
Abstract
This article discusses estimation of average treatment effects for randomized controlled trials (RCTs) using grouped administrative data to help improve data access. The focus is on design-based estimators, derived using the building blocks of experiments, that are conducive to grouped data for a wide range of RCT designs, including clustered and blocked designs, and models with weights and covariates. Because of the linearity of the regression model underlying RCTs, the asymptotic properties of design-based estimators using group-level averages—formed randomly or by covariates for nonclustered designs and as cluster-level averages for clustered designs—match those using individual data. Furthermore, design effects from aggregation are tolerable with moderate numbers of groups and few covariates, suggesting little information is lost in these cases. Ecological inference methods for subgroup analyses, however, yield large design effects. Several empirical examples using real-world education RCT data demonstrate the theory.
Keywords
1. Introduction
Administrative data, such as education, medical, earnings, and criminal justice records, provide an increasingly rich data source for measuring outcomes for randomized controlled trials (RCTs) of interventions, policies, and programs. Administrative data are typically cheaper to collect than survey data and can offer larger sample sizes with lower attrition and nonresponse. These data, however, can be difficult to obtain due to data privacy concerns protected by law, although there has been some recent progress by Federal agencies, such as the U.S. Census Bureau’s Center for Administrative Records Research and Applications, in improving data access for evidence building (U.S. Office of Management and Budget, 2018).
One approach for facilitating access to administrative data for RCTs is to request data on group averages for the study sample rather than individual-level data. This approach is preferable, for example, to sending computer programs to data agencies to conduct the analysis because it provides researchers with some control over the data and allows for follow-up analyses not anticipated in initial analysis protocols (Card, Chetty, Feldstein, & Saez, 2010). The availability of grouped data may also help reduce obstacles to producing public or restricted-use data sets for future research (and for study replication as academic journals sometimes require), which cannot always be produced using individual-level records due to data destruction clauses or other restrictions in data use agreements. Thus, the use of grouped data is a viable alternative to other approaches to protect data privacy, such as masking individual-level data while preserving the statistical properties of the data (Matthews & Harel, 2011).
This article focuses on the following question: What is lost in terms of bias and precision if average treatment effects (ATEs) for RCTs are estimated using only group-level means on study outcomes, covariates, and weights? We consider a full range of RCT designs, including clustered designs (where groups such as schools, hospitals, or communities are randomized) and both full sample and baseline subgroup analyses (typically the main confirmatory hypotheses for RCTs). We consider models with and without baseline covariates and weights and analyze various strategies for forming the groupings.
Our analysis uses design-based ATE estimators for RCTs (Freedman, 2008; Imbens & Rubin, 2015; Li & Ding, 2017; Lin, 2013; Miratrix, Sekhon, & Yu, 2013; Schochet, 2010, 2013, 2015/2016; Schochet & Kautz, 2018; Yang & Tsiatis, 2001) that are conducive to using grouped data. Design-based methods use the building blocks of experimental designs with minimal assumptions to yield consistent, asymptotically normal estimators and apply to continuous, binary, and discrete outcomes. These estimators have been shown to perform well in simulations (Schochet, 2015/2016; Schochet & Kautz, 2018).
Our analysis draws on the large literature over many years on the statistical implications of using aggregate data to make inferences on microlevel relationships. This literature focuses on efficiency losses from using grouped data to estimate well-specified regression models (Dhrymes & Lleras-Muney, 2006; Feige & Watts, 1972; Prais & Aitchison, 1954; Stoker, 1993) and ecological inference biases due to omitted model explanatory variables and nonlinear microlevel relationships (Freedman, Klein, Ostland, & Roberts, 1998; Goodman, 1959; King, 1997; Robinson, 1950). A related literature has developed methods for conducting statistical analyses to overcome computational limitations with big data, such as subsampling and “dividing and conquering,” which involves conducting the analysis on partitions of the sample and aggregating the separate estimates (Wang, Chen, Schifano, Wu, & Yan, 2016 provide a review). While some authors have discussed the value of using aggregate data for RCTs (Boruch & Reichen, 1975; Jacob, Goddard, & Kim, 2014), this literature has not formally examined the statistical properties of this approach. This article helps to fill this gap for a wide range of RCT designs. While our focus is on RCTs, our results apply also to quasi-experimental designs (QEDs) with comparison groups.
The remainder of this article is in four sections. Section 2 discusses the use of grouped data for nonclustered designs, and Section 3 discusses clustered designs. Section 4 demonstrates the theory using data from several education RCTs (that readers may find helpful to refer to while reading the theory section), and Section 5 presents our conclusions.
2. Nonclustered Designs
To examine the statistical properties of estimators based on grouped data for nonclustered RCTs, we first summarize design-based estimators using individual data. These methods were introduced by Neyman (1923/1990) and later developed in seminal works by Rubin (1974, 1977) and Holland (1986) using a potential outcomes framework.
2.1. Design-Based Methods Using Individual-Level Data
We consider an RCT where N individuals from a single population (indexed by i) are randomly assigned to either a single treatment or control condition. The sample contains
We first consider a setting where the sample and their potential outcomes are randomly drawn from infinite superpopulation (SP) distributions, although we discuss finite-population (FP) models later. The ATE parameter for the SP design is
With these assumptions, design-based estimators for
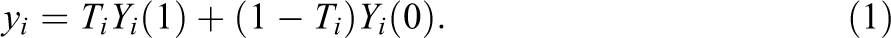
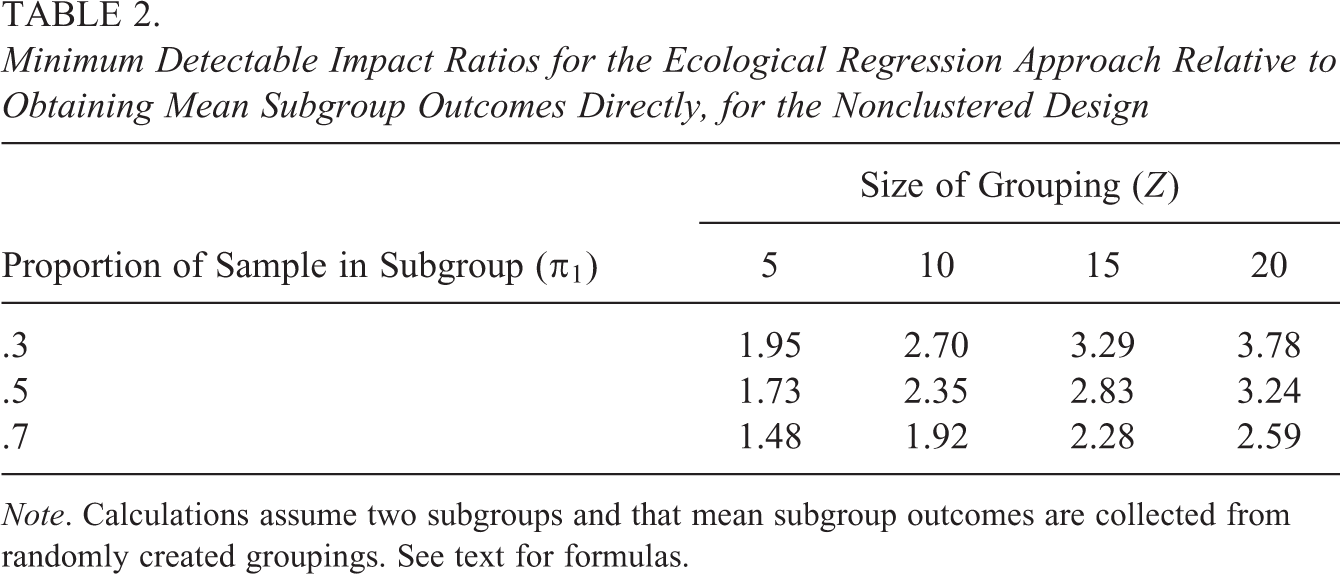
This relation states that we can observe
Let

where
This regression model satisfies the usual ordinary least squares (OLS) assumptions except that error variances differ across the two research groups. To see this, note that similar to the usual OLS model, the model error term,
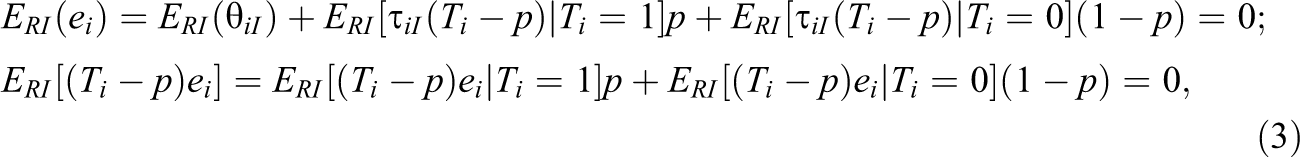
where averaging occurs first over the randomization distribution, R, conditional on the sample and their potential outcomes and then over I. Further, the variance of
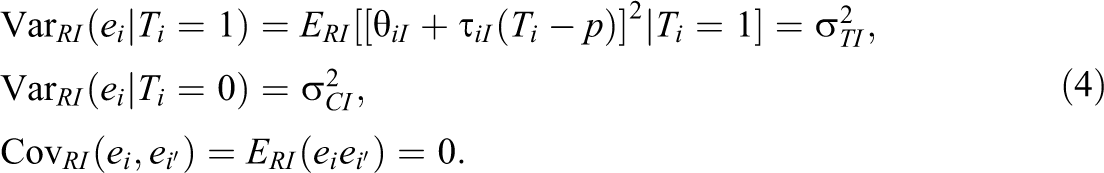
Note that we do not need to specify the distribution of
If we estimate Equation 2 using OLS,

Unbiased estimates for

Hypothesis testing can be conducted using t tests with
We highlight a few features of Equations 5 and 6. First, variances differ across the two research groups because we allow for heterogeneous treatment effects. Second, the same variance estimator results using noncentered data in the regressions instead of centered data. Third, the estimator pertains to continuous, binary, and discrete outcomes.
2.2. Design-Based Methods Using Grouped Data
We now consider design-based estimation where it is assumed that administrative data agency staff group the individual data, separately for treatment and controls, and release group means to the research team. We assume the individual data are aggregated into
For nonclustered designs, we focus on sorting schemes where the individual data are randomly sorted before grouping (e.g., using a random number generator). The random formation of groupings is simple to apply (which can help facilitate data access) and, as we shall see, facilitates variance estimation. We also consider designs that can provide more efficient estimators where the data are instead sorted by covariates and quantify these efficiency gains (see Subsection 2.6). Identifying optimal sorting and grouping schemes to maximize precision of the impact estimates is beyond the scope of this article.
We assume that the administrative data agency releases data on
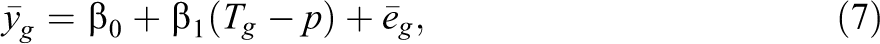
where the error term,

Note that Equation 8 is identical to the variance in Equation 5 because
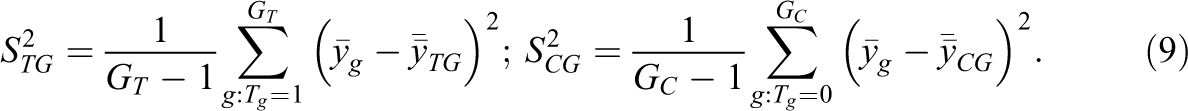
These results show that key test statistics are maintained using the grouped data, which facilitates the analysis presented below on statistical information loss using the grouped data.
Importantly, the random formation of the groups is required to obtain unbiased variance estimators using Equation 7. Grouping by
The statistical cost of using the grouped data relative to the individual data is fewer df for the t tests:
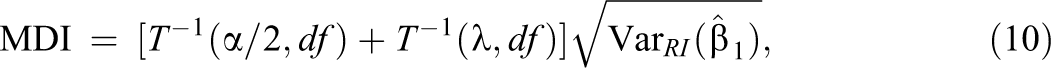
where
The results shown in Figure 1 (bottom solid line) and Appendix Table 1 in the online version of the article suggest that MDI increases using the grouped data (design effects) are less than 5% if there are at least 10 treatment and 10 control groupings (
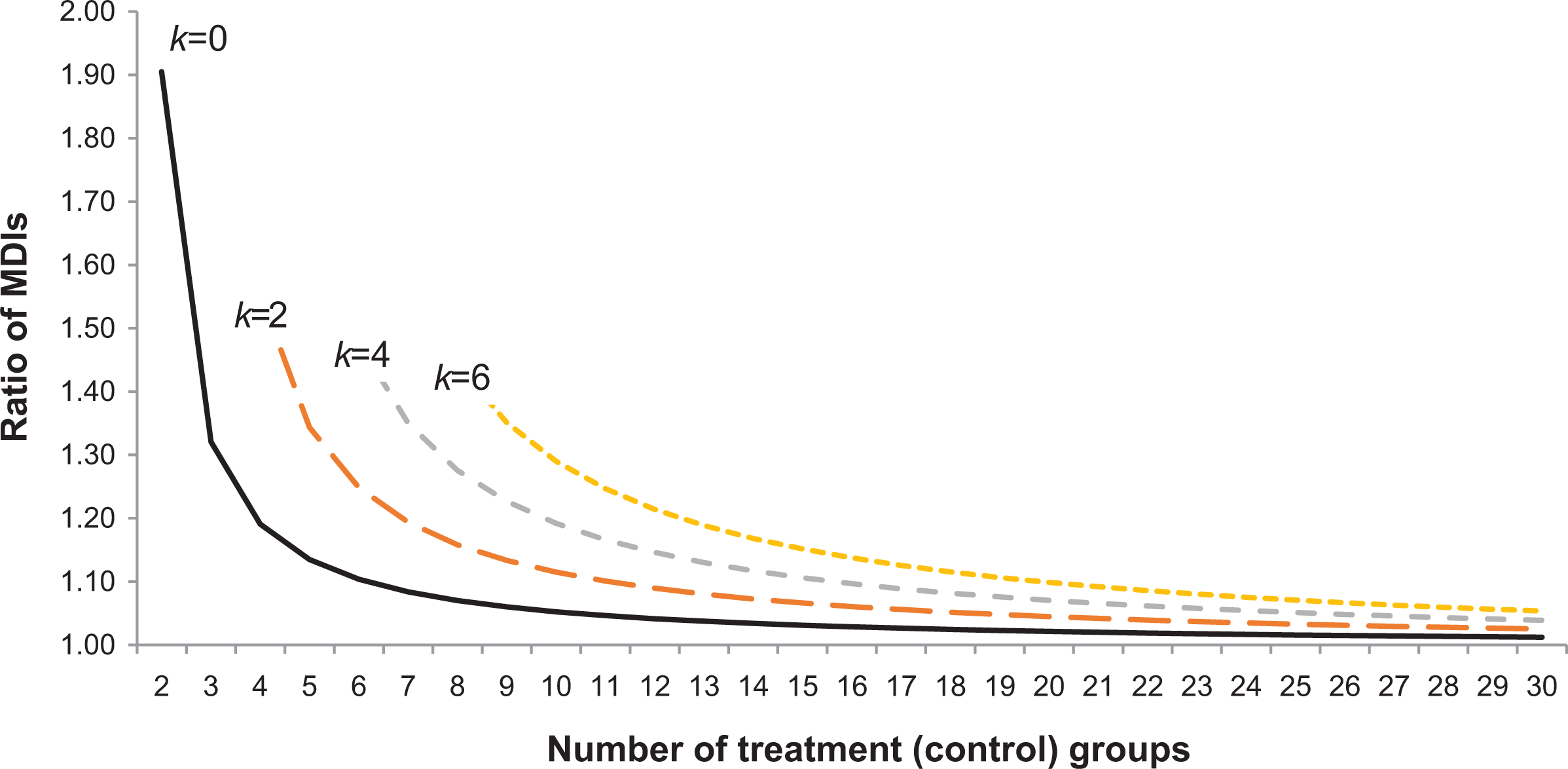
Minimum detectable impact (MDI) ratios using randomly grouped and individual data for the nonclustered design, by the number of covariates (k). Notes: MDI calculations assume a 5% significance level at 80% power for a two-tailed test, a sample of 100 treatments and 100 controls, and groupings of equal size. See text for formulas.
Lower and Upper Confidence Intervals for t Statistics Based on Grouped Data as a Percentage of the “True” t Statistic Based on Individual Data
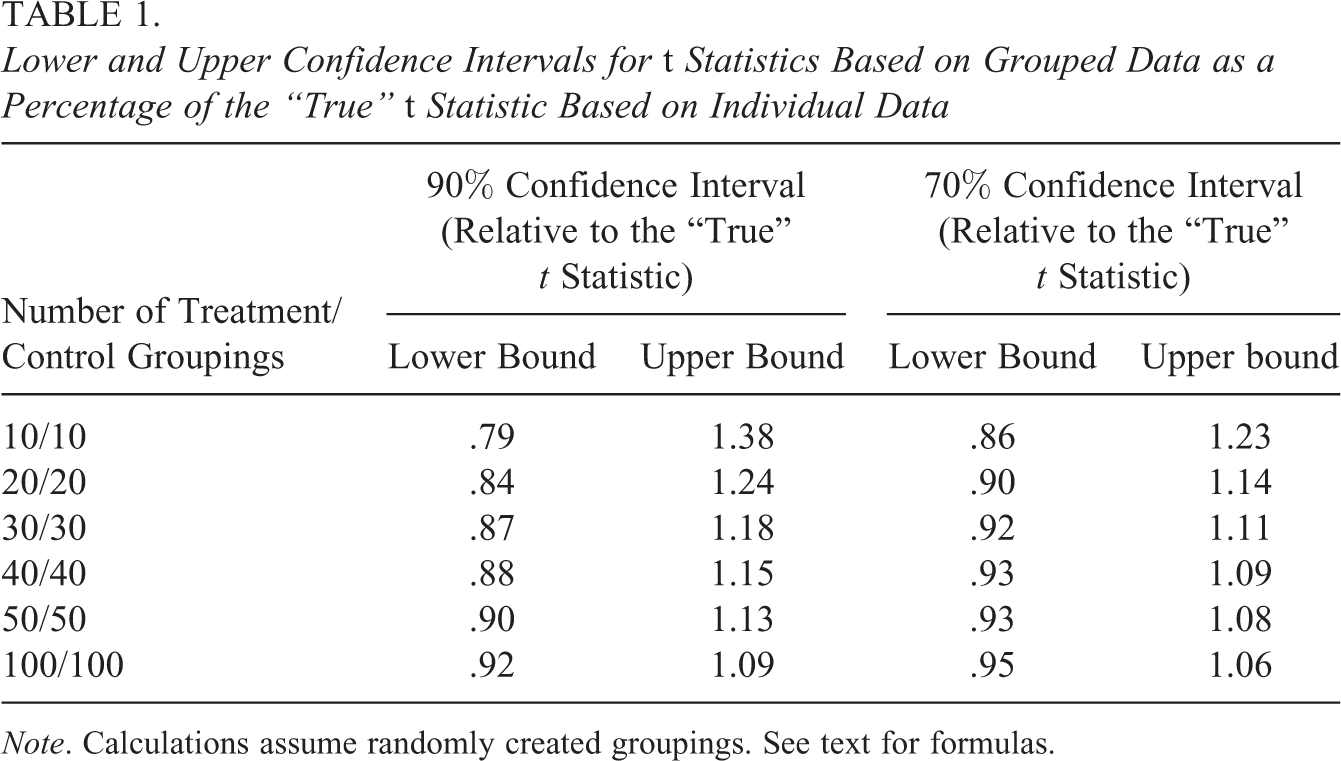
Note. Calculations assume randomly created groupings. See text for formulas.
A related metric for considering df losses using the grouped data is the reduced precision of the variance estimators. Applying asymptotic normality, we have using standard results that
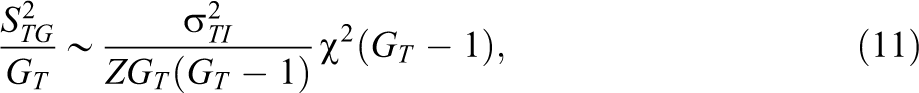
for the treatment group and similarly for the control group. Parallel expressions apply using the individual data. The variance of a χ2 distribution is twice its df. Thus, if we replace
A useful way to measure the risk of using grouped data is to quantify the extent to which t statistics (and p values) match the “true” values based on the individual data. To do this, note that t statistics vary across different possible groupings of the individual data only because of variation in the estimated standard errors (the estimated impacts remain constant across all groupings).
1
Thus, we can create confidence intervals for the group-based t statistics—conditional on the t statistics for the individual data—using confidence intervals for the standard errors based on Equation 11. If we replace
Using this formula, Table 1 displays confidence intervals for group-level t statistics as a ratio of “true” values based on the individual data. The table shows that with 30 treatment and 30 control groupings (60 total), there is a 90% chance that the grouped-based t statistic will lie between 87% and 118% of the “true” t statistic. This means that if the “true” t statistic is less than 1.69 or greater than 2.31, findings regarding statistical significance will very likely be the same using the grouped data and the individual data. The 70% confidence interval bounds narrow to 92% and 111% of the “true” t statistic, respectively. These findings suggest that risks associated with using grouped data in terms of overall study conclusions regarding statistical significance appear to be tolerable, even if the number of groups is relatively small.
One strategy for reducing the statistical risks of using grouped data is to obtain Q replications of the grouped data rather than just one and to average the estimated ATEs and variances across replications. To examine how this “meta-analysis” approach reduces the sampling error of the estimated variances around the “true” variance based on the individual data, suppose we were to first enumerate the universe of all possible combinations of
2.3. Extensions to FP Models
Under the FP model, the sample and their potential outcomes are assumed to be fixed for the study, so the impact results are assumed to pertain to the study sample only and not more broadly as in the SP framework. The FP scenario could be realistic when the sample is purposively selected for the study (e.g., study volunteers). In the FP model, the only source of randomness is
Under the FP model, the relation in Equation 1 still holds, and we can create a similar regression model as in Equation 2 using sample averages rather than population ones. This model is more complex than the SP model because the error term does not have mean zero over the randomization distribution, R, is heteroscedastic and is correlated with the regressor
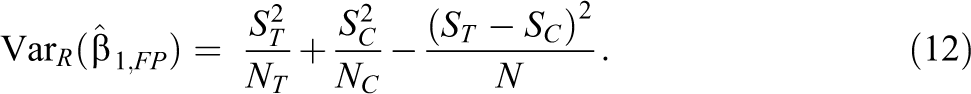
The numerator in the final term in Equation 12 is a lower bound on the heterogeneity of treatment effects across the sample,
To develop FP estimators using group-level averages only, we can follow a parallel approach as for the SP model. The OLS estimator is the same as for the SP model, and the group-level variance can be estimated using

Design effects using grouped versus individual data are similar for the FP and SP models.
2.4. Incorporating Weights
Let
For analyses using grouped data, weighted least squares (WLS) methods using the weights,
The WLS impact estimator for the grouped data using Equation 7 is
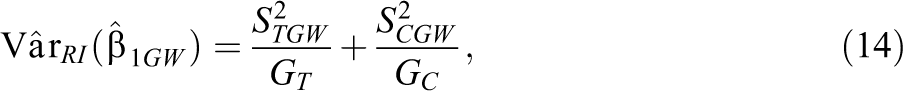
where

and similarly for the FP model in Equation 12.
The losses in statistical information using grouped data (randomly formed) rather than individual data are similar using weighted and unweighted data. The key reason is that design effects due to weighting are similar in expectation using the grouped and individual data. Design effects for the treatment group are
2.5. Blocked Designs
The methods above pertain also to blocked designs where random assignment is conducted separately within partitions of the entire sample (e.g., by site). For blocked designs, the design-based ATE parameter of interest is the weighted average of the ATE parameters in each block (e.g., using block sample sizes as weights). Schochet (2015/2016) discusses details of these estimators for individual data, which are shown to be asymptotically normal. Thus, t tests with
To apply these design-based methods to grouped data, we assume that random groupings are formed for each block, separately for treatments and controls, and that the number of groupings per block is proportional to block sample sizes. We assume that data are released on
Design-based estimators can then be obtained by regressing the
Alternatively, the model could only include
2.6. Models With Covariates
In RCTs, baseline (preintervention) covariates are often included in the regression models to improve precision and to control for random treatment-control imbalances. Let
With covariates, we now assume that data are released on
Schochet (2015/2016) shows that a variance estimator based on model residuals that perform well in simulations (in generating Type 1 errors near nominal values and matching true standard errors) is as follows:
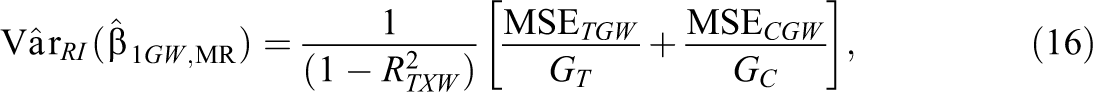
where
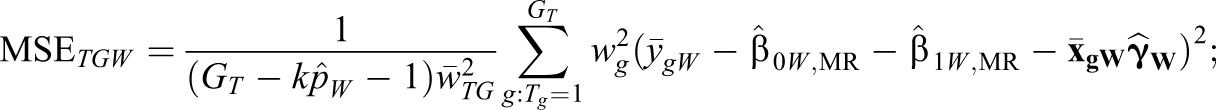

With covariates, the statistical cost of using the grouped data rather than the individual data is 2-fold: (1)
These inflation factors can matter if the number of groupings is small: for example, with two covariates (
Figure 1 and Appendix Table 1 in the online version of the article show MDI increases using the grouped data relative to the individual data for models with covariates (
Forming groupings by a single covariate (or combinations of multiple covariates) rather than randomly can reduce design effects due to
The gains from covariate-based grouping will largely depend on the number and joint distributions of the covariates. Simulations shown in Appendix B in the online version of the article (for a parallel setting for clustered designs discussed in Section 3) suggest that these gains can be quantified using the intraclass correlation coefficient (ICC) of the predicted values (
Note that with covariate-based grouping, the estimation model must include the covariates used to construct the groupings or biases can result. Thus, this grouping scheme may not be suitable for all analyses and should be used cautiously. Grouping by covariates will have a much larger effect on reducing the standard errors of the grouping variables themselves and other model covariates with which they are correlated.
Finally, we note that with covariates, regardless of the sorting mechanism, the grouped data can fully replicate the design-based impact and variance estimators based on the individual data if the following additional weighted statistics are requested for each group g and covariate l:
2.7. Subgroup Analyses
In RCTs, analyses are often conducted to examine how intervention effects vary across baseline subgroups defined by individual and site characteristics. We consider categorical subgroups where each sample member is allocated to a discrete, mutually exclusive category. Aggregate statistics for each subgroup s could be included in the same groupings as for the full sample:
In this setting, the grouped estimation methods discussed in Subsection 2.5 for blocked designs apply fully to the subgroup analysis. For example, a common model specification would be to create separate group-level observations for each subgroup (e.g., for males and females) and estimate design-based models that include two-way interactions between the subgroup and treatment status indicators as well as subgroup indicators (see Schochet, 2015/2016, for details).
If many subgroup analyses are of interest, administrative data requests can become burdensome if separate groupings are requested for each subgroup class. A potentially appealing approach to minimize these data requests is to conduct the subgroup analysis using the G groupings for the full sample that also include data on subgroup proportions (such as the proportions of males and females) but not data on mean subgroup outcomes. Subgroup impacts can then be estimated using ecological regressions (Freedman et al., 1998; Goodman, 1959; King, 1997; Robinson, 1950). Importantly, we assume the full sample groupings are formed randomly, which ensures that the ecological regression approach produces unbiased estimates due to the independence of the model parameters and explanatory variables (see below). The ecological inference literature focuses on solutions to violations of this independence assumption that can cause bias, but we avoid these issues through random sorting of the data.
To examine this approach in our design-based context, we consider two subgroups, indexed by subscripts 1 and 2, where, for simplicity, we consider estimation without weights for the treatment group only (the same approach applies to the control group). To develop the ecological regression model, we first apply the design-based relations in Equations 2 and 7 for each subgroup assuming the same error variances. Second, we use the following relation:

where

where
Because the groupings are created randomly,
To calculate the OLS variance of
Minimum Detectable Impact Ratios for the Ecological Regression Approach Relative to Obtaining Mean Subgroup Outcomes Directly, for the Nonclustered Design
Note. Calculations assume two subgroups and that mean subgroup outcomes are collected from randomly created groupings. See text for formulas.
3. Clustered Designs
Clustered RCTs occur when clusters (such as schools or hospitals) are randomized rather than individuals. We assume the sample contains M total clusters with
We focus on the SP design where it is assumed that study clusters and individuals are random samples from respective superpopulations, S, and I. The ATE parameter of interest is
To develop consistent design-based estimators for
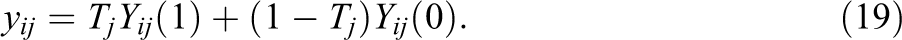
Rearranging this relation yields the following regression model generated by the experiment:

where
This model is the usual random effects specification with mean zero between- and within-cluster error components that are uncorrelated with
Unlike hierarchical linear modeling, the design-based (nonparametric) methods do not involve estimation of the variance components, but instead adjust WLS standard errors for clustering, similar to the generalized estimating equation approach with cluster-robust (sandwich) standard errors (Cameron & Miller, 2015; Liang & Zeger, 1986). Consider using WLS methods and the individual data to regress

where


Importantly, the variance estimator in Equation 21 is based on individual-level model residuals that are averaged to the cluster level. Stated differently, the model is estimated using the individual data, but the
These results suggest that for clustered designs, a natural grouping scheme is to request administrative data by cluster—for example, school- or hospital-level averages—to minimize information loss. Under this scheme, data would be requested on
Importantly, for models without covariates or with cluster-level covariates only, analyzing data averaged to the cluster level yields the same design-based impact and variance estimators with the same df as using the individual data, so no information is lost. However, if the model includes individual-level covariates (that vary both within and between clusters), the ATE and variance estimators will differ using the grouped and individual data (but both are consistent).
6
In this case, grouping by clusters will yield larger expected
Table 3 displays design effects using our approximation assuming equal numbers of treatment and control group clusters. For
Minimum Detectable Impact Ratios Using Cluster-Level Averages Relative to Individual Data for Models With Individual-Level Covariates, for Clustered Designs
Note. Calculations assume clusters are split evenly across the treatment and control group and 50 individuals per cluster. See text for formulas.
Note that design effects can be reduced if additional groupings are formed by sorting individuals into groupings within each cluster, either randomly or by covariates. If this sorting is random, design effects can be approximated using
Finally, regardless of the sorting mechanism, the grouped data for clustered designs can fully replicate the design-based impact and variance estimators based on the individual data if the following additional weighted statistics are requested for each group g and covariate l:
4. Empirical Analysis
To examine how the theory using the grouped data applies in practice, we analyzed data from two RCTs in the education field, one that used a nonclustered design and the other that used a clustered design. The nonclustered RCT—the New York City School Voucher Experiment (Mayer, Peterson, Myers, Tuttle, & Howell, 2002)—examined the effects of offering scholarships to private schools worth up to US$1,400 a year for 3 years to children from low-income families. Eligible students who applied for scholarships were randomly selected for the treatment group using a lottery system. The clustered RCT—the Teach for America Evaluation (Decker, Glazerman, & Mayer, 2004)—examined the impacts of the Teach for America (TFA) Program that recruits seniors and recent graduates with strong academic records from selective colleges to teach for a minimum of 2 years in low-income schools. Students were randomly assigned to classrooms (clusters) taught by TFA teachers or traditional teachers in the same schools. Table 4 describes the studies, including the samples, outcome variables, and baseline covariates for the analysis. Our goal is not to mimic the original study findings or to provide policy conclusions but to demonstrate several key features of ATE estimation using grouped data to demonstrate the theory developed above.
Summary of Randomized Controlled Trial Data for the Empirical Analysis

Table 5 presents empirical results for the NYC Voucher experiment using the individual and grouped data. The table shows estimated ATEs, standard errors, and p values for models without covariates, those with the pretest covariate only, and those with the full set of 11 covariates. Groups of size 5, 10, 20, and 50 individuals were formed randomly, separately for treatments and controls. 7 We generated 500 random groupings and report mean statistics as well as 5th and 95th percentiles of the p values to gauge the risks of obtaining different conclusions regarding statistical significance using the grouped and individual data. We conducted the analysis assuming one set of groupings and averaging across five sets of groupings to improve power.
Full-Sample Impact Estimation Results for the New York City Voucher Experiment

Note. See text for a description of the data and formulas. Figures for the grouped data were obtained by randomly forming groups, separately for the treatment and control groups. The simulations were conducted for 500 replications (groupings).
aFigures for the grouped data show mean impact and mean standard error estimates across 500 random groupings. bFigures for the grouped data show mean p values across 500 random groupings (first row) and the 5th and 95th percentiles for a single set of groupings (second row) and averaged across five sets of groupings (third row).
The results in Table 5 verify the theory that the point estimates for the ATEs using the grouped data are similar on average across the simulations to those using the individual data for models with and without covariates. Furthermore, all specifications show statistically insignificant school voucher effects.
For the models with covariates, standard error increases using the grouped data (because of higher
We also conducted a subgroup analysis for female students by estimating ecological regression models using full-sample groupings of size 10 (not shown). Across 500 simulations, this approach yielded standard errors 2.5 times larger than conducting the subgroup analysis using the individual data for females or separate groupings with mean outcomes for females, which is close to the 2.4 design effect predicted by theory (see Table 2).
Table 6 presents analysis results using data from the TFA study, where students are clustered within classrooms (teachers). Consistent with theory, the impact findings are identical using the individual- and cluster-level data for the model without covariates and for the model that includes the classroom-level pretest score only. For the latter model, we find that TFA teachers increased student math scores by an average of 2.68 scale points (0.14 effect size units), which is statistically significant. For the model with all 11 covariates, the impact results based on the individual and grouped data differ more. This finding is consistent with the theory that impact estimates using the grouped data become increasingly variable as the number of model covariates increase.
Full-Sample Impact Estimation Results for the Teach for America Evaluation
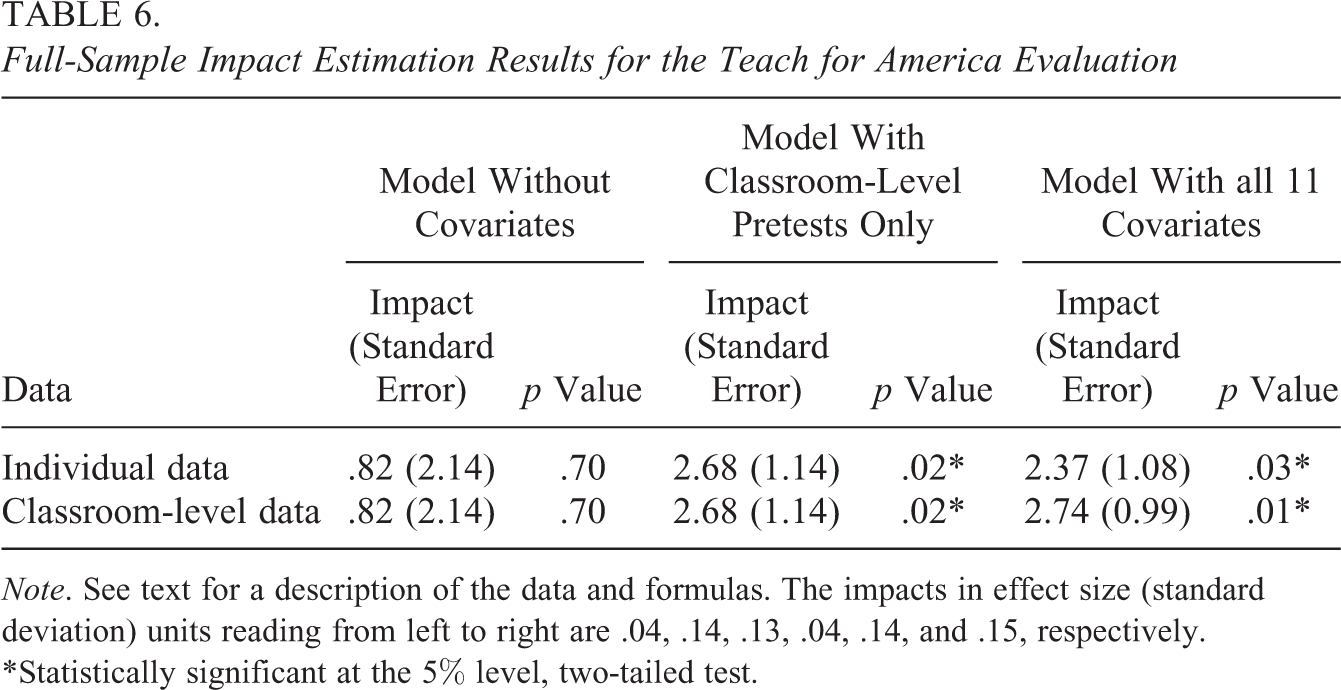
Note. See text for a description of the data and formulas. The impacts in effect size (standard deviation) units reading from left to right are .04, .14, .13, .04, .14, and .15, respectively.
*Statistically significant at the 5% level, two-tailed test.
5. Conclusions
This article has developed methods for quantifying the statistical costs of using group-level averages (
We find that estimated impacts and standard errors using group-level averages have the same asymptotic statistical properties as those based on individual data. The key reason is that the individual-level regression model underlying experimental designs is linear and thus also holds at the grouped level for both (1) the nonclustered design, where groupings for the treatment and control groups are formed at random or by covariates included in the models, and (2) the clustered design, where groupings are formed as cluster-level averages or by individuals at random within clusters.
For the nonclustered design, the risks of using grouped data due to statistical power losses and the variability of impact results over the distribution of possible groupings are tolerable if the total number of groupings is about 40 or more, and the model includes only a few key covariates. The risks increase starkly as the number of covariates increases. If needed, obtaining multiple sets of groupings (and averaging impacts and variances over them) or forming groupings by sorting on covariates that are included in the models could be good strategies to minimize design effects. For the clustered design, little information is lost if administrative data are collected as cluster-level averages. In this case, there are no df losses, and standard error increases due to increased treatment-covariate correlations are minimal if the model contains only a few covariates. For all designs, conducting subgroup analyses using ecological regressions yields large design effects and is not recommended unless the study contains very large samples with excess statistical power; instead, separate groupings should be obtained for each subgroup. The free RCT-YES software (www.rct-yes.com) can be used to estimate impacts and standard errors for all designs considered in this article using grouped (or individual) data.
Supplemental Material
Supplemental Material, DS_10.3102_1076998619855350 - Analyzing Grouped Administrative Data for RCTs Using Design-Based Methods
Supplemental Material, DS_10.3102_1076998619855350 for Analyzing Grouped Administrative Data for RCTs Using Design-Based Methods by Peter Z. Schochet in Journal of Educational and Behavioral Statistics
Footnotes
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.