
Abstract
Action is the key to sports and the core factor of standardization, quantification, and comprehensive evaluation. However, in the actual competition training, the occurrence of sports activities is often fleeting, and it is difficult for human eyes to identify quickly and accurately. There are many existing quantitative analysis methods of sports movements, but because there are many complex factors in the actual scene, the effect is not ideal. How to improve the accuracy of the model is the key to current research, but also the core problem to be solved. To solve this problem, this paper puts forward an intelligent system of sports movement quantitative analysis based on deep learning method. The method in this paper is firstly to construct the fuzzy theory human body feature method, through which the influencing factors in the quantitative analysis of movement can be distinguished, and the effective classification can be carried out to eliminate irrelevantly and simplify the core elements. Through the method of human body characteristics based on fuzzy theory, an intelligent system of deep learning quantitative analysis is established, which optimizes the algorithm and combines many modern technologies including DBN architecture. Finally, the accuracy of the method is improved by sports action detection, figure contour extraction, DBN architecture setting, and normalized sports action recognition and quantification. To verify the effect of this model, this paper established a performance comparison experiment based on the traditional method and this method. The experimental results show that compared with the traditional three methods, the accuracy of the in-depth learning sports movement quantitative analysis method in this paper has greatly improved and its performance is better.
Introduction
With the continuous improvement of the economic level, people pay more and more attention to sports, sports is the basic behavior of sports. Correct recognition and analysis of sports movements are conducive to the standardization of athletes’ movements and the conscientization of training and to the improvement of athletes’ performance, which is of great significance to the research of sports movement recognition. Sports are the key technology of sports. It needs scientific methods to regulate the movement of athletes and make their performance reach or close to the highest level. To achieve this goal, the relevant departments have established basketball, volleyball, track and field sports standard actions, and established a multimedia sports database with a standard action. But human motion and movies have many complex objects with fuzzy factors, which are not easy to express and deal with.
In recent decades, various methods proposed by researchers have achieved remarkable results in many open datasets. However, in real-time and real scene motion recognition, the theoretical model still cannot achieve satisfactory results. Each algorithm has functional problems to be solved. The specific problems are described as follows: (1) great changes in motion: the complexity of human structure and behavior is an important factor affecting the accuracy of motion recognition, and the expression forms of different human actions are also very different. Also, the similarity between sports has a great impact on the accuracy of sports recognition, such as running and jogging. The difference between them is mainly the difference between human motion frequency and human joint. In the same complex context, it is difficult to distinguish the two actions. (2) The background has great influence: because a large part of human activities is concentrated in the outdoor, the background of human motion video saved by the camera is often complex. In the later stage of motion feature extraction, complex background often produces more noise, which affects the accurate expression of human motion. (3) Data is difficult to obtain and mark: the task of motion recognition is usually to extract the features of the input video data containing human motion and then use a supervised learning algorithm to classify them. To use the supervised learning algorithm, we first need to sample and annotate the data. Video data usually contains a certain length of video frame sequence, and the occurrence of actions is instantaneous and flexible. (4) The difficulty of real-time recognition is great: at present, the research field of motion recognition mainly focuses on the classification of human daily behaviors and actions. The recognition algorithm mainly divides the input video data into several defined action categories after complex processing. However, due to the fast instantaneous change of human motion, it is difficult for the recognition algorithm to accurately recognize the motion in the video in real-time. The above four points are the main difficulties of motion recognition and analysis, and they are also the difficulties that all researchers in the field of motion recognition and human behavior analysis must face. This paper will start with these difficulties, and put forward the author’s solutions for some of them [1–3].
This paper describes the analysis method of sports action, introduces the application model of sports action in the neural network, and points out the shortcomings of the existing traditional neural network recognition methods. Based on previous research, this paper introduces deep learning and fuzzy theory as an optimization algorithm, which combines human body structure feature model, fuzzy theory, and deep learning neural network technology, and is used for sports action classification to build a new intelligent system of deep learning sports action analysis. Through the improvement of deep learning optimization algorithms in machine learning, combined with sports action detection, figure contour extraction, and other technologies, the DBN structure of action recognition is reset. Through the combination of convolution neural network and cyclic neural network, the normalization technology is used to achieve the task of sports action analysis and quantification in this paper. To verify the effectiveness of the proposed intelligent recognition system, the related experiments are established in this paper. In the experiment, the main methods of feature dimension reduction, multi-feature fusion, and particle swarm optimization are used as comparison objects. To ensure the sufficiency of the experimental samples, the experimental samples in this paper are all from the MSR action3d data set, and on this basis, the comparative analysis of action classification performance, delay performance, feature expression performance, and comprehensive accuracy is carried out. The data shows that the quantitative system of sports movement analysis based on deep learning in this paper has higher accuracy than the traditional method, and it also shows obvious advantages in many aspects, such as movement classification, time, and so on.
The content of this paper is arranged as follows: in the second part of this paper, the related research work in the field of sports movement analysis is introduced at first, and the existing technical difficulties and shortcomings are pointed out. The third chapter introduces the expression of sports characteristics based on the fuzzy theory. In the fourth chapter, a new quantitative system of movement analysis based on deep learning is developed. In the fifth chapter, we verify the improvement of deep learning analysis compared with traditional technology through experiments and introduce many comparative experiments including feature expression in detail. Chapter six summarizes the advantages of the algorithm in this paper.
Related works
The research on sports behavior recognition started from abroad. Many domestic experts and enterprises are also committed to the research of sports behavior recognition. Microsoft has set up a public database of motion, and its KINECT can also be used to capture human motion. Baidu, Tencent, Sogou, and other domestic giants as well as the Chinese Academy of sciences are also engaged in relevant research. At present, motion recognition methods are mainly divided into two categories: one is based on global features; the other is based on local features. Human motion recognition based on global features mainly extracts the global representation of human body structure, shape, and motion, such as motion history map and motion energy map. Human motion recognition based on local features is mainly to extract local features of the human body, such as time and space points of interest.
Feature extraction and motion recognition are mainly through machine learning. It proposed to simulate dynamics with motion graph describe protruding attitude of nodes motion graph three-dimensional point package method. They project each depth map onto three orthogonal cartesian planes and use projection to extract 80 representative 3D points in the depth sequence to represent their motion features. Although the algorithm has a higher recognition rate and robustness than some traditional algorithms, some 3D points projected on XZ and ZY planes are very rough due to the resolution of depth images. Using the method of functional data analysis (FDA), the data sequence of the action cycle is extracted approximately, and then SVM is used for classification. Although the algorithm has achieved good recognition results, there are still some shortcomings. When the periodic data of the action is extracted as the action feature, there is no deep mining of the function feature information of the action. Secondly, the algorithm is mainly applicable to periodic actions, not involving complex or aperiodic actions, which is also the main disadvantage of the method [4–6].
Representation of sports movement characteristics based on fuzzy mathematics theory
Basic knowledge of fuzzy logic
According to the requirements of set theory, an object corresponds to a set; either belongs to the set or does not belong to the set. Such set theory itself cannot deal with specific fuzzy concepts. The so-called fuzzy boundary is not clear, reflecting the phenomenon of intermediate transition, and ambiguity is universal. The efforts to deal with these concepts have resulted in fuzzy mathematics, which is based on fuzzy sets. The theory of fuzzy sets was first proposed by Professor Zadeh, an American automatic control expert, in 1965. He pointed out that if the element x in the theoretical field (research scope) U, there must be a corresponding number A (x) ∈ [0, 1]. Then A is the fuzzy set on U, and A (x) is called the membership degree of two pairs of A. When x changes in U, A (x) is a function, called the membership function of A. The closer the membership A (x) is to 1, the higher the degree of two belonging to A. The closer A (x) is to 0, the lower the degree of two belonging to A. The membership function A (x), which takes the value of interval [01], is used to express the degree of two belonging to A. This is a more reasonable method to describe fuzziness than a classical set theory [7, 8].
Fuzzy inference system
The fuzzy reasoning system consists of a series of fuzzy r rules, knowledgebase (including function family of language statements), and a reasoning mechanism called fuzzy reasoning.
The components are: The fuzziness of input quantity Language rules Fuzzy logic reasoning The output nonfuzzy fuzzy system mainly consists of the following steps:
Step 1: convert the input to the corresponding fuzzy variable, and the corresponding value of each fuzzy variable is between 0 and 1.
Step 2: apply fuzzy logic to input fuzzy variables to generate corresponding result variables.
Step 3: defuzzification, and convert the corresponding output fuzzy variable into an accurate quantity.
The calculation of the fuzzy system first evaluates the individual fuzzy rules (fuzziness and reasoning) and then combines the rules (de fuzziness), namely.
(1) Fuzzy rule: the process of transforming precise quantity (digital quantity) into a fuzzy quantity is called fuzzification. Generally, the following two methods are used:
1) To discrete precise quantities, for example, the continuous quantities varying between [- 6, + 6] are divided into seven levels, each step corresponding to a fuzzy subset.
2) The exact quantity x of an interval is fuzzy to such a fuzzy subset, and its membership degree at point x is 1, the membership degree of all points except x is 0, and each fuzzy set is connected with a membership function. It can be expressed as mapping the value to the corresponding membership degree. Most of the membership functions have the shape of central symmetry and unilateral monotony, and the expression is as follows:
Where H (Z) is the shape and width coefficient of the membership function? d A And s A > 0 are center coefficients and width coefficients of fuzzy set A, respectively.
(2) Fuzzy reasoning: Taking de fuzzification as an example, considering the result of rule j;
All fuzzy rules in FS are evaluated. Each rule gives an activation value to form an activation vector. Firstly, the activation vector is normalized, and then the output vector is calculated [9, 10].
Human movement is a very complex multi-element problem, but in terms of physical education, many problems can be ignored or simplified. The moving body of the human body can be abstracted as the frame structure model of the human body, which can be expressed as the frame structure of the human body (body set, joint set, connection relationship, constraint, and constraint). As shown in Fig. 1, a tree hierarchy structure indicates that the same root body movement can be performed on the lower body of the game driving the lower and upper limbs, and the lower body movement will not affect the upper limbs.
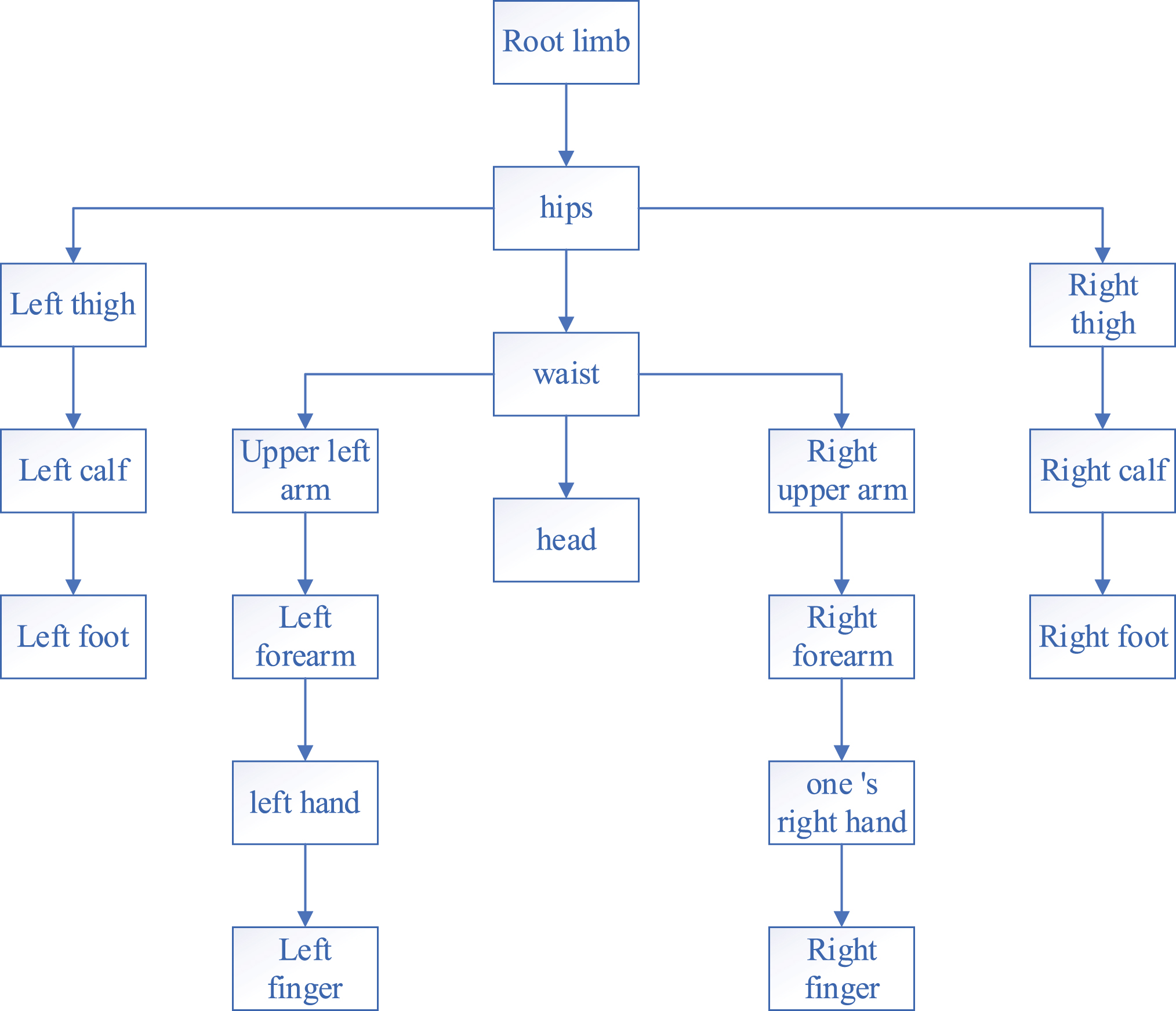
Motion limb constraint hierarchy.
In the human body model database, freedom constraints of limb motion human body frame structure model are stored. Structure library: human frame model (code, limb name, joint name, joint position, connection method, degree freedom constraint). (1) Code: indicates the position and subordination of each branch in the tree structure. (2) The joint position refers to a downward search from the head. The relative positions of limb joints include middle, start, and end. (3) Connection mode: the relative position of the finger and the parent. Limb connections can be delayed or crossed. (4) Degree of freedom constraint: refers to the restriction of limb motion mode and rotation degree of freedom. The limitation of the degree of freedom of rotation is represented by the rotation range of the limb on the X, Y and Z axes. The quantified value of the human model stored in the model database is a human image template for motion analysis, which provides search path and test data for human motion image recognition.
The whole body of human motion is represented by all positions of limbs, and its model is formally expressed as the following five rules by BNF paradigm:
<Body>: - {<limb position> }
<Limb position>: -<rotation state> -<displacement state>
<Turn>: -<limb> <x angle> <y angle> <Z angle>
<Displacement state>: -<joint point> <reference> <x distance> <y distance> <Z distance>
<Reference>: -<node> <Sports Equipment> <scene>
Where the symbol “: -” means “through the content in ‘{}’ indicates that it can be repeated.
Sports movement quantitative analysis system based on deep learning
Basic concepts of deep learning
Deep learning is an extension of machine learning. It aims to use the high-level abstract features of hierarchical learning data to realize multi-level distributed representation. Deep learning combines low-level features to form more abstract high-level features, to discover the distributed feature representation of data, which has strong feature representation ability. Each layer of a deep learning network is nonlinear and has strong nonlinear function fitting ability.
Recognition method of deep learning sports action
Because video has more time-domain information than two-dimensional image data, human motion recognition based on deep learning can process the video data directly, or process the continuous multi-dimensional video frame after preprocessing the video data set. The basic flow chart of the algorithm is shown in Fig. 2. The specific operation steps are as follows:
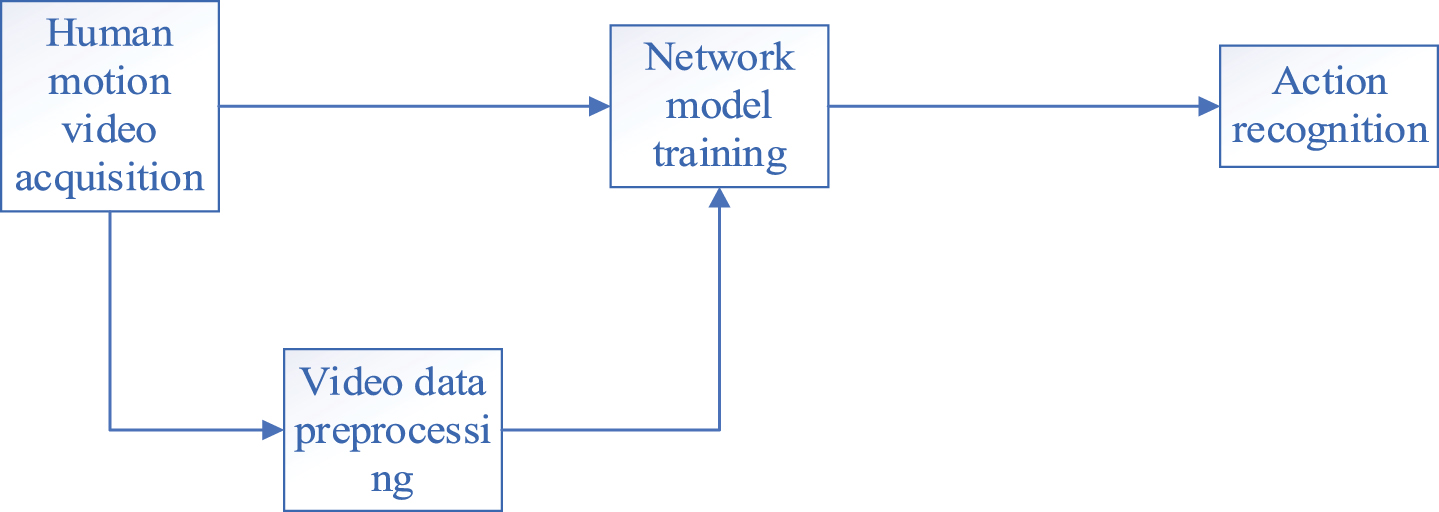
Flow chart of the recognition method of deep learning sports action.
In the process of movement recognition, the first step is to detect the movement of athletes. Combined with the characteristics of athletes’ movement, the frame difference method is used to realize the movement detection, expand the detection results, and strengthen the corrosion profile. The details are as follows:
(1) Set f (i, j) as the image, the front and back frames as f
k
(i, j) and fk+1 (i, j), and Gray (f2 (i, j)) and Gray (f2 (i, j)) as gray-scale images, as follows:
(2) The noise in the moving image is judged by the threshold ɛ, and the binary image D (i, j) is obtained by differential operation according to Equation (4). If D (i, j) = 1 represents the position of the pixel point, that is, the position generated by the action.
(3) The expansion and corrosion treatment of binary image is as follows:
It is very difficult and inefficient to use only two-dimensional (RGB) images for background detection and elimination, but with the help of depth image, the background can be easily identified and deleted. This takes advantage of the fact that the target always has a certain distance from the background pixel, so the target and background are separated with an appropriate depth threshold. Therefore, the contour of the depth image is:
Where, i and j represent the row and column of the pixel image respectively, t is the time stamp of the time frame, ζ is the background depth threshold, and Dsquo is the contour of the depth image.
Where (i, j) the pixel position of the row and column is, t is the time stamp of the time frame, B is the binary contour image, and D is the depth image contour.
Based on the ability of RBM to reconstruct lost data, a new dbn-r motion recognition model is proposed. In the training phase, the input x
i
∈ R
d
and output y
i
∈ R
q
are combined to reconstruct the data D ={ (x
i
, y
i
) , i = 1, ⋯ , n }. Joint data D uses an algorithm (6) to train DBN.In the test phase, when a new input x* ∈ R
q
is given, x* is filled into the input part v
I
∈ R
d
of the visualization layer v ∈ Rd+q, and the output part v0 ∈ R
q
. Fill in a constant α, where α is set to the ratio of the number of activations to the total number of occurrences (activation+deactivation). By associating with
Normalized sports action recognition and quantification
In this experiment, the convolution neural network and cyclic neural network are combined. Based on the original convolution layer, the pooling layer and full connection layer, the batch norm layer, relu layer, scale layer, and dropout layer are added by the convolution neural network, and the SGD algorithm is used for optimization. The last layer of the convolutional neural network is the full connection layer, which is responsible for quantifying the received data to match the input dimensions of the long-term and short-term recurrent neural network, and then input them into the convolutional neural network. In this paper, the LSTM model of the first layer is used to extract the optical flow field form and RGB form from the data as the input data of space-time dual flow network for separate and independent training. Finally, a certain proportion of weight is given to the model obtained by the two networks, and the weight is given according to the category score, which is used for sports action recognition and quantitative tasks.
Experimental results and analysis
Experimental results on MSR action3d dataset
To compare the performance of the proposed algorithm with other existing algorithms, we evaluated our algorithm on the msrac-on-3d dataset.
From the statistical results of Table 1 and Fig. 3, we can see that the recognition accuracy of this algorithm is 93.5%. It can be seen from the results that most of the action categories can be classified accurately, but a few of them have small classification errors. There is a high degree of similarity between these action categories, such as “take from high” and “throw from high”, as well as “bend down” and “pick up and throw”. Because of this similarity, these action categories have some similar dynamic skeletons, so it is difficult to distinguish these actions in the classification model. Compared with other recognition methods, the recognition method in this paper has a great improvement in time and accuracy.
Statistical results of different methods on MSR action3d dataset
Statistical results of different methods on MSR action3d dataset
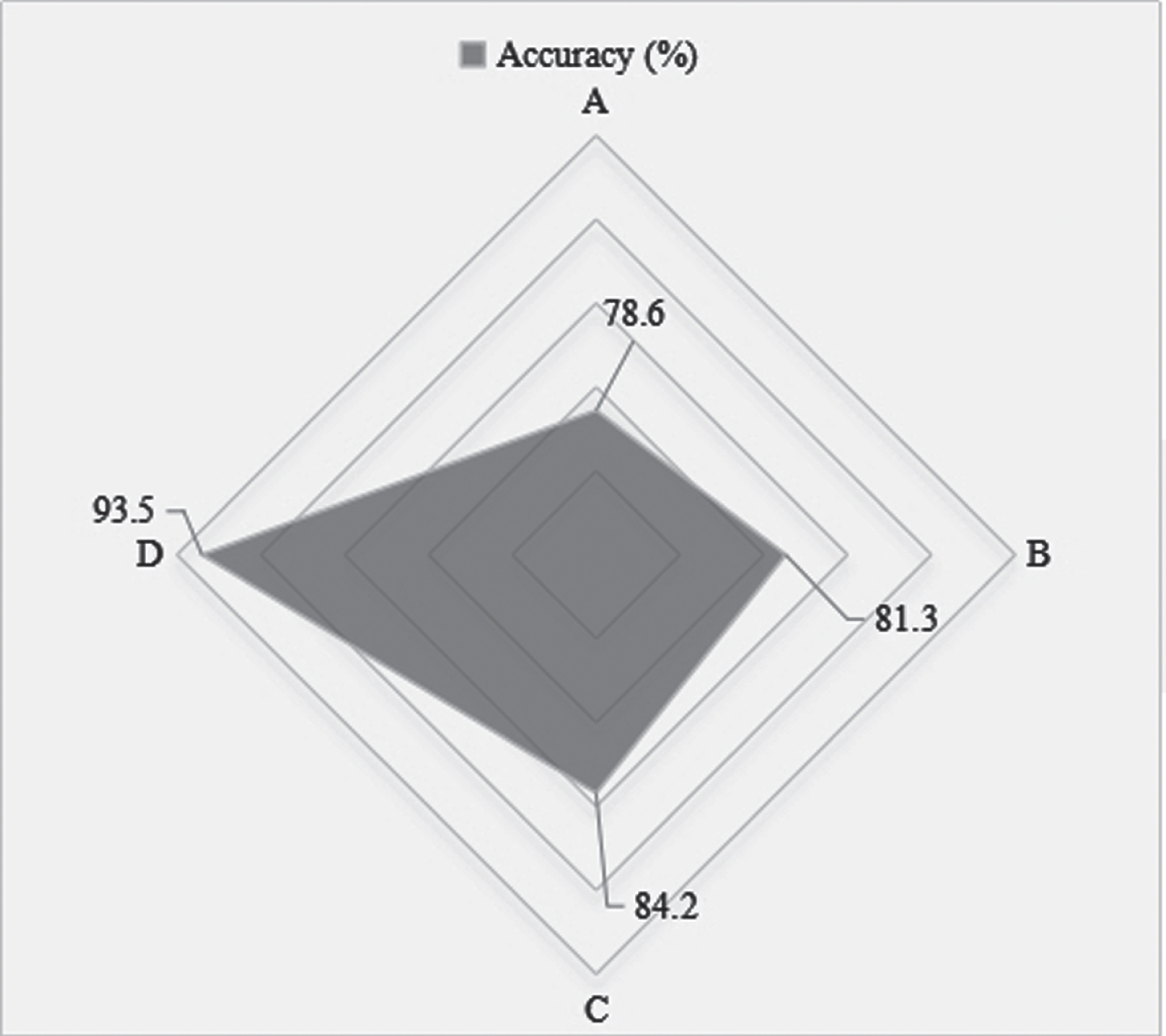
Statistical results analysis of different methods on MSR action3d dataset.
The contribution of each feature descriptor to the overall algorithm performance is compared, and the performance difference between the two coding models is measured. Here, “RP”, “SP” and “ACC” are used to represent the three characteristics of relative position, velocity, and acceleration.
It can be seen from Table 2 and Fig. 4 that the description of relative position features has strong discrimination ability, but the performance of motion classification is still improved after the description of motion information is added. Motion information can play its recognition ability in some similar movements, such as “bang-bang” and “draw √” body posture are similar, there are many similarities. But in the direction of motion, the latter changes more, so the expression of motion information is different from the former, so it is easy to distinguish. We also compare the performance of deep learning and particle swarm optimization in eigenvector state coding. It can be seen that the performance of the deep learning model has been improved significantly considering the context of time and space.
Performance statistics of feature expression of different methods
Performance statistics of feature expression of different methods
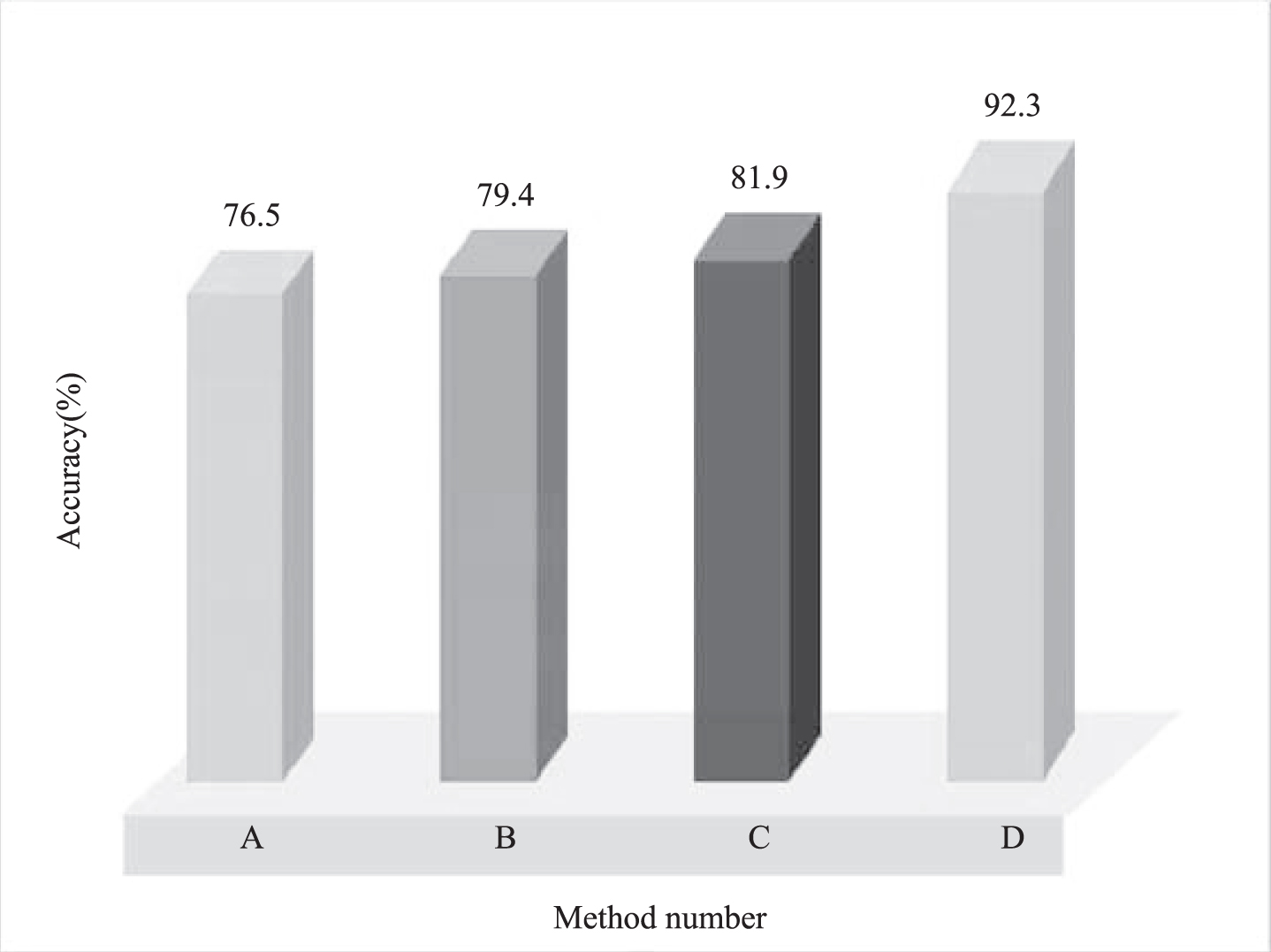
Statistical analysis chart of the performance of feature expression of different methods.
It can be seen from Table 3 and Fig. 5 that the length of the whole video is regarded as a horizontal line, the horizontal line represents the percentage of the observed video data, and the vertical axis represents the recognition accuracy under the corresponding observed data proportion. Since the test video itself is self segmented, the voting results of all observation frames are accumulated. And set a unified voting weight to give the corresponding recognition results. It can be seen from the figure that when observing about 65% of the data, the performance of the algorithm in this paper under multiple data sets is significantly better than most of the current algorithms. We hope that we can accurately judge the performance of the action category before the end of the action, which can greatly improve the effect of observation delay on the system performance.
Statistical table for comparison and analysis of delay performance of different methods
Statistical table for comparison and analysis of delay performance of different methods
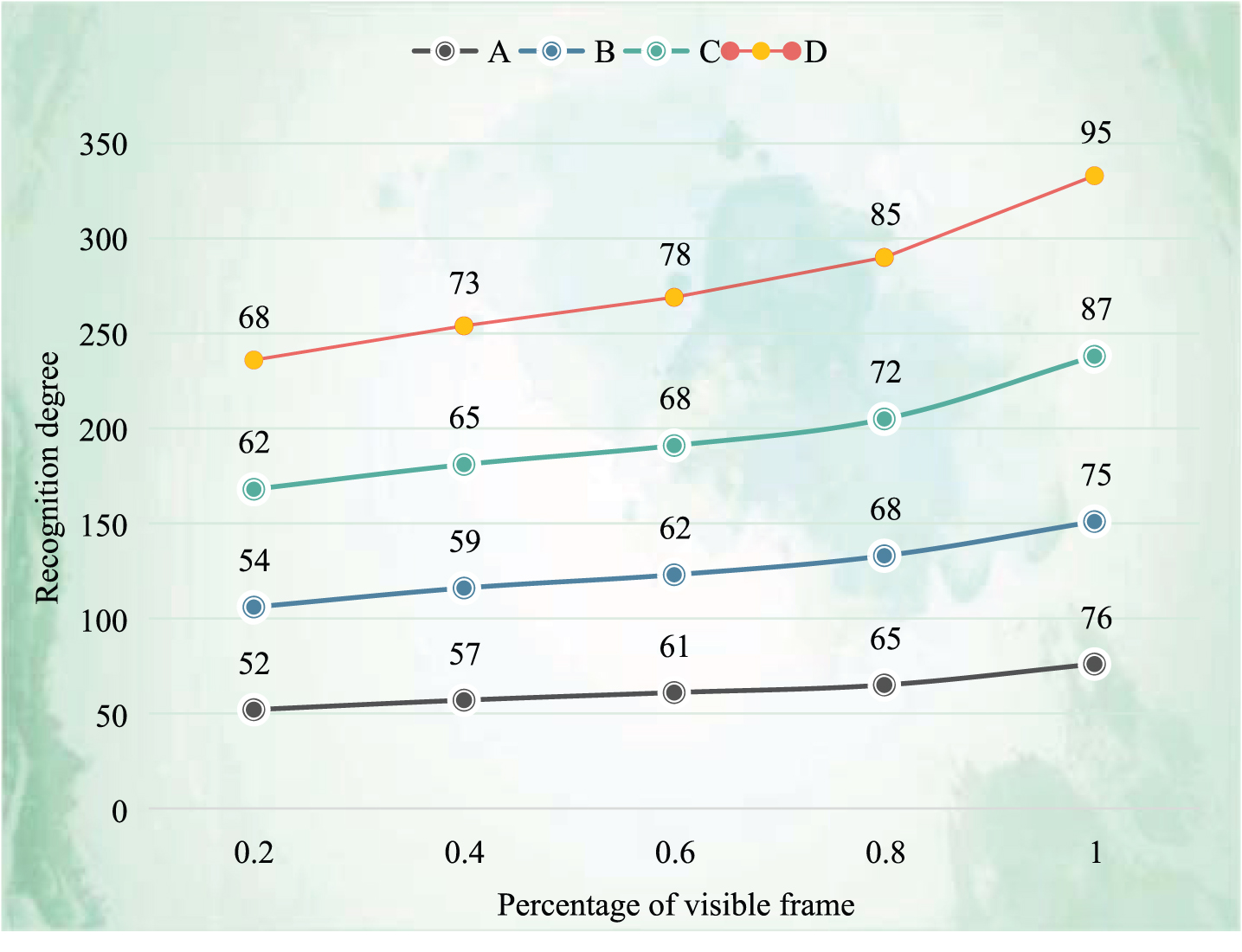
Statistical analysis chart of delay performance comparison analysis of different methods.
Using the existing data set to simulate the real scene, the action of the undivided video is classified. In this paper, the action samples of the same moving object in the test video are spliced into the video stream in random order. In the final performance statistics, we counted the tags of each frame in each video and calculated the final accuracy by taking the action category with the most recognition times as the video action category. In this paper, 120 groups of test samples were randomly spliced on multiple data sets such as msraction3d.
It can be seen from Fig. 6 that different methods recognize the statistical results of different sports actions of 120 groups of data streams respectively. The different methods of statistical recognition results are close to the results of segmented video recognition. The small variance also shows that our algorithm is very sensitive to the action sequence in the video stream, and can accurately capture the key action information and effectively classify it. Compared with the comparison results, the method proposed in this paper has obvious advantages.
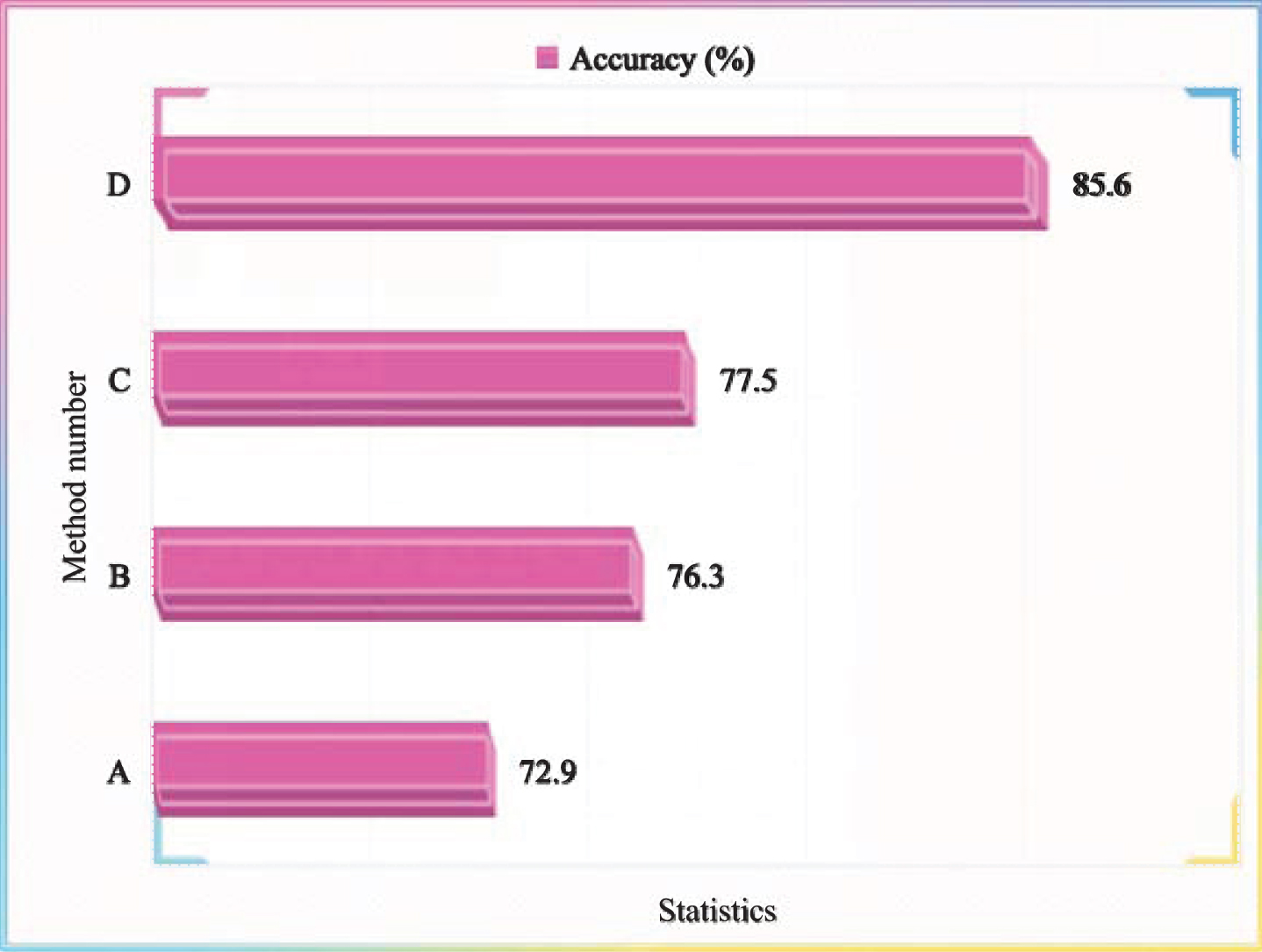
Average accuracy analysis of different recognition methods on the undivided video stream.
In recent decades, sports movement quantification and analysis technology have developed rapidly, and many difficult problems have been broken through. More and more experts and scholars are engaged in the research in this field, for example, the latest particle swarm optimization algorithm has achieved good results in recent years. Although the indoor test results are good, the application in practice is not ideal, which is the common fault of all methods at present. Given this kind of problem, the intelligent system of sports movement quantification and analysis based on the deep learning method developed in this paper solves this kind of problem to a certain extent. The method of this paper combines the fuzzy theory, classifies the human movement characteristics again, determines and eliminates the related factors, and then merges the deep learning method. In this paper, the calculation method of the deep learning method is modified. In the design of system flow, the technology of feature extraction, graphics preprocessing, DBN architecture, and normalized data analysis are used, which makes the accuracy of this method greatly improved compared with the traditional method.