
Abstract
Credit is a part of external image of enterprises, and it directly affects interests of enterprises. Nowadays, most of researches on predictions of enterprises credit use a single algorithm model or optimize a single model to predict an enterprises credit score. The accuracy of each model is different, and the generalization ability is generally weak. In order to improve generalization ability of models and accuracy of prediction results, a parallel double-layer prediction model is proposed in this paper. The model is based on Stacking and Bagging methods, which can improve generalization ability with high accuracy. Through experiments, we compare three single algorithm models, four integrated learning models with other combination strategies and parallel double-layer prediction model. Average value of four evaluation indexes are increased by 4.2349%, 63.1464%, 34.11837%, 1.26104%, 15.7862%, 10.1457% and 25.6310% respectively. The results show that the parallel double-layer prediction model is accurate and feasible.
Introduction
Credit is an effective “ID card” and a reliable “pass” of enterprises [1]. It reflects external image of enterprises and it has a great impact on the interests of enterprises [2]. Traditional single regression algorithms and neural network are widely used in all aspects of evaluation and prediction, including credit evaluation.
Common single regression algorithms include linear regression algorithm [4], Support Vector Machine (SVM) algorithm [5], K-Nearest Neighbor (KNN) regression algorithm [6], etc. Single regression algorithm models training speed are fast, they are relatively easy to understand. However, there are shortcomings, polynomial regression is difficult to design for nonlinear data. For different data sets, there will be instability, and reliability of prediction results is low.
Neural network [7, 8] has many applications, including credit score prediction, however, it has some defects. It lacks explicability, and we do not know the cause of forecast results. And it needs a lot of data to train.
Furthermore, many models use optimization algorithm to optimize a single regression algorithm to improve accuracy of model prediction. Although optimization algorithms are used to optimize regression algorithms, we can only get model with better prediction effect on one specific data set or one aspect, that is weak supervision model [9]. For different data sets, there is still a problem of weak generalization ability. We can use ensemble learning method to solve this problem well.
Ensemble learning [9, 10] is combining multiple weak supervised models here to get a better and more comprehensive supervised model. Even if one weak classifier gets a wrong prediction, other weak classifiers can correct error back, so as to reduce variance or improve prediction results [11]. Combination strategies of ensemble learning can be formulated and edited according to different methods. Different methods have different results, and it will lead to differences in accuracy and generalization ability of ensemble effect. In order to improve the prediction accuracy and the generalization ability of models, this paper develops the combination strategy and proposes a parallel double-layer prediction model. The contribution of the model is as follows.
To satisfy different data sets, the base learner can be reselected according to actual data. The model solves over fitting phenomenon of model with high prediction accuracy and improves generalization ability. A large number of experiments on various data sets have proved the accuracy and stability of the model. Our method improves reliability of evaluation in aspect of credit evaluation, and provides partial support for agent intelligent inspection.
The other parts of this paper are as follows. Section 2 reviews related researches on credit evaluation. In Section 3, the methods are given and the parallel double-layer prediction model is established. In Section 4, we carry out experimental verification and analysis. Finally, we present conclusions and look forward to the future work.
There are a lot of work on credit scoring before, most of them use regression prediction algorithms in machine learning or neural network to predict, such as Support Vector Machine (SVM), Back Propagation (BP) neural network and so on. Through literature review, current credit evaluation methods mainly include single traditional algorithms, neural network methods and integrated learning methods.
Traditional single algorithm
Fan et al. [12] proposed a credit scoring model of support vector machine, it was based on premature convergence index and adaptive mutation partial swarm optimization, which solved the premature convergence problem of traditional particle swarm optimization. Hu et al. [13] proposed a credit rating evaluation method for commercial websites based on Weighted Support Vector Machine (WSVM), and associated it with website construction time. Maldonado et al. [14] proposed two formulations based on Support Vector Machines for simultaneous classification and feature selection that explicitly incorporated attribute acquisition costs. Niu et al. [15] used smote algorithm to optimize the model and improve the evaluation performance of the model, evaluated and analyzed the complex credit risk of online lending. Junior et al. [16] evaluated applicability of dynamic selection technique to credit scoring problem, and proposed a method to reduce the number of K-Nearest Neighbors (RMKNN). This method improved the latest level of the local region of dynamic selection technique for defining imbalanced credit scoring data sets. Zhang et al. [17] mentioned two typical variants of the integrated Decision tree (DT) method, Random Forest (RF) and Gradient Boosting Decision Tree (GBDT), have been used in recent credit scoring studies.
Neural network method
Hu et al. [18] used particle swarm optimization to train BP neural network and improved existing algorithm. By changing the speed of particle search in the weight space, the mean square error of network output was gradually reduced. Li et al. [19] improved optimal segmentation algorithm, applied it to the training of Radical Basis Function (RBF) neural network parameters to realize the adaptive selection of the number of hidden nodes and established credit rating model. Pławiak et al. [20] proposed a Deep Genetic Hierarchical Network Learning (DGHNL) method, the novelty of the method depended on appropriate information flow and fusion.
Integrated learning method
Xia et al. [21] proposed a sequential integrated credit scoring model based on gradient elevator, which provided feature importance score and decision graph, and enhanced the interpretability of credit scoring model. Yeh et al. [22] proposed a credit rating prediction model with market information as the prediction variable, which provided valuable information, better classification results and meaningful rules for credit rating.
To improve credit score prediction, Trivedi et al. [23] used different feature selection techniques and machine learning classifiers. Based on the Consensus Aproach (ConsA) of different classification algorithms, Ala’raj et al. [24] proposed a new classifier combination rule. Niu et al. [25] constructed three machine learning algorithms (random forest, AdaBoost, and LightGBM) to demonstrate prediction performance of social network information. To achieve transparency and simplicity of credit scoring data sets with heterogeneous attributes, Hayashi et al. [26] used one-dimensional full connection layer first CNN and recursive rule extraction (Re-RX) algorithm combined with J48graft decision tree.
Others
Besides, there are other ways, Yu et al. [27] established a credit evaluation weight optimization model, which changed disadvantages that the existing research can not guarantee evaluation result with maximum discrimination power after the weight was given. Based on a theoretical model proposed by the literature of economics and credit risk management, Hodgkinson et al. [28] used expert system to evaluate credit value of applicant enterprise, which can decide whether to grant the credit line to applicant enterprise. Yin et al. [29] proposed a framework to identify legal judgments that can effectively predict credit risk, extract relevant features contained in effective legal judgments, and use legal judgments to evaluate credit risk of SMEs. Zhang et al. [30] proposed a novel multi criteria optimization classifier based on kernel, fuzzification, and penalty factor (KFPMCOC), which can improve efficiency of credit risk scoring and generalization degree of credit rating prediction for new applicants. Guo et al. [31] proposed a case-based credit risk assessment model for P2P lending investment decision.
Some of above methods use optimization methods to optimize traditional algorithms, or use integration technology to combine a variety of algorithms. These methods basically improve accuracy, but most of them blindly pursue accuracy and ignore generalization ability.
Double-layer prediction model
Approach overview
On the basis of ensemble learning, combining Bagging and Stacking ideas, we propose a parallel double-layer prediction model by changing ensemble strategies. The data processing flow of the model are as follows.
A processed standard data set is brought into a variety of basic learners to get multiple outputs Neural network is used to calculate the weight of each outputs
The new standard data set
After using a training data set to train the model, we can input the relevant data of enterprises for credit evaluation. The parallel double-layer prediction model combines many kinds of basic learning algorithms. The overall combination method adopts double-layer structure of Stacking method, and the local part adopts Bagging structure. The specific combination strategy is shown in Fig. 1.
Parallel double-layer prediction model.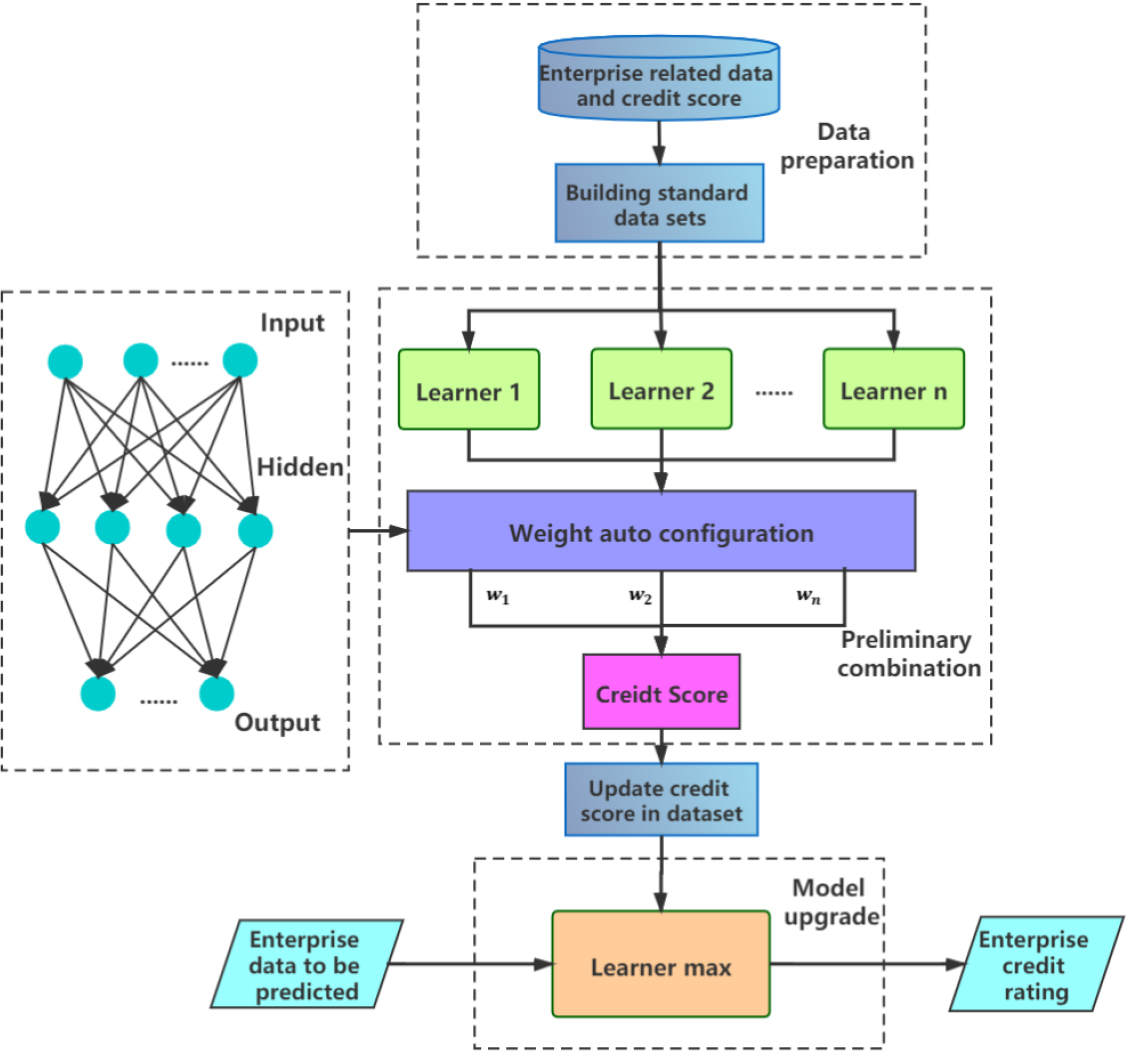
On the whole, the combination strategy described in this paper is based on the Stacking structure, the lifting processing is done. Bagging structure is used in local. Specifically, the combination of several basic learners in the Preliminary combination in Fig. 1 is the Bagging parallel structure. As a key step of the parallel double-layer prediction model, this step has two main functions.
Improve generalization ability of the model. Avoiding single learner model performs well in a certain dataset, but the effect of a new data set is not ideal. There is a problem that the value of tag item does not match the value of feature item in a data set. This step can prepare for updating tag item in the data set, making data more reasonable and easy to fit.
The second main step is the second layer structure of Stacking framework, which is to improve accuracy of prediction results. Using updated data set train the best basic learner, this can improve accuracy of prediction results of the parallel double-layer prediction model.
Bagging algorithm is one of the most famous representative of parallel integrated learning method in Machine learning field. Its flow chart is shown in Fig. 2.
Bagging algorithm flow.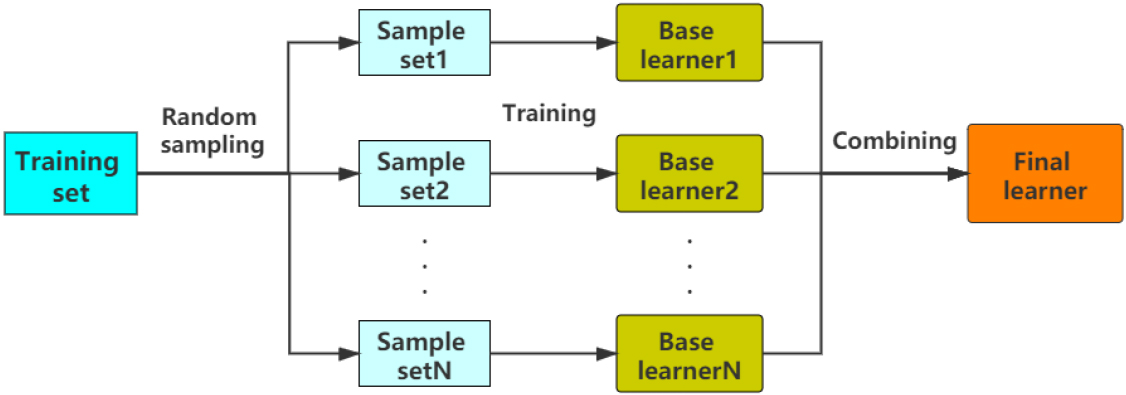
Stacking algorithm is a hierarchical model integration framework, a double-layer structure is adopted in this paper. The first layer is composed of multiple base learners, whose input is a original training set. The second layer model is based on the output of the first layer of base learners, as a feature added to the training set for retraining, so as to get a complete Stacking model. The description of stacking algorithm is shown in Algorithm 1.
: Description of Stacking algorithm[1] Training set
Accurate and comprehensive data samples are the basis of model training. The credit data set used in this paper consists of 29 features. Except the first attribute is character type, the attributes of other data are floating-point type and integer type, with a total of more than 50000 groups. In original data, there is a problem of non-standard data, which will affect the prediction results. Therefore, in order to obtain more accurate results, before data is substituted into models, we need to standardize the data to make it conform to standard. The main preparations are as follows.
Manual elimination of character features. For example, in the credit data set applied in this paper, the first attribute is user code, which has no effect on credit score, so we manually remove this item. Data normalization. We use min-max standardization method to make the linear transformation of original data, so that the result value can be mapped between [0–1]. This step can greatly reduce the training time of neural network for the data. The transformation function is shown in Eq. (1).
Where Correlation analysis. After character type features are eliminated, the remaining data are continuous variables. We use Pearson correlation coefficient to calculate. If samples are set as
Specifically,
The correlation coefficient of sample is expressed by
Where Using correlation analysis, we test whether there are variables that are not related to the target variables, and if they exist, we delete them. Default value processing. Due to the lack of data in data set, the lack of key data will greatly reduce the value of the whole data set, and finally can not get accurate results, so it is necessary to process the missing data.
We use the above method to process original data, making the data in data set more real and complete, which plays a very important role in data processing of the later model, and improves the accuracy of the model to predict enterprises credit score.
In Section 3.1, this paper describes the combination strategy based on Stacking and Bagging, and constructs a parallel double-layer prediction model. Next, we choose appropriate basic learners and build corresponding neural network to build a specific prediction model.
Decision tree model
In comparative study of Abellan and Castellano (2017), Decision Tree (DT) algorithm is regarded as the best basic classifier to build the overall credit scoring model. Here, we choose decision tree algorithm as a base learner. After standard data set
MAE value of different maximum depth.
[34] Because Support Vector Machine (SVM) follows the maximum margin hyperplane, it usually provides good generalization ability, which partly explains the popularity of SVM in credit scoring research. We choose support vector machine algorithm as another kind of base learner. After standard data set
Back-ProPagation network model
Back ProPagation (BP) neural network has the ability of self-learning, self-adaptive and generalization. We choose BP neural network as the third base learner. After standard data set
Data from input layer is
The hidden layer to the output layer is shown in Eqs (7) and (8).
The whole BP network model can be obtained by combining Eqs (5)–(8), as shown in Eq. (9).
The loss function is shown in Eq. (10).
Where
Different from the average idea of traditional bagging algorithm, because the importance of each base learner in integrated model is different, the automatic weight configuration model is used to configure different weights for each base learner. After selection and training of base learners, we automatically configure the weights of the three base learners and get new prediction data
Neuron structure of Automatic weight configuration.
Combing the prediction data generated by the base learner, take it as the input data
In order to evaluate the accuracy and generalization ability of the parallel double-layer prediction model, we implement the prediction model by coding. The data set of this experiment is public data set of credit score downloaded from GitHub. All experimental codes are Python code, the integrated development environment is PyCharm, and the version number is Community Edition 2019.1.3. PC parameters are Intel (R) core (TM) i5-6300HQ, CPU 2.30 GHz, 8.00 GB Memory, 64 bit windows 10 Operating System.
In Section 3.3, we select three basic learners to build the parallel double-layer prediction model. In order to test the effectiveness of the model, we use other four ensemble learning models for comparison, the details are as follows.
Used particle swarm optimization algorithm to optimize BP neural network (PSO-BP). The number of particle swarm is 40 and the number of iterations is 15. Used particle swarm optimization algorithm to optimize support vector machine (PSO-SVM). The number of particle swarm is 40 and the number of iterations is 40. XGBoost (eXtreme Gradient Boosting) adopts boosting iteration idea, the maximum depth of a single tree is 6, and the number of iterations is 10. Automatic weight allocation prediction model, which configures the weights of each base learner through neurons. The specific structure of neurons has been described in 3.3.4.
The performance evaluation criterion is an indispensable part of measurement model. There are many error measurement methods to evaluate the matching degree between model and observation data, such as MAE (Mean Absolute Error),
EVS (Explained Variance Score), explains the variance score of regression model, and its value range is [0, 1]. The closer to 1, the more independent variable can explain the variance change of dependent variable, and the smaller the value, the worse fitting effect it is. MAE (Mean Absolute Error), average absolute error, the formula is shown in Eq. (11).
Specifically, MSE (Mean Squared Error), is consistent with Eq. (10), as shown in Eq. (12).
The smaller the MSE index value, the better fitting effect it is.
Specifically,
Through four indicators introduced in 4.1, we analyze the accuracy of the model, and calculate
Histogram of each model index value. (a) EVS. (b) MAE. (c) MSE. (d) 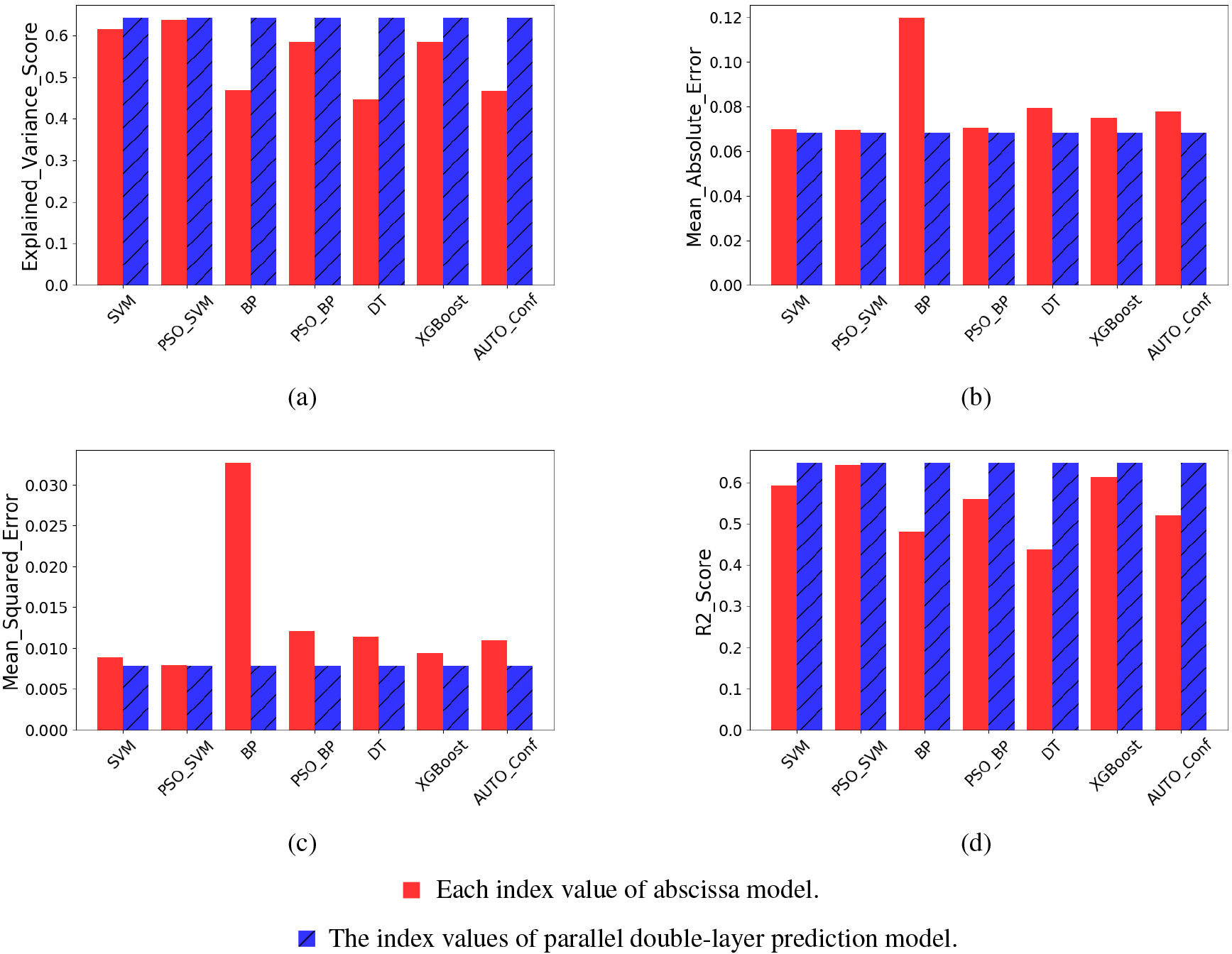
According to the analysis of above four evaluation indexes in Fig. 5, we can see that the four indexes show that the parallel double-layer prediction model using integrated technology is superior to other models, and the specific data of the four evaluation indexes are shown in Table 1.
Performance comparison of seven different models
The values in Table 1 represent the four index values of each model. It can be seen as follows.
The effect of SVM based learner model is better, and the ensemble learning model with automatic weight configuration is not as good as SVM model. After the corresponding ensemble improvement of a single base learner, four indicators of PSO-SVM model relative to SVM model, PSO-BP model relative to BP model, XGBoost model relative to DT model are improved. The parallel double-layer prediction model is better than the other four integrated models and three base learner models.
Specifically, compared with PSO-SVM model, PSO-BP model, XGBoost model and Auto-Conf model, it can be got as follows.
EVS value of the parallel double-layer prediction model is 0.00377, 0.05699, 0.05755 and 0.17468 higher. MAE value of the parallel double-layer prediction model is 0.00123, 0.00237, 0.00681 and 0.00967 lower. MSE value of the parallel double-layer prediction model is 0.00006, 0.00418, 0.00154 and 0.0031 lower.
In order to accurately get the actual improvement effect of the method proposed in this paper, we transform Table 1 to get data as shown in Table 2.
The improvement of the parallel double-layer prediction model compared with others
In Table 2, the corresponding values of four indicators are the promotion ratio of the parallel double-layer prediction model compared with other models, and results are expressed in percentage. From Tables 1 and 2, we observe that
The PSO-SVM model, PSO-BP model and XGBoost model are improved compared with the base learner model (SVM, BP network and DT). Among them, PSO-BP model and XGBoost model are improved greatly. After using Bagging method, the automatic weight configuration model is better than single BP network model and DT model, but not as good as single SVM model.
After adding Stacking method on the basis of Bagging method, the parallel double-layer prediction model has a great improvement compared with the three base learner prediction models. At the same time, compared with PSO-SVM model, PSO-BP model and XGBoost model, we observe that
EVS value increased by 1.722%, 9.761%, 9.866% and 37.471%. MAE value increased by 1.773%, 3.361%, 9.086% and 12.428%. MSE value increased by 0.753%, 34.574%, 16.296% and 28.287%.
PSO-SVM model, PSO-BP model and XGBoost model have different prediction accuracy due to different iterations. We set different iterations to train these three models, and the results are shown in Fig. 6.
Accuracy curve of different iterations.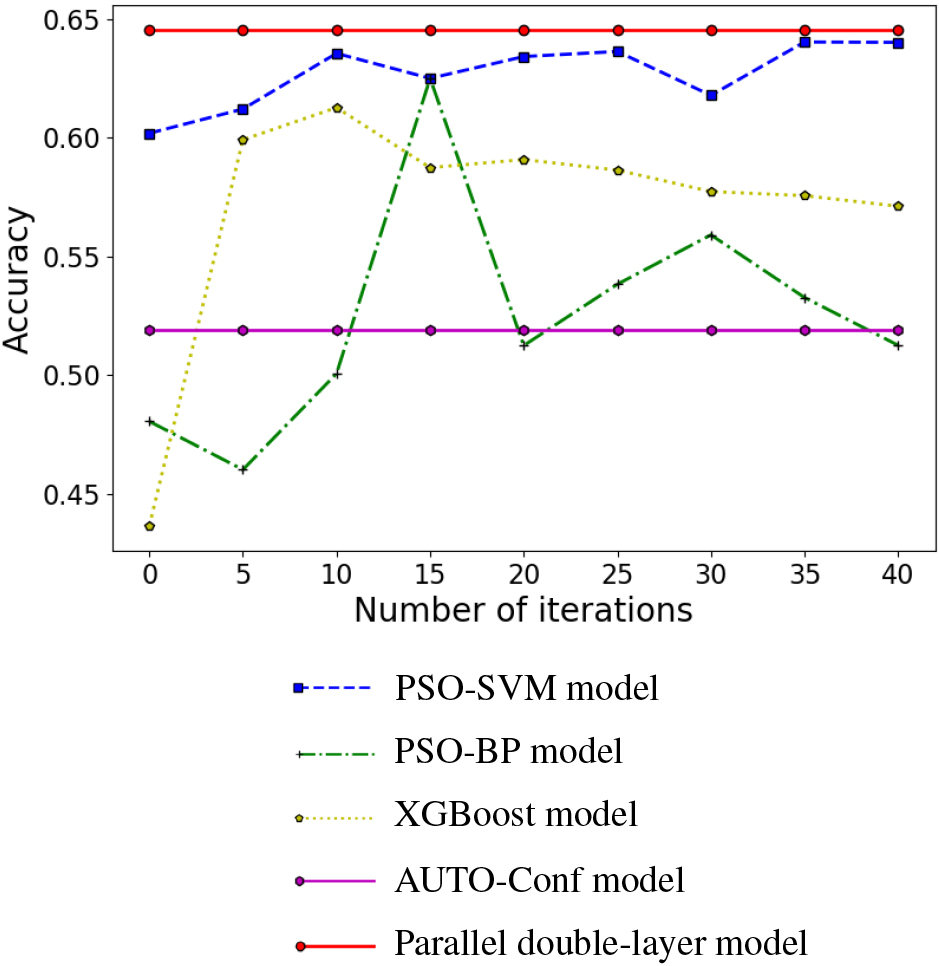
We can see from Fig. 6, PSO-SVM model tends to be stable when the number of iterations is close to 40, PSO-BP model has the best effect when the number of iterations is 15, and XGBoost model has the best effect when the number of iterations is 10. Therefore, in the begin of Section 6, we choose 40, 15 and 10 as the iterations of PSO-SVM model, PSO-BP model and XGBoost model.
In order to test the generalization ability of the model, we test five data sets and get the four index values corresponding to each data set. We use line chart to visualize the
Index curve of each model. (a) EVS. (b) MAE. (c) MSE. (d) 
In Fig. 7a, about 7/8 of the parallel double-layer prediction model is better than PSO-SVM model, about 7/8 is better than PSO-BP model, about 3/4 is better than XGBoost model, and about 7/8 is better than automatic weight configuration model. In Fig. 7b, about 3/4 of the parallel double-layer prediction model is better than PSO-SVM model, about 15/16 is better than PSO-BP model, about 3/4 is better than XGBoost model, and about 15/16 is better than automatic weight configuration model. In Fig. 7c, about 3/4 of the parallel double-layer prediction model is better than PSO-SVM model, about 11/16 is better than PSO-BP model, about 3/4 is better than XGBoost model, and about 7/8 is better than automatic weight configuration model. In Fig. 7d, about 15/16 of the parallel double-layer prediction model is better than PSO-SVM model, about 15/16 is better than PSO-BP model, about 11/16 is better than XGBoost model, and about 15/16 is better than automatic weight configuration model.
Specifically, abscissa Number of data represent five data sets. We can see from Fig. 7 that the parallel double-layer prediction model is better than the other four ensemble learning models on the whole, which proves that the model has good generalization ability.
Nowadays, credit evaluation has more and more influence on the external image of enterprises. How to improve the accuracy of main credit evaluation has become a hot issue. Many enterprises use traditional single algorithms and neural network algorithms in credit evaluation, or use optimization algorithms to optimize a single model. There are some shortcomings in interpretability, accuracy or generalization ability. In order to improve the accuracy and generalization ability of prediction, this paper proposes a parallel double-layer prediction model, the model based on Stacking and Bagging integration technology, which not only improves accuracy, but also has good generalization ability.
Specifically, this paper integrates DT model, SVM model and BP neural network model. Breaking the traditional integration way, we use three models to predict training data set, processing results and updating them to the data set. The best prediction effect of the data set used in this experiment is SVM model, and then training the second layer of SVM model with the updated data set. Finally, model generates final credit score.
From experimental analysis and comparison, it can be seen as follows.
The parallel double-layer prediction model is superior to other models in four evaluation indexes. The parallel double-layer prediction model improves the accuracy of enterprise credit scoring, and performs best in other data sets, with good generalization ability.
The combination strategy of this paper can develop a practical method to evaluate enterprises credit. The research results provide a way of thinking for solving the problem of enterprises credit evaluation, and also provide a solid foundation for the theoretical research of subject intelligent check.
Footnotes
Acknowledgments
This work was funded by the National Key Research and Development Program of China under Grant 2019YFB1405000. The authors also,acknowledge with thanks Professors in Xi’an University of Science and Technology for theoretical support.