to reduce the specific components of the model, thereby reducing the complexity of the model. Detection transformer (DETR) [2] is an end-to-end object detector that has inspired many computer vision researchers. Zhao et al. [68] proposed tubelet transformer (TubeR), which extended DETR from image data processing to video data processing.
TubeR, similar to DETR, converts visual tasks into sequence-to-sequence tasks, which is what Transformer is good at. Unlike TxVAD, TubeR only consists of 3D-CNN backbone and a transformer to complete action location and classification. Given a video Clip k of the
Comparison of deep learning detectors.
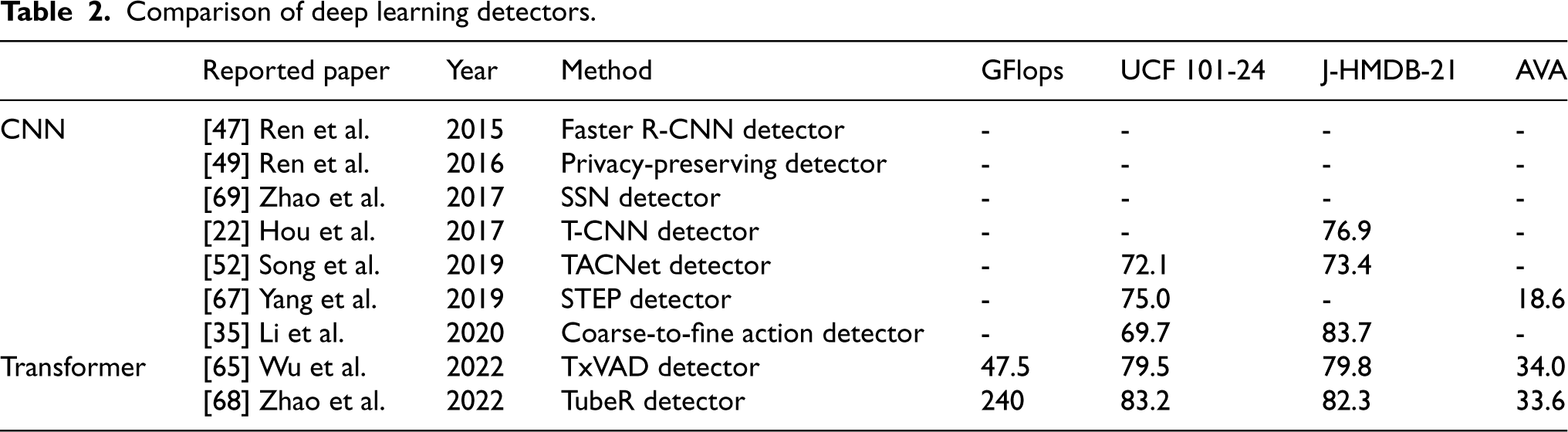
Comparison of deep learning detectors.
TubeR uses a transformer to solve the two problems of person lactation and action classification, instead of requiring two transformers like TxVAD. TubeR is a more thorough end-to-end approach than TxVAD. Despite the excellent performance of TubeR, there are still some shortcomings. TubeR uses 3D-CNN backbone to process low-level information and transformer to process high-level semantic information. The computing overhead of TubeR mainly comes from the 3D-CNN backbone, and because it is based on the action tube to classify behavior, the video is too long will lead to a rapid increase in its memory overhead, these two shortcomings limit the processing of TubeR in long video data.
Table 2 shows the comparison of deep learning algorithm in Section 6. In Table 2 we introduce the frame-level mean average precision with an IoU threshold of 0.5 for UCF101-24 and AVA dataset, while video-level mean average precision with same IoU threshold for J-HMDB-21.
Detectors, mainly feature detectors, are used in traditional action and event recognition. The purpose of traditional feature detectors is to detect points, lines or corners, such as 2D detectors and 3D detectors. Due to the development of convolutional neural networks in recent years, deep learning-based detectors, are extensively used in action and event recognition. They are quite different from traditional methods. Action and event recognition methods based on deep learning tend to integrate feature extractors including feature detectors, and classifiers into one method, namely end-to-end method. Due to this change, feature detectors are being deliberately mentioned less and less frequently in related papers. Due to the strong generalization ability achieved through a series of convolution kernels, deep learning-based detectors are easily used to detect whole regions of actions or events. Traditional feature detectors need to artificially design features for tasks. Although traditional feature detectors may be computationally efficient in some simple scenarios, they are less accurate for complex scenarios. The detectors based on deep learning has strong versatility and high precision for complex scenes, but it has high data requirements. Because the action detection locates the behavior occurrence area and reduces the interference of the background, the performance of the action and event recognition accuracy is better than that of simple action and event recognition. Eliminating distractions is important, but it is also important to ensure that information is adequate. While improving the performance of the detector algorithm, it is also necessary to pay attention to the privacy protection issue in the training process of the deep learning algorithm. Because the powerful detection ability of deep learning may lead to privacy leakage problems. In recent years, due to the emergence of Transformer, a simpler end-to-end framework can be designed for video datasets in multi-person scenes. To sum up, this paper believes that detector-based behavior and event recognition algorithms can be developed from the following three aspects: (1) detectors and privacy protection, (2) action and event recognition based on transformer, and (3) end-to-end method. We hope that this review can provide help for the development of action and event recognition algorithms, so that action and event recognition algorithms can be more intelligent and serve intelligent monitoring, pension industry and other services.
Footnotes
Acknowledgements
We would like to thank anonymous reviewers for helpful comments.