
Abstract
The commonly used high utility itemsets mining method for massive data is the intelligent optimization algorithm. In this paper, the WHO (Whale-Hawk Optimization) algorithm is proposed by integrating the harris hawk optimization (HHO) algorithm with the beluga whale optimization (BWO) algorithm. Additionally, a whale initialization strategy based on good point set is proposed. This strategy helps to guide the search in the initial phase and increase the diversity of the population, which in turn improve the convergence speed and algorithm performance. By applying this improved algorithm to the field of high utility itemsets mining, it provides new solutions to optimization problems and data mining problems. To evaluate the performance of the proposed WHO, a large number of experiments are conducted on six datasets, chess, connect, mushroom, accidents, foodmart, and retail, in terms of convergence, recall rates, and runtime. The experimental results show that the convergence of the proposed WHO is optimal in five datasets and has the shortest runtime in all datasets. Compared to PSO, AF, BA, and GA, the average recall rate in the six datasets increased by 32.13%, 49.95%, 12.15%, and 16.24%, respectively.
Keywords
Introduction
High utility itemsets mining (HUIM) is an important topic in the field of data mining [1] and has been widely studied. Several deterministic algorithms have been proposed to mine high utility itemsets (HUIs) [2–5]. However, the performance of these algorithms tends to decrease as the dataset size and the number of different items increase [6]. Furthermore, HUIs are often dispersed in the search space, which requires traditional deterministic algorithms to spend many resources, such as time and space, to determine whether a large number of candidate sets are HUIs. Heuristic algorithms [7–10], on the other hand, have the ability to solve complex, linear, and highly nonlinear problems, exploring large problem spaces and finding optimal or near-optimal solutions based on fitness functions. Therefore, the combination of heuristic algorithms and HUIM can be a great solution to the above problem, i.e., a lot of HUIs can be found quickly in a shorter period of time.
Kannimuthu et al. [11] applied the genetic algorithm (GA) to HUIM and introduced the HUPEUMU-GARM algorithm, which requires specifying a minimum utility threshold (minutil), and the HUPEWUMU-GARM algorithm, which does not require specifying a minutil. This is the first application of heuristic algorithms in HUIM, enabling rapid and efficient discovery of HUIs within an exponential search space, but a large number of itemsets are missed. Lin et al. [12] proposed the HUIM-BPSO algorithm, which is the first application of particle swarm optimization (PSO) in HUIM. A sigmoid function is used in the updating process of the particles and an OR/NOR-tree structure is developed to store the itemsets in the dataset. Prune invalid combinations of particles at an early stage to avoid multiple scans of the database. However, limiting the search space leads to a reduction in the diversity of the population, and thus results in a large loss of itemsets. Song et al. [13] modeled the HUIM problem from the perspective of artificial bee colony (ABC) algorithm. The method utilizes bitmaps for information representation and search space pruning, accelerated the discovery of HUIs. Song et al. [14] studied the HUIM problem from the perspective of artificial fish swarm algorithm (AFSA) and proposed a high utility itemsets mining algorithm named HUIM-AF. Pazhaniraja et al. [15] proposed the DE-BGWO method, which combines grey wolf optimization and dolphin echolocation optimization to find HUIs. Furthermore, heuristic algorithms can be employed to mine complex patterns of HUIs. For instance, Song et al. [16] developed the HAUI-PSO algorithm based on the standard PSO method for mining high average utility itemsets (HAUIs). Lin et al. [17] presented the DcGA algorithm, a GA-based approach that efficiently mines closed high utility itemsets (CHUIs) within a limited time frame. Song et al. [18] proposed the cross-entropy based algorithm TKU-CE+ for heuristically mining top-k HUIs. Luna et al. [19] proposed the TKHUIM-GA algorithm for mining top-k HUIs. The search process is guided by considering the utility of each term to generate an initial solution and combining the solutions accordingly, which can reduce the running time and memory.
In addition, more heuristic-based HUIM methods will be described in detail in Chapter 2. Upon analysis, it is evident that the heuristic-based HUIM problems generally exhibit the following characteristics: All algorithms tend to lose a varying number of itemsets to some extent. Bitmap-based storage has the advantage of high operational efficiency. Algorithms based on swarm intelligence optimization tend to outperform other heuristic-based HUIM algorithms. The parameter settings of the algorithm can greatly affect the results of the experiment. For example, if the population is too small, it will lead to slower search speed and lower convergence; if the population is too large, it may lead to resource wastage. A small number of iterations will make the algorithm run in a short time, but it may result in the discovery of very few HUIs and a lower recall rate for the algorithm; with too many iterations, the recall of the algorithm may increase, but it may decrease the efficiency.
Based on the characteristics of heuristic-based high utility itemset mining methods, the motivations of this study are as follows: The current heuristic-based HUIM tends to miss a large number of itemsets, resulting in the loss of a large amount of meaningful and valuable information. Therefore, it is important to reduce the miss of itemsets. Information is real-time and time-sensitive, and it is very important to obtain valuable information quickly for the real world. However, the efficiency of the current heuristic-based HUIM algorithms needs to be improved. This paper is proposed to reduce the miss of itemsets, improve the algorithm recall, and improve the algorithm mining efficiency. The motivations behind choosing the harris hawk optimization (HHO) algorithm and the beluga whale optimization (BWO) algorithm are as follows: Firstly, they have few parameters and are easy to understand and implement. Secondly, HHO has high search accuracy and fast convergence, but it also has the problem of premature convergence and limited diversity of solutions. The BWO algorithm, on the other hand, has strong exploration ability in the early iterations, which can make up for HHO’s limited early convergence.
The main contributions of this paper are are presented bellow: This paper proposes an algorithm, named WHO (Whale-Hawk Optimization), which hybridizes harris hawk optimization and beluga whale optimization algorithms. Meanwhile, it is applied to high utility itemset mining, effectively enhancing both the algorithm’s convergence and itemsets mining capabilities. We propose a good point set-based beluga whale initialization strategy, which helps increase the whale population diversity. This strategy addresses the limitations of poor population quality and instability, preventing the algorithm from getting trapped in local optima. Extensive experiments demonstrate that our proposed algorithm outperforms state-of-the-art intelligent optimization-based approaches for high utility itemset mining in terms of convergence, recall rate, and runtime.
As shown in Fig. 1, the remainder of the article is organized according to the following structure. Chapter 2 gives an introduction to the related work, Chapter 3 gives the proposed algorithm, Chapter 4 conducts the experiments and Chapter 5 concludes.
Research roadmap.
This chapter begins by providing an overview of heuristic high utility itemset mining methods. Then, giving the fundamental concepts of HUIM. Subsequently, the harris hawk optimization algorithm and the beluga whale optimization algorithm are introduced separately.
Heuristic-based HUIM
The application of intelligent optimization algorithms improves the efficiency of itemset mining in massive data. Previously proposed heuristic HUIM methods can be categorized into genetic algorithm (GA)-based, swarm intelligence-based, and other intelligence-based methods.
Kannimuthu et al. [11] proposed the first heuristic-based method HUPEUMU-GRAM for mining high utility itemsets. Modeling the HUIM problem using the genetic algorithm, where genes correspond to items in the dataset, and chromosomes correspond to possible itemset combinations. The length of a chromosome is determined by the number of high transaction-weighted utility 1-itemsets in the dataset, and the fitness function value is determined by the utility of the itemset represented by the current chromosome. In addition, the mutation probability is adaptively varied according to the number of iterations and the magnitude of the fitness function value for the offspring. Based on this, Kannimuthu also proposes a top-k HUIM mining method, HUPEWUMU-GARM, that does not require the specification of a minimum utility threshold (minutil). Song et al. [20] introduced a bio-inspired computation-based framework, Bio-HUIF, for mining HUIs. This framework utilizes bitmap encoding for itemsets and databases, where the length of the bitmap corresponds to the number of “1s” in an individual, effectively reducing memory usage. They also proposed and designed the PEVC pruning strategy to check if the itemset corresponding to the current individual exists in the original dataset. Building upon Bio-HUIF, Song et al. [20] introduced a HUIM method called Bio-HUIF-GA based on genetic algorithms. This method employs boolean changes between different positions in the vector to simulate the crossover and mutation processes typical of genetic algorithms. Zhang et al. [21] introduced a HUIM method called HUIM-IGA, based on an improved genetic algorithm. They designed a population diversity maintenance strategy that can reduce the loss of itemsets. Furthermore, a neighborhood exploration strategy for repeated HUIs was proposed to speed up the search for new HUIs. J.C.-W. Lin et al. [17] proposed the decomposition based on a compact genetic algorithm methods DcGA to mine CHUIs efficiently. This method process starts by transforming the transaction database into a graph network, an edge is created among two transactions if it exists shared item between these transactions. The community detection is applied to create a community of transactions, and each community contains highly correlated transactions. After that, the compact genetic algorithm is applied to each community for handling the grouped transactions to find the local closed high utility patterns of each community. Based on this, J.C.-W. Lin et al. proposed the multi-objective model MCUI-Miner [22] for mining the closed high utility itemsets, which employs MapReduce frameworks of a Spark structure. Experimental results demonstrate that, the MCUI-Miner outperforms the conventional CLS-Miner [23] in terms of runtime, memory use, and scalability. Luna et al. [19] proposed a top-k high utility itemsets mining method, TKHUIM-GA, based on a genetic algorithm. It guides the search process by considering the utility of each item to produce initial solutions and to combine solutions accordingly, reducing the runtime and memory consumption as a result. The proposed vertical data representation creates a list of indices of transactions in which each item appears. The length of each list denotes the support of such an item.
Swarm intelligence-based HUIM methods can be further divided into particle swarm optimization (PSO)-based, ant colony optimization (ACO)-based, and other swarm intelligence optimization-based techniques.
Particle swarm optimization algorithms, known for their simplicity, few parameters, and ease of understanding and implementation, are widely applied in high utility itemset mining. J.C.-W. Lin et al. [24] introduced a HUIM method called HUIM-BPSOsig based on PSO. This marks the first application of PSO in HUIM. The method uses TWU pruning for initial database processing and leverages the sigmoid function to convert continuous individuals into Boolean types for individual-itemset correspondence. Based on this, J.C.-W. Lin et al. [12] introduced the HUIM-BPSO method. The proposed OR/NOR-tree structure can effectively avoid the combination of invalid particles. Based on the Bio-HUIF framework, Song et al. [20] proposed the high utility itemset mining method, Bio-HUIF-PSO, which is based on the particle swarm optimization algorithm. Initially, 1-itemset’s transaction-weighted utility (twu) is calculated, and items with twu values lower than the minutil are removed from the dataset to create a reorganized dataset. Subsequently, the bit-difference operator is utilized for population replacement and the discovery of HUIs. Wang et al. [25] introduced the HUIM-IPSO method for mining HUIs. The algorithm employs a roulette wheel selection method to probabilistically choose initial optimization values for the next generation population from the high utility itemsets of the current generation. Positions with higher TWU have a higher probability of being selected, which accelerates the mining speed of HUIs. Song et al. [26] proposed an HUIM algorithm based on set-based PSO (S-PSO) called HUIM-SPSO, and proposed the measure of the bit edit distance to reflect the diversity of the mining results. Fang et al. [27] proposed a HUIM method HUIM-IBPSO based on the improved binary particle swarm optimization. HUIM-IBPSO have multiple adjustment strategies in order to improve the mining efficiency, such as particle movement direction adjustment strategy, local exploration strategy for duplicate HUIs, restart strategy, particle modify strategy, and fitness value hash strategy. Subramaniana et al. [28] proposed GA-PSO to mine high utility itemsets. In the work, PSO is combined with GA to improve the standard PSO performance. Logeswaran et al. [29] proposed the Adaptive particle swarm optimization using reinforcement learning with off policy (APSO-RLOFF), which employs the reinforcement learning (RL) concept to achieve the adaptive online calibration of PSO control and, in turn, to increase the performance of PSO. Gunawan et al. [30] proposed a method to improve the state-of-the-art BPSO-based high utility itemset mining by tuning the method’s initial population, inertia weight, acceleration coefficient, and velocity clamping. Yang et al. [31] proposed a particle filter-based method PF-HUIM to mine high utility itemsets. This approach first initializes a population, which consists of particle sets. Then, to update the particle sets and their weights, a novel state transition model is suggested. Finally, the approach alleviates the particle degradation problem by resampling. Sukanya et al. [32] proposed a differential evolution (DE) and (PSO)-based HUIM method HUIM-DE-PSO-DE. It using multiple strategies to discover HUIs, including elitism, population diversifications, exclusive preservations, and neighborhood exploration techniques. Song et al. [16] introduced two algorithms for mining high average utility itemsets (HAUIs): HAUI-PSO, based on the standard PSO algorithm, and HAUI-PSOD, based on the bio-inspired HUI framework Bio-HUIF. The algorithms use an initial pruning based on the average-utility upper bound (AUUB), effectively improving the algorithm’s runtime efficiency. Experimental results demonstrate that the former is more efficient, while the latter exhibits stronger convergence. Gunawan et al. [33] introduced a method, HUIM-BPSO-nomut, for mining top-k HUIs without the need for pre-setting the minutil. In the preprocessing stage, the algorithm sorts the original dataset based on the transaction utility, and it employs binary particle swarm optimization (BPSO) to mine itemsets. The discovered itemsets are then output in order of utility value in a list, with the minutil added to the list for subsequent processing steps.
Ant colony algorithm is a bio-inspired algorithm derived from the natural world, which extensively draws from the foraging behavior of ants. Wu et al. [34] introduced a high utility itemset mining method based on ant colony algorithm, named HUIM-ACS. This method maps the complete solution space of the HUIM problem into a routing graph. It includes two pruning processes, positive pruning and recursive pruning, to avoid unnecessary estimations of itemsets. Additionally, it introduces a checking mechanism to verify the discovery of all HUIs in the dataset. Infrequent itemsets are rare but may yield significant returns. Arunkumar et al. [35] introduced a method called ACHUIIM, which uses the ant colony algorithm to mine infrequent high utility itemsets (IHUIs). If an itemset is high utility and has no superset with the same support, it is referred to as a closed high utility itemset (CHUIs). Pramanik et al. [36] introduced a method called CHUI-AC, based on the ant colony algorithm, which modified the global update rules and the improved routing graph with l + 1 nodes, resulting in l(l + 1)/2 edges.
Other swarm intelligence optimization algorithms like artificial bee colony (ABC), bat algorithm (BA), grey wolf optimization algorithm (BWO), artificial fish swarm algorithm (AFSA), and more, can also be applied to high utility itemset mining. HUIM-ABC method was proposed by Song et al. [13] which models HUIM from the perspective of the ABC. The original dataset is converted into a bitmap format, and a promising bit vector check (PBVC) pruning strategy is designed to trim the search space and accelerate algorithm convergence. Additionally, the direct nectar source generation (DNSG) strategy was proposed to generate more promising new nectar sources as early as possible so that more HUIs can be discovered within a certain number of cycles and the computational cost can also be lowered. Based on the Bio-HUIF framework, Song et al. [20] introduced the high utility itemset mining method, Bio-HUIF-BA, based on the bat algorithm. They rewrote the bat’s position update formula and used boolean operations on bitmap bit vectors to simulate the bat’s exploration process. Pazhaniraja et al. [37] introduced the binary grey wolf optimization algorithm (BGWO) and applied it to HUIM, proposing the BGWO-HUI method. The proposed model is modelled with Boolean operations such as De Morgans’s AND, Adder, Difference, Circular Shift and Multiplexer. Pazhaniraja et al. [38] proposed a high utility itemsets mining methods HUIM-DE which is based on GA and the dolphin echolocation optimization (DEO). The algorithm has two variants: one that utilizes a minimum utility threshold to mine all HUIs in the dataset, and another that doesn’t use a minimum utility threshold to mine the top-k HUIs. Building upon BGWO-HUI and HUIM-DEO, Pazhaniraja et al. [11] introduced a new heuristic algorithm, DE-BGWO, which combines dolphin echolocation (DE) and binary grey wolf optimization algorithms (BGWO). This hybrid algorithm was then applied to the problem of HUIM. Song et al. [14] proposed the HUIM-AF method, model the HUI mining problem with three behaviors of artificial fish: follow, swarm, and prey.
Apart from the algorithms mentioned above, other intelligent optimization algorithms like differential evolution (DE), multi-objective evolutionary algorithm (MOEA), cross-entropy (CE), and more have also been applied to the mining of HUIs. Differential evolution has long been successfully applied to solving the problems of high dimensions. Further DE is robust and quick compared to GA. Therefore, Krishna et al. [39] proposed TNR-HUARM methods to mine top non-redundant high utility association rule, the method is based on binary differential evolution (BDE) and an adaptive binary differential evolution (ABDE). Furthermore, the author explored a possible application of the TNR-HUARM for the analytical CRM, i.e. customer segmentation based on monetary value of the customers. Unlike HUIM, in the TNR-HUARM method, fitness is defined as the product of utility value and confidence. Based on this, Krishna et al. [40] introduced a HUIM method based on DE. This method has two different variants, namely HUIM-BDE, which is based on binary differential evolution, and HUIM-ABDE, which is based on adaptive binary differential evolution. Usually, the higher support of an itemset X will lead to lower utility in most cases, while the lower support of X often leads to higher utility. Zhang et al. [41] considered support and utility in a unified framework from a multi-objective view, transformed the problem of mining frequent and high utility itemsets (FHUIs) as a 2-objective problem. They proposed a multi-objective evolutionary algorithm named MOEA-FHUI to solve the transformed multi-objective itemset mining, which does not need to specify the prior parameters such minimal support threshold and minimal utility threshold. Cao et al. [42] introduced two update strategies, including updating strategy based on closed itemsets (USC) and updating strategy based on approximate-closed itemsets (USA)£¬with the aim of accelerating the convergence of population as well as improving the diversity of population. Based on these two strategies, an effective multi-objective evolutionary algorithm, names CP-MOEA, is suggested for the task of mining FHUIs. The CP-MOEA adopts the similar framework with NSGA-II [43], where two objectives, namely support and utility, are optimized simultaneously. When both the number of transactions and the number of items in a transaction database are large, MOEA may be inefficient. To address this issue, Fang et al. [44] proposed BOEA-FHUI for mining FHUIs based on the bio-objective evolutionary algorithm (BOEA). This method includes three strategies, namely TWU pruning strategy, repair strategy, and the improved mutation strategy. Ahmed et al. [45] considered both utility and uncertainty as the majority objects, developed a multi-objective evolutionary approach MOEA-HEUPM to mine high expected utility patterns (HEUPs) model. Two encoding schemas, binary encoding and value encoding are developed and utilized in the designed MOEA-HEUPM model. In most cases, the higher the support of a pattern, the lower the occupancy and utility value, and the lower the support of the pattern, the higher the occupancy and utility value. In order to get the maximum compromise solution, Fang et al. [46] proposed a multi-objective problem model MOEA-PM to mine high quality patterns (HQPs), where the objectives are support, occupancy, and utility. Two kinds of population initialization strategies are designed, which is used to ensure the population is effectively distributed in the feasible solution space. Song et al. [18] proposed two algorithms, called the top-k high utility itemset mining based on cross-entropy method (TKU-CE) and TKU-CE+, for mining the top-k HUIs heuristically. The TKU-CE algorithm is based on cross-entropy, and implements top-k HUI mining using combinatorial optimization. The main idea of TKU-CE is to generate the top-k HUIs by gradually updating the probabilities of itemsets with high-utility values. TKU-CE+ optimizes TKU-CE in three respects. First, unpromising items are filtered by critical utility value, to reduce the computational burden in the initial stage. Second, a sample refinement strategy is used in each iteration, to reduce the computational burden in the iterative stage. Finally, smoothing mutation is proposed, to randomly generate some new itemsets in addition to those from previous iterations. Consequently, diversity of samples is improved, so that more actual top-k HUIs can be discovered with fewer iterations. Nawaz et al. [6] modeled the problem of HUIM from the perspective of HC and SA algorithms. The database is converted into a bitmap, which is used both for information representation and search space pruning. Instead of maintaining the HUIs with highest utility value from population to population, the strategy of selecting discovered HUIs probabilistically for the next population is used. This strategy allows to discover more HUIs in less iteration cycles.
Table 3 provides a summary of heuristic-based HUIM methods, categorizing and ranking them based on the related publications, research objectives, and applications. In the table, “n” represents the population size, “T” represents the algorithm’s maximum number of iterations, and “d” represents the length of individuals.
Utility list
Utility list
Transaction list
Summary of heuristic-based high utility itemset mining methods
This section introduces the HUIM and the related definition of HUIM in data streams. Let I = {i1, i2, i3,..., i n } be a set of items, and let DB be a database with a utility list (Table 1) and a transaction list (Table 2). In Table 2, each row represents a transaction, where each letter within the transaction denotes an item along with its corresponding internal utility displayed on the right-hand side. Within the transaction list, each transaction denoted as T, possesses a unique identifier which is expressed as tid. A set of items is referred to as a k-itemset if it is a subset of I and consists of k elements.
For instance, considering Table 1, item “A” has an external utility denoted as eu(A) equal to 1.
For instance, considering Table 2, the internal utility of item “A” within T1 is denoted as iu(A, T1) and has a value of 4.
According to the given example, when considering the utility of item “A” in T1, the calculation is performed as follows: u(A, T1) = iu(A, T1)×eu(A) = 4×1 = 4. This demonstrates that the utility of “A” in T1 is determined to be 4.
For instance, let’s examine the utility of the itemset {A, B} in two different transactions, T1 and T3. In transaction T1, we calculate the utility of {A, B} by summing the utilities of items a and b within T1. Thus, u({A, B}, T1) is determined as u(A, T1)+u(B, T1), which evaluates to 4×1 + 4×3 = 16. Similarly, in transaction T3, the utility of {a, b} is computed by adding the utilities of items a and b within T3. Hence, u({A, B}, T3) equals u(A, T3) + u(B, T3), resulting in 2×1 + 1×3 = 5.
For instance, the utility of the {A, B} denoted as u({A, B}), is obtained as the sum of u({A, B}, T1) and u({A, B}, T3), resulting in a value of 16 + 5 = 21.
The cumulative utility of the database in Table 1 is obtained by summing the individual utilities of all transactions. It can be expressed as the sum of tu(T1), tu(T2), tu(T3), tu(T4), tu(T5), and tu(T6), which evaluates to 28 + 23 + 27 + 23 + 16 + 12 = 129. This calculation reflects the total utility derived from all transactions and signifies the overall utility of the database.
For instance, the twu of {A} can be calculated by summing the transaction utilities of all transactions containing the itemset in the database and is obtained as the sum of tu(T1), tu(T3), and tu(T5) which equal 28, 27, and 16, respectively, resulting in a total twu of 71. The twu values for all 1-itemsets in the database are presented in Table 4, showcasing the contributions of these itemsets to the overall utility of the transactions.
The twu of 1-itemsets
For example, if minutil = 70, there are five 1-HTWUIs in DB, {A}, {B}, {C}, {D}, {E}, and the 1-LTWUI is {F}, because only {F} has a twu less than 70, and all the other 1-itemsets have a transaction-weighted utility no less than 70.
Harris hawk optimization [47] is a heuristic algorithm proposed by Heidari et al. in 2019.
The HHO approach employs hawks as the representation of candidate solutions, with the optimal or nearly optimal solution being referred to as the prey. The HHO is divided into the exploration phase and exploitation phase, in the exploitation phase the hawk changes its behavior according to the escape energy of prey. The escape energy E of the prey is shown in Equation (6). Where t is the number of current iterations, T is the maximum number of iterations, E0 is the initial escape energy of the prey (obtained from Equation (7)), and r is a random number in [0, 1].
(1) Exploration phase
During the exploration phase, the position of the hawk is updated using Equation (8). This equation incorporates various variables, such as X, X
k
, X
r
, t, ub, lb, r1, r2, r3, r4, and q. Specifically, X represents the position of the hawk, X
k
represents the position of a randomly chosen hawk, X
r
represents the position of the prey (i.e., the global optimal solution or gbest), and ub and lb represent the upper and lower bounds of the search space. Additionally, the equation involves five random numbers (r1, r2, r3, r4, and q), each of which falls within the range [0, 1]. X
m
denotes the mean position of the current population and can be calculated as shown in Equation (9). X
n
refers to the nth hawk in the current population, while Num represents the total number of hawks in the population (i.e., population size) [47].
(2) Exploitation phase
a. Soft besiege
During a soft besiege scenario, r is greater than or equal to 0.5 and the absolute value of E is no less than 0.5. To update the hawk’s position, Equation (10) is employed, which considers several parameters such as ΔX, J, and r5. ΔX refers to the distance between the current hawk and its prey while J represents the jump energy, which is calculated using Equations (11) and (12). Additionally, r5 is a random number generated within the range of [0, 1] during every iteration [47].
b. Hard besiege
The hard besiege arise when r≥0.5 and |E| < 0.5. During such times, Equation (13) is employed to update the hawk’s location [47].
c. Soft besiege with progressive rapid dives
If r is less than 0.5 and the absolute value of E is greater than or equal to 0.5, a gradual dive strategy is executed, known as soft besiege with progressive rapid dives. This tactic updates the hawk’s position using Equation (14) [47].
In the above equation, F (.) represents the fitness function, while Y and Z are the two hawks newly generated using Equations (15) and (16), respectively. The variable D denotes the dimension of the hawk, α is a random D-dimensional vector, and the function Levy (Equation (17)) represents the Levy flight [47].
In this equation, μ and ν are two distinct random numbers that originate from a normal distribution. σ can be computed using Equation (18), while β is a predefined constant with a value of 1.5 [47].
d. Hard besiege with progressive rapid dives
During instances where r is less than 0.5 and the absolute value of E is also less than 0.5, the HHO executes the hard besiege with progressive rapid dives. To update the hawk’s position in this scenario, Equation (19) is applied [47].
Where F(.) is the fitness function, Y and Z are the two most recently generated hawks obtained from Equations (20) and (21) respectively [47].
Too et al. [48] introduced the binary harris hawk optimization algorithm (BHHO) for feature selection. In the t-th iteration, the position of the i-th hawk in the d-th dimension is represented as Xid(t), and the position obtained using HHO for the (t + 1)-th iteration is denoted as ΔXid(t + 1). At this point, ΔXid(t + 1) is a continuous variable. BHHO converts this continuous variable into a Boolean variable using Equations (22) to (23).
The beluga whale optimization algorithm [49] is a metaheuristic optimization algorithm introduced in 2022, drawing inspiration from the behavioral patterns of beluga whales. Beluga whales are famous for their pure white coloration as adults and are highly social animals that form groups. Much like other metaheuristic approaches, BWO comprises exploration and exploitation phases. Furthermore, this algorithm replicates the phenomenon of whale pods observed in the natural world.
In the beluga whale optimization algorithm, each beluga whale is considered as a candidate solution and undergoes updates throughout the optimization process. The position of a beluga whale [49], denoted as X, is modeled by Equation (24).
Where n represents the population size of beluga whales, and d is the dimensionality of the problem. In the context of high utility itemset mining problems, d signifies the count of 1-HTWULs. For all beluga whales [49], the corresponding fitness function values are stored as per Equation (25).
The beluga whale optimization algorithm can transition from global exploration to local exploitation, depending on the balance factor Bf [49], which is mathematically modeled as Equation (26).
Where t represents the current iteration, T is the maximum number of iterations, and B0 varies randomly between (0, 1) in each iteration. The exploration phase occurs when the balance factor Bf > 0.5, while the exploitation phase occurs when B f ≤0.5. As the iteration t increases, the fluctuation range of B f decreases from (0, 1) to (0, 0.5), indicating a large shift in the probability of exploitation and exploration phases, with the probability of the exploitation phase increasing as the iteration t continues to grow.
(1) Global exploration
The global exploration phase in BWO is constructed by emulating the swimming behavior of beluga whales. Two beluga whales swim closely together either synchronously or in a mirror-like fashion, and their positions are updated based on the parity of parameters [49], as depicted in Equation (27).
Where t represents the current iteration number, X i j (t + 1) is the new position of the i-th beluga whale in the j-th dimension, pj is a randomly selected dimension from the d dimensions, X i j (t) is the position of the i-th beluga whale in the j-th dimension at the current time, X i pj (t) is the position of the i-th beluga whale in the pj dimension at this moment, and X r p 1(t) is the position of a randomly selected beluga whale in the pj dimension at this time. The sin(2πr2) and cos(2πr2) terms are used for introducing randomization between the flippers. Depending on the selection of odd or even dimensions, the updated positions reflect the synchronous or mirror-like behavior of beluga whales during swimming or diving.
(2) Local exploitation
The local exploitation phase of BWO emulates the feeding behavior of beluga whales. During this phase, each beluga whale can adjust its position and collaborate with neighboring whales in search of food. In this cooperative foraging process, beluga whales share positional information [49], taking into account the best candidate solution as well as other solutions, as expressed in Equation (28).
In this context, t denotes the current iteration number, X
i
j
(t) represents the position of the i-th beluga whale in the j-th dimension, X
r
j
(t) corresponds to the position of a randomly selected beluga whale in the j-th dimension, and X
best
(t) denotes the best position within the group of whales. The variables r3 and r4 are random numbers within the range of (0, 1), and C1, defined in Equation (29), quantifies the random leap intensity of Levy flights [49], which measures the stochastic jump strength.
(3) Whale fall phase
During their migration and feeding periods, beluga whales face threats from orcas, polar bears, and human activities. Most beluga whales exhibit high levels of intelligence and can evade these threats through information sharing among themselves. Nevertheless, a small number of beluga whales do not survive and descend to the depths of the ocean floor, where they become prey for other marine creatures. This phenomenon is referred to as “whale fall.” To maintain a stable population, updates to the positions of beluga whales are determined based on their locations and the descent step size of the whale pods [49]. This mathematical model is represented by Equation (30).
In this context, r5, r6, and r7 are random numbers within the range of (0, 1), and X
step
represents the step size of the whale pods’ descent [49]. It is defined as per Equation (31).
In which, C2 is the step factor associated with the probability of whale pods descent and the population size, defined as Equation (32), where ub and lb represent the upper and lower bounds of the variables. It can be observed that the step size is influenced by variable parameters, the number of iterations, and the maximum number of iterations [49].
In this model, the probability of whale fall [49], denoted as W
f
, is calculated as a linear Equation (33).
The probability of whale fall decreases from 0.1 at the initial iteration to 0.05 at the final iteration. This suggests that as the optimization process progresses, the beluga whales are getting closer to a food source, and the level of threat to them gradually decreases.
This paper first introduces a beluga whale individual encoding strategy based on bitmaps and a beluga whale initialization strategy based on good point set. Secondly, this paper integrates the harris hawk optimization algorithm with the beluga optimization algorithm and applies it to HUIM. This section provides a detailed analysis and explanation of the WHO algorithm, covering the strategies and definitions, algorithm introduction and description, and the pseudocode of WHO.
Strategies and definitions
In this study, a bitmap encoding approach is employed to represent individual whales. Each whale is represented by a Boolean vector consisting of 0 s and 1 s Let the itemset corresponding to whale A
i
be denoted as X
i
. Then, the bitmap of A
i
, denoted as Bitmap(A
i
), is defined as in Equation (34).
Where twupattern is an array comprising all 1-HTWUIs in the dataset, sorted in their original order. For example, if all 1-HTWUIs in the dataset are {A, B, C, D, F}, then the bitmap representation of the itemset {A, C} is < 10100 > . The bitmap of the restructured database, as transformed in Table 1, denoted as Bitmap(DB), is illustrated as follows:
For instance, consider the individual A1 = < 10001>, which corresponds to the itemset {A, F}. The fitness function value for A1, denoted as Fit(A1), is equal to the utility value of the itemset {A, F} within the transaction dataset DB, which is 5.
For example, suppose minutil = 10. Since Fit(A1) = 5 < 10, individual A1 is considered an invalid individual.
In heuristic algorithms, the initialization of a population significantly impacts the algorithm’s performance. To enhance the initial population quality and stability of the algorithm and mitigate its susceptibility to local optima, we propose a population initialization strategy based on good point set. First, initialize an empty list named “population” to store individual whales representing the population. Next, for each whale in the population, denoted as “A i ”, create an empty individual to represent that whale’s state. For every 1-HTWUI in the database “DB”, calculate the parameter “p” and compute the value of “r(j)” using equation (38). Then, determine the position of individual “A i ” using equation (39). Finally, add the individual “A i ” to the “population” list. This population initialization strategy, grounded in good point set, aims to improve the initial performance of the algorithm, addressing the requirements of high utility itemset mining tasks effectively.
For instance, when the number of 1-HTWUIs in the dataset is 5, the population initialization process unfolds as follows. First, for the first individual, when j = 1,
when j = 2,
when j = 3,
when j = 4,
when j = 5,
Therefore, the initial position of the first whale is A11 = < 1.96, 1.79, 1.37, 0.77, -0.17 > . Following the same calculation procedure, the initial positions of the remaining whales can be determined.
Reasons and motivation
In the context of HHO, the energy of a hawk (E) is determined by factors including the initial energy (E0), the current iteration count (t), and the maximum iteration count (T). It is noteworthy that E0 resides within the range of (–1, 1). Specifically, when E0 falls within the interval of (0, 1), the relationship is as follows:
Therefore, for the interval where 0≤t≤t
c
, the balance between exploration and exploitation in HHO can be expressed as follows:
The development-to-exploration ratio in HHO is set at 2 or higher. During the initial iterations of the algorithm, more than two-thirds of the hawks are focused on development operations, while only a minority are allocated for exploration. This allocation results in a substantial investment of time and resources into hawk development operations. As a consequence, the effective enhancement of population diversity can be hindered or even diminished, leading to a slower initial convergence speed. Upon reaching the t
c
iterations, HHO transitions exclusively to development operations. During this phase, once a prey is locked onto, the hawks swiftly engage in capturing it. This tactical adjustment expedites the algorithm’s convergence by enabling a rapid approach towards optimal solutions. For the Beluga Whale Optimization algorithm, when B
f
= 0, t = 2T, and when t = T, B
f
= 0.5B0. As t progresses from 0 to the maximum iteration count T, the range of Bf values transitions from (0, 1) to (0, 0.5). Throughout the entirety of the BWO process, exploration and development persist concurrently. Even when a food source is locked onto, exploration continues, resulting in a certain level of resource expenditure. Within the framework of the beluga whale optimization algorithm, the balance between exploration and development is characterized by:
Specifically, the ratio of development to exploration needs to be kept at two or lower. This means that during the initial stages, hawks engage in a substantial amount of exploration. This strategic emphasis on exploration ensures a heightened level of population diversity, guarding against premature convergence to local optima. As a result, in the early stages of the beluga whale optimization algorithm, convergence is expedited.
Therefore, this paper proposes an adaptive fusion algorithm. Initially, it employs the good point set for population initialization. Subsequently, in the early iterations, it utilizes equations (27) and (28) for exploring and developing white whales, while in the later iterations, equations (10–21) are employed for white whale exploitation. Simultaneously, during each iteration, the whale fall operation is executed using equation (30).
Description of the WHO algorithm
Figure 2 depicts the flowchart of the WHO algorithm, which consists of three main components: data preprocessing, population initialization, position updates, and HUIs discovery.
Firstly, in the data preprocessing phase, the algorithm scans the database DB. For each 1-itemset in DB, it calculates its transaction-weighted utility. If the transaction-weighted utility of a 1-itemset is greater than or equal to the minimum utility threshold, it is referred to as a high transaction-weighted utility 1-itemset; otherwise, it is termed a low transaction-weighted utility 1-itemset. The 1-LTWUIs is removed from the original dataset, while the quantity of 1-HTWUIs determines the size of the population, equivalent to the problem’s dimensionality. The dataset is then restructured and transformed into a bitmap representation.
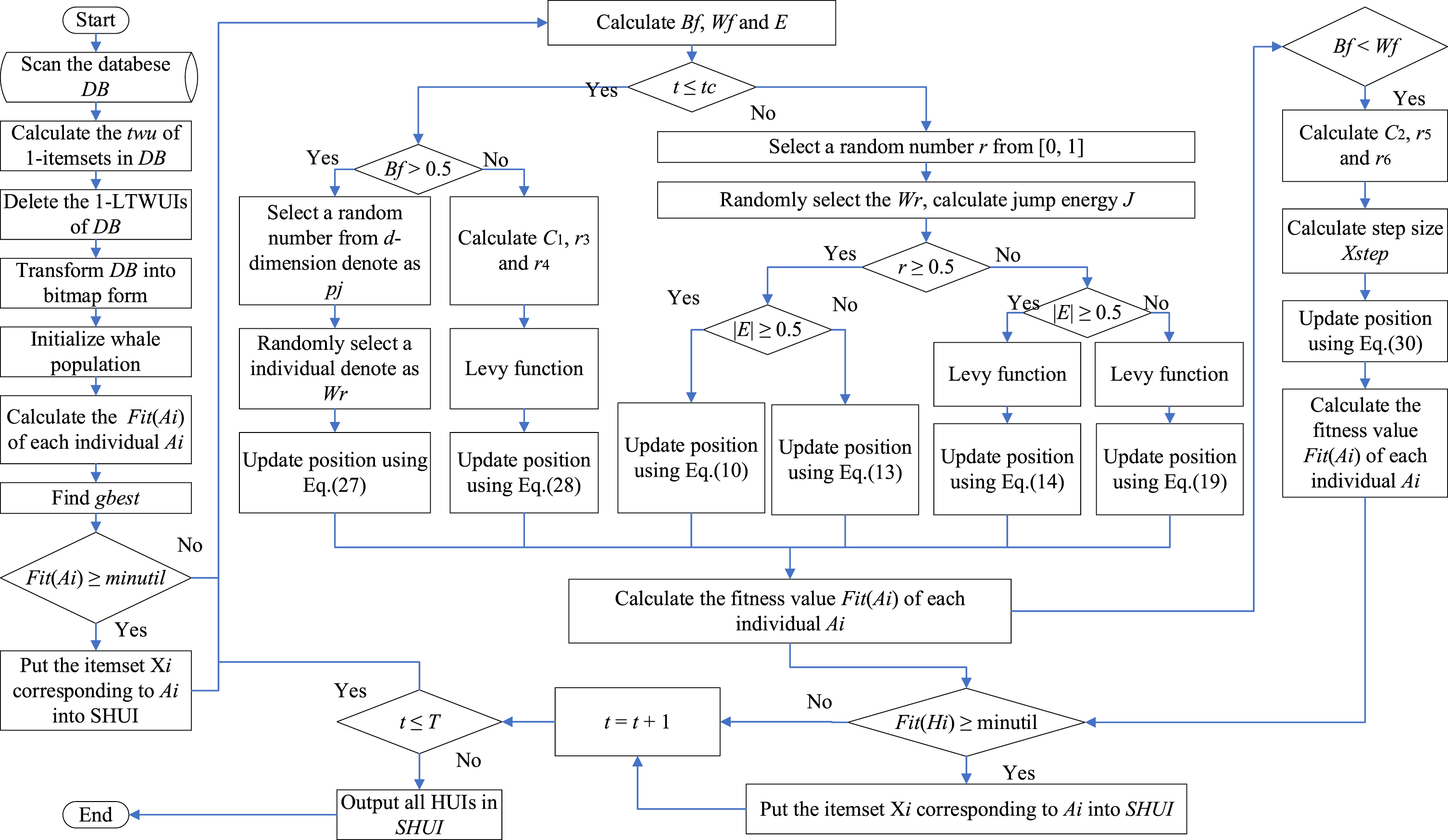
Flowchart of the WHO.
Secondly, the population is initialized, with the number of whales equal to the count of 1-HTWUIs in the dataset. Subsequently, utilizing the WHO algorithm, which hybridizes harris hawk optimization and beluga whale optimization, each individual in the population undergoes multiple iterations to update their positions, generating new individuals.
Finally, the HUIs discovery process is an integral part of each algorithm iteration. For each individual in the population, its fitness function value is computed. The individual with the highest fitness function value from the initial population is selected as the global best (gbest). If the fitness function value of an individual is not less than the minimum utility threshold, its corresponding itemset is considered a high utility itemset and is stored in SHUI (Set of high utility itemsets).
To provide a clearer understanding of the proposed algorithm, here is the pseudocode for the algorithm. Algorithm 1 presents an overview of the algorithm’s general process. Steps 1-2 involve scanning the dataset and removing all 1-itemsets with a twu below the minutil. In step 3, the dataset transforms into a bitmap representation. Step 4 involves the initialization of the population. Step 4 initializes the population by calling the
Algorithm 2 presents the pseudocode for population initialization. First, the algorithm takes as input the dataset DB, the number of 1-HTWUIs in the dataset, and the population size. The output is the initial population of whales. First, step 1 creates an empty initial population called “population”. Steps 2 to 8 assign initial positions to each individual in the population. Step 3 creates an empty individual Ai, and steps 4 to 8 represent the initialization process for each whale. The length (dimension) of each whale is equal to the number of 1-HTWUIs in the dataset. For each dimension of each whale, steps 5 to 7 calculate its position. Step 9 adds the whales with their assigned positions to the population. The algorithm iterates until the maximum number of iterations is reached.
Algorithm 3 outlines the process of population update, taking the old whale population as input and yielding a new whale population as output. For each whale within the old population, steps 2–24 are executed. Initially, step 2 generates a random number to initiate variables. Moving to step 3, a comparison is made between the current iteration count and the predefined iteration count t c . If t c has not been reached yet (steps 4–8), step 5 examines whether B f is greater than 0.5. If affirmative, the exploration phase ensues. The position is updated using equation (27), and continuous variables are transformed into Boolean ones via equation (22). In cases where B f is less than or equal to 0.5 (steps 6-7), the development phase commences. This involves calculating C1, generating two random numbers r3 and r4, invoking the Levy flight function, and ultimately updating whale positions using equation (28). Subsequently, once the iteration count surpasses t c , the HHO’s development phase unfolds (steps 10–19). Step 10 sees an update of energy values. The algorithm then leverages a random number r and the absolute value of energy E to determine the subsequent phase. In the algorithm, the whale’s position is updated based on different conditions: when r is greater than or equal to 0.5 and |E| is also greater than or equal to 0.5 (steps 11-12), formulas (10) and (22) are used for the update. When r is greater than or equal to 0.5 but |E| is less than 0.5 (steps 13-14), the update relies on formulas (13) and (22). If r falls below 0.5 while |E| remains at or above 0.5 (steps 15-16), the position is adjusted using formulas (14) and (22). In cases where both r and |E| are less than 0.5 (steps 17-18), the update employs formulas (19) and (22). Furthermore, step 21 involves checking if B f is less than W f . If this condition holds true, the algorithm calculates C2, determines the step size, and proceeds to update the whale’s position using formulas (30) and (22).
Algorithm 4 outlines the functionality of the
Time complexity of WHO
The proposed WHO consists of three main parts: population initialization, population update, and HUIs discovery. Assume that the population size is n, the maximum number of iterations is T, the dimension of each individual is d, and the time required to compute the fitness function value is timeFit.
Time complexity of population initialization is O(n×k). Time complexity of population update is O(n×d×T). Time complexity of HUIs discovery is O(n×T×timeFit). Then the overall time complexity of WHO is O(n×d + n×d×T + n×T×timeFit) = O(n×T×(d + timeFit)).
Experiments
In this chapter, experimental evaluations are carried out from three crucial perspectives: convergence, recall rate, and runtime, aiming to comprehensively assess the efficacy of the proposed algorithm. The experimental datasets encompass chess, connect, mushroom, accidents, foodmart, and retail, each characterized by parameters outlined in Table 5. In which, “No. T” represents the number of transactions, “No. I” represents the number of items, and “Avg. TL” represents the average transaction length.
Datasets parameters
Datasets parameters
As shown in Table 6, the experimental environment boasts 15.7GB of available RAM, an Intel Core i9-12900 H @ 2.50 GHz CPU, and operates on the Windows 11 platform. Across all algorithms, the population size is uniformly set to 100, and the upper limit for iterations is established at 1000. The settings of other experiment parameters are shown in Table 7. Given the inherent stochastic nature of intelligent optimization algorithms, leading to notable result variations, all data presented in this section represent averages derived from 10 individual runs.
Experimental environment settings
Experiment parameters settings
In this section, we delve into an in-depth comparison of the convergence performance among particle swarm optimization, genetic algorithm, artificial fish swarm algorithm, bat algorithm, and the hybridized WHO algorithm proposed in this paper. To rigorously analyze the convergence trends, a series of experiments were conducted across six datasets. Each algorithm underwent 1000 iterations for every dataset and threshold combination. Figure 3 illustrates the convergence trends of the various algorithms across different datasets and thresholds. The x-axis represents the iteration count, while the y-axis denotes the number of HUIs that each algorithm is capable of uncovering.
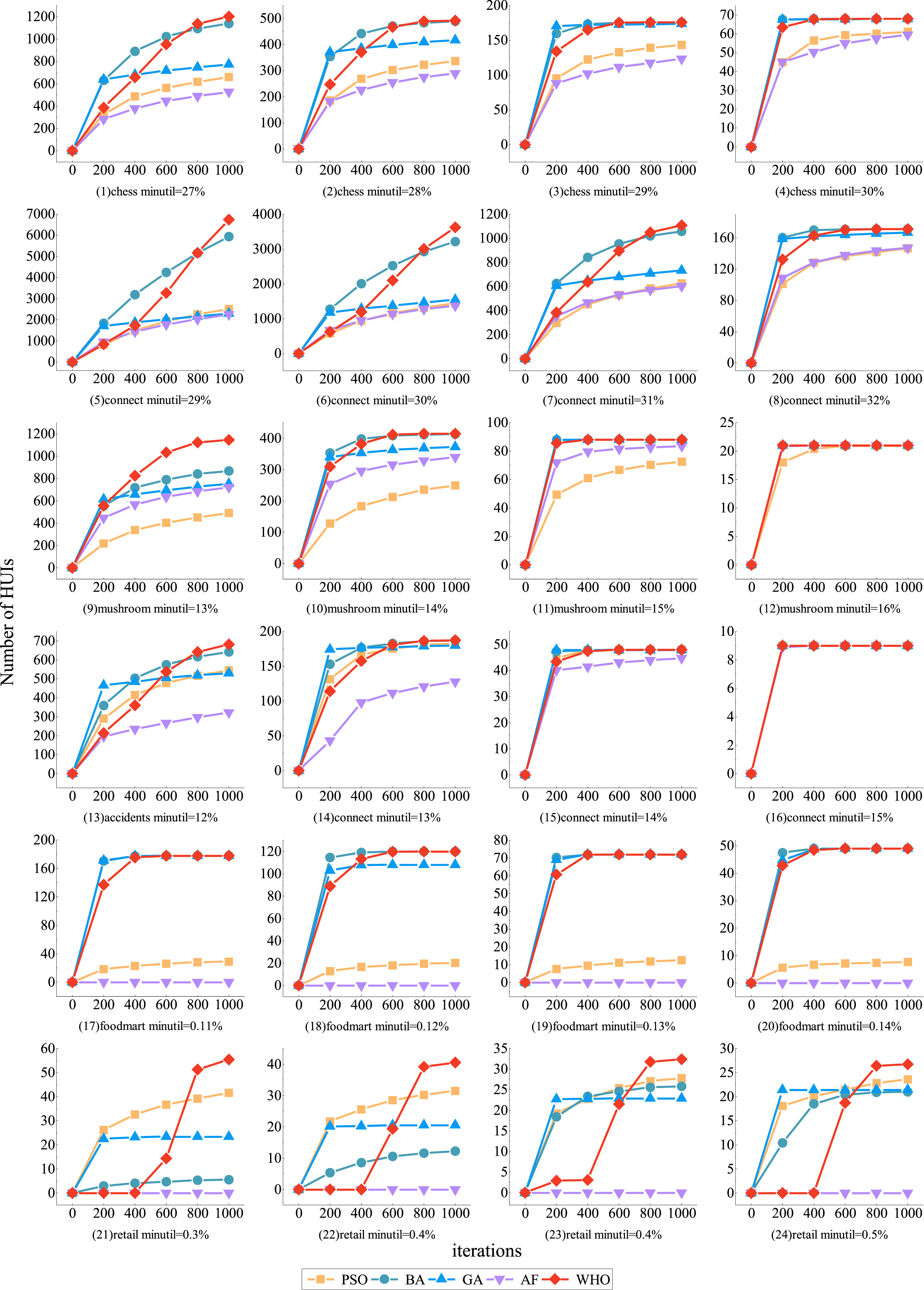
Comparison of Convergence.
Moreover, in the chess dataset, a distinctive trend emerges. When the threshold is set at 27%, the GA demonstrates a notably swifter convergence rate within the initial 0–200 iterations. Nevertheless, beyond 200 iterations and up to 1000, GA’s convergence speed notably decelerates, indicating a potential entrapment in a local optimum around the 200th iteration. Conversely, BA exhibits swift convergence during the 0–600 iteration phase, followed by a somewhat slower pace between 600 and 800 iterations. Notably, both the PSO and AF algorithms maintain a consistently gradual convergence rate, with their final convergence values falling significantly below those achieved by the WHO algorithm. Consequently, they unearth only half the number of HUIs. As the threshold gradually escalates, a general enhancement in the convergence performance of all algorithms becomes evident. This can be attributed to the diminishing count of itemsets meeting the high utility threshold as the threshold value increases, simplifying their swift detection. Remarkably, by the time the threshold reaches 30%, barring AF and PSO, all other algorithms achieve complete convergence before reaching the 200-iteration mark, effectively and efficiently uncovering the entire set of HUIs.
In the connect dataset, when the threshold is set at 29%, the BA demonstrates the highest convergence rate within the 0–600 iterations, followed by the proposed WHO algorithm. However, as the iterations progress into the 600–1000 range, BA’s convergence speed gradually diminishes, and its final convergence value settles around 6000, which is merely 88% of the value achieved by the WHO algorithm. The convergence of the proposed WHO algorithm is optimal between 800 and 1000 iterations, and the number of itemsets continues to grow. If the algorithm’s iteration count could be increased, the WHO algorithm has the potential to uncover even more high utility itemsets beyond this point.
In the mushroom dataset, it is a clear trend emerges that as the threshold increases from 13% to 16%, the WHO algorithm showcases superior convergence performance. Notably, as the threshold rises, the convergence patterns of all algorithms gradually converge as well. When the threshold is set at 13%, the final convergence values achieved by the WHO algorithm are 2.33, 1.32, 1.52, and 1.58 times those of the PSO, BA, GA, and AF algorithms, respectively. Specifically, when the threshold is set at 15%, the WHO, BA, and GA algorithms all achieve complete convergence within the first 400 iterations, whereas the AF and PSO algorithms do not achieve complete convergence. As the threshold elevates to 16%, all algorithms achieve complete convergence within the first 400 iterations.
In the accidents dataset, when the threshold is set at 12%, the GA displays the swiftest convergence rate during the initial 0–200 iterations, closely followed by the BA. However, as the number of iterations surpasses 600, both GA and BA gradually become ensnared in local optima. At 13% and 14% thresholds, except for the underperforming AF algorithm, the remaining algorithms showcase commendable convergence performance. Upon reaching a 15% threshold, all algorithms manage to achieve their maximum convergence values within the first 200 iterations.
In the foodmart dataset, as the threshold increases from 0.11% to 0.14%, the algorithm with the best convergence performance is BA, with the WHO algorithm closely following behind BA. Conversely, the PSO algorithm demonstrates relatively subpar convergence, while the AF algorithm exhibits the weakest convergence performance. This discrepancy can be attributed to the sparse characteristics of the foodmart dataset, where the AF algorithm’s runtime extends beyond 24 hours without completing the initial 200 iterations, thereby hindering the acquisition of conclusive experimental outcomes.
In the retail dataset, although the WHO algorithm initially exhibits slightly slower convergence performance compared to the PSO, GA, and BA algorithms, its convergence speed significantly accelerates during the iterations ranging from 600 to 1000. Furthermore, the WHO algorithm ultimately achieves a far higher convergence value than the other comparative algorithms.
By comparing the quantities of high utility itemsets discovered through different algorithms, we can conduct a comprehensive analysis of their recall rates. Table 8 outlines the recall rates for each algorithm. Notably, across all datasets, as the threshold is increased, the recall rates of the algorithms steadily rise. This phenomenon is a result of the diminishing count of itemsets meeting the minimum utility threshold as the threshold value increases. As a consequence, algorithms can more readily identify a greater number, or even the entirety, of high utility itemsets.
Recall comparison (Bold indicates the best, and the number inside parentheses represents the algorithm’s ranking.)
Recall comparison (Bold indicates the best, and the number inside parentheses represents the algorithm’s ranking.)
In the chess dataset, the proposed WHO algorithm exhibits the highest recall rate. Specifically, within the threshold range of 29–30%, it achieves a remarkable 100% recall rate, effectively capturing all the high utility itemsets present in the dataset. Even at a threshold of 27%, the WHO algorithm maintains a robust recall rate of 96.48%, with only a marginal number of itemsets being missed. Furthermore, WHO outperforms other algorithms by discovering high utility itemsets 2.29 times more than AF, 1.82 times more than PSO, and 1.56 times more than GA. The second-highest recall rate is observed with the BA algorithm.
In the case of the connect dataset, at a threshold of 29%, the algorithms attain a peak recall rate of 36.84%. This can be attributed to the dataset’s unique attributes— comprising a substantial 67,557 transactions and 129 items— resulting in a sizable and dense dataset. Given the constraint of 1000 iterations, the algorithms face a challenge in unearthing a large quantity of HUIs within such a dense data space. Extending the iteration count might enhance the recall rate further. As depicted in Table 5, the WHO algorithm boasts the highest recall rate, closely followed by BA. Particularly noteworthy is that at a 30% threshold, the WHO algorithm outperforms PSO, AF, BA, and GA in recall rate by factors of 2.51, 2.65, 1.13 and 2.35, respectively. Upon raising the threshold to 32%, only WHO and BA succeed in achieving a flawless 100% recall rate, indicating their capability to uncover the entirety of high utility itemsets at that juncture.
In the mushroom dataset, it is quite apparent that the WHO algorithm boasts the highest recall rate. At a threshold of 13%, it achieves an impressive recall rate of 99.38%, and this rate increases to 100% as the threshold continues to rise. Furthermore, with a threshold of 15%, not only WHO but also the BA and GA algorithms achieve a perfect 100% recall rate. Similarly, when the threshold climbs to 16%, the AF algorithm’s recall rate also reaches a flawless 100%.
In the accidents dataset, the WHO algorithm demonstrates the highest recall rate, followed by PSO, BA, GA, and AF. At a threshold of 12%, the recall rate of WHO is 1.25 times that of PSO, 2.12times that of AF, 1.06 times that of BA, and 1.29 times that of GA.
In the foodmart dataset, both the WHO and BA algorithms achieve a 100% recall rate, meaning they can mine all the high utility itemsets present in the dataset. In contrast, the AF algorithm has a recall rate of 0% because it runs for more than 24 hours without obtaining any high utility itemsets.
For the retail dataset, the WHO algorithm achieves the highest recall rate. At a threshold of 0.3%, the recall rate of WHO is 1.35 times that of PSO, 11.08 times that of BA, and 2.41 times that of GA. Similarly, at a threshold of 0.4%, the recall rate of WHO is 1.31 times that of PSO, 3.38 times that of BA, and 2.03 times that of GA. At a threshold of 0.5%, the recall rate of WHO is 1.20 times that of PSO, 1.30 times that of BA, and 1.47 times that of GA. Finally, at a threshold of 0.6%, the recall rate of WHO is 1.16 times that of PSO, 1.27 times that of BA, and 1.27 times that of GA.
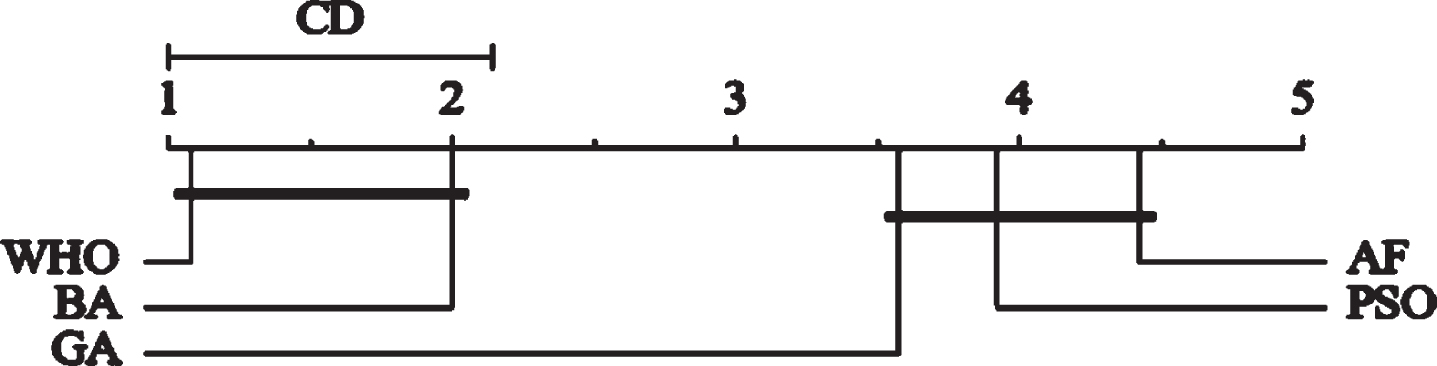
We performed a nonparametric statistical significance test on the experimental data. Figure 4 shows the Bonferroni-Dunn statistical analysis of Recall. where the CD value is calculated as in Eq. (40), where q α is fixed to 2.498, k is the number of algorithms, and N is the size of the dataset. In this paper, k is taken as 5 and N is 24, so the CD is calculated as 1.14.
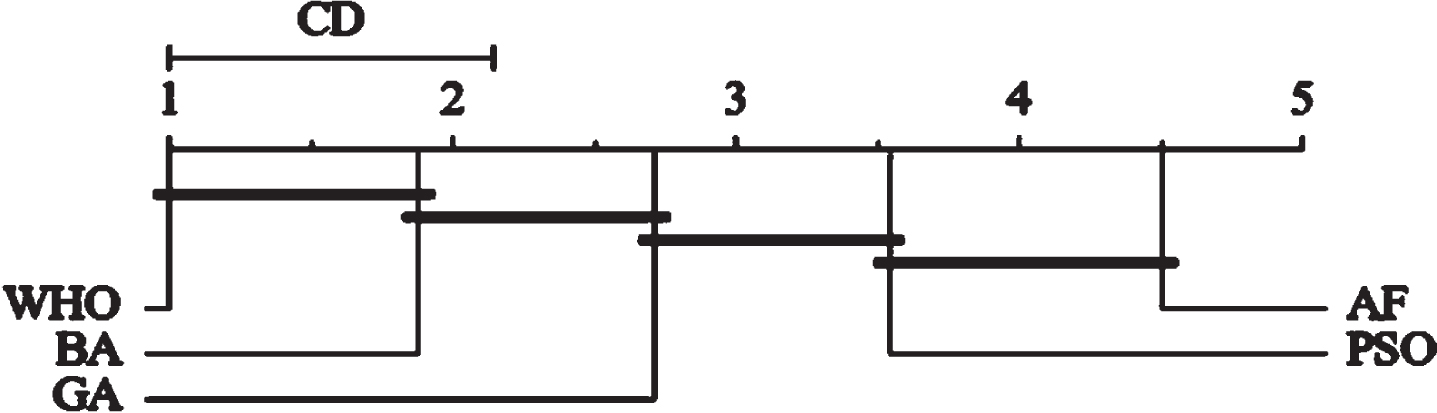
Bonferroni-Dunn statistical analysis on Recall.
From the figure, it can be seen that the proposed algorithm WHO is significantly different from the three algorithms except BA. According to Equation (40), when the number of algorithms is 5, the number of datasets N is taken as 32 in order to make the CD value less than 1. While the algorithm WHO has been ranked first and the average ranking of BA is 1.88, so it does not have a significant difference, but WHO is significantly better than BA.
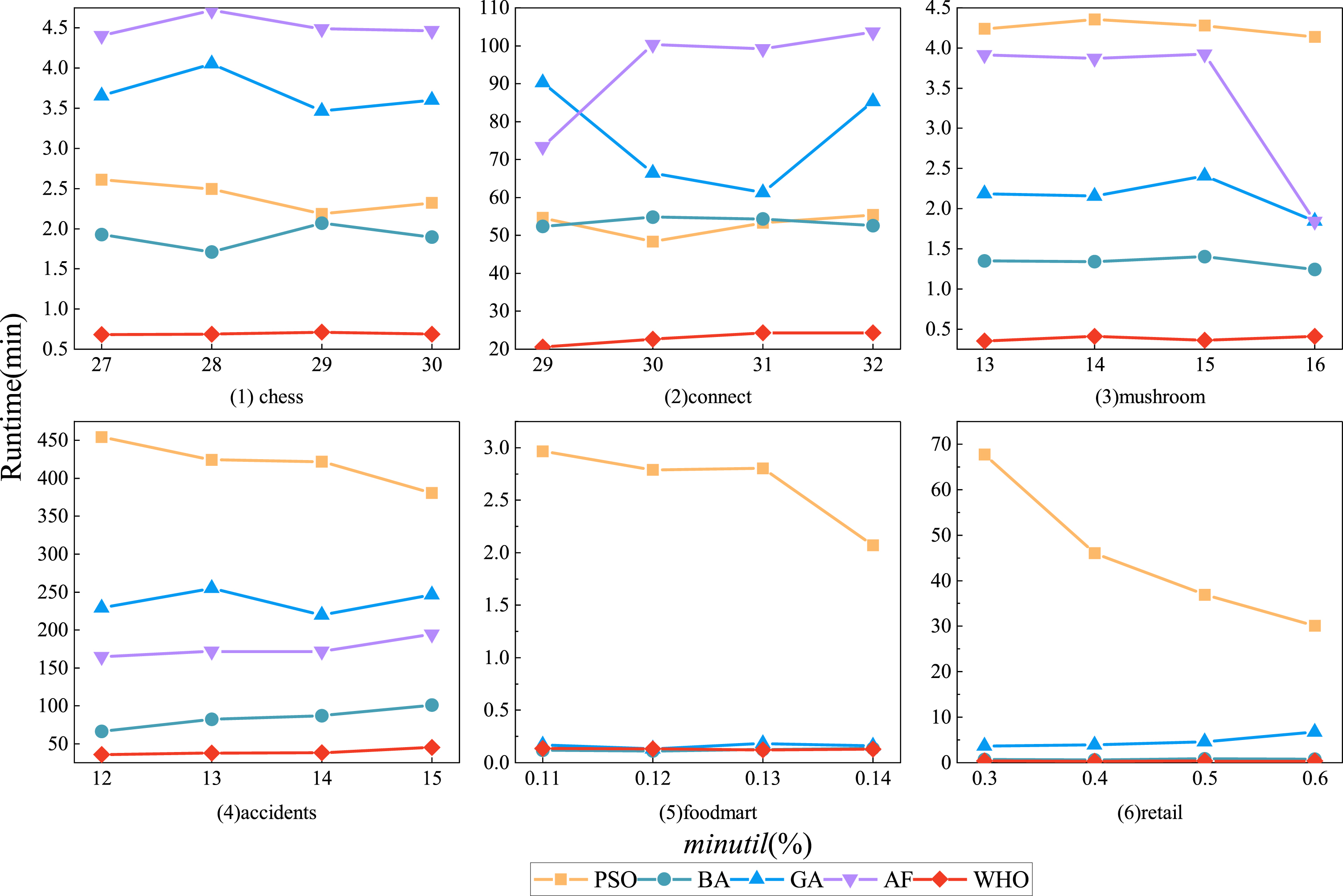
In this subsection, we delve into the comparison of algorithm runtimes. Figure 3 provides insight into the trend of algorithm runtimes as they vary with different thresholds.
Notably, the AF algorithm’s runtime exceeded 24 hours for the sparse datasets foodmart and retail, without yielding any results, hence, it’s not depicted in the figure. Unlike traditional methods for mining high utility itemsets, the runtime of intelligent optimization-based algorithms doesn’t decrease with increasing thresholds. Instead, it exhibits a higher degree of stability. This phenomenon is mainly attributed to the fact that the runtime of intelligent optimization-based algorithms is primarily influenced by factors such as the maximum iteration count and the approach used to update the population, with a lesser dependency on the threshold.
In the chess dataset, Algorithm WHO stands out with a lower runtime compared to the other comparative algorithms. Specifically, the runtime ratios of PSO, BA, GA, and AF to WHO are 3.47, 2.74, 5.33 and 6.52, respectively. Moving to the connect dataset, Algorithms WHO, BA and PSO maintain relatively stable runtimes, while AF and GA experience more noticeable fluctuations as the threshold varies. The runtime ratios of PSO, BA, GA, and AF to WHO are 2.31, 2.33, 3.31 and 4.10, respectively. In the mushroom dataset, Algorithms WHO, BA and PSO exhibit higher runtime stability, followed by GA. Notably, AF’s runtime fluctuates largely as the threshold shifts from 15% to 16%. The runtime ratios of PSO, BA, GA, and AF to WHO are 11.08, 3.47, 5.59 and 8.82, respectively. Shifting focus to the accidents dataset, WHO maintains the lowest runtime, followed by BA, AF, GA, and PSO, with runtime ratios of 10.73, 2.15, 6.06 and 4.49 to WHO, respectively. In the sparse foodmart dataset, all algorithms, except for PSO, boast relatively low runtimes and are capable of completing iterations within one minute. Finally, in the retail dataset, Algorithm WHO again showcases the lowest runtime, with PSO’s runtime being 120.76 times that of WHO.
Next the nonparametric statistical significance test of Runtime of the algorithm is performed using Bonferroni-Dunn method. Table 9 shows the runtimes of the algorithms along with their rankings. Figure 5 shows the Bonferroni-Dunn statistical analysis of Runtime. As can be seen from the figure, the proposed algorithm WHO significantly outperforms the algorithms GA, PSO as well as AF. When compared to the algorithm BA, although there is no significance difference, the WHO’s runtime is significantly better than BA in general.
Bonferroni-Dunn statistical analysis on Runtime.
Runtime(min)
For memory usage, it is primarily influenced by the population size and the dimensionality of individuals in terms of space. When the population size is the same, the memory consumption of various algorithms is not significantly different, so no comparison is made.
In the subsequent analysis, we conduct a performance comparison of the proposed WHO algorithm and the hybrid DE-BGWO algorithm in terms of two key aspects: execution time and recall rate. Figure 4 provides a visual representation of the execution time comparison. As depicted in Fig. 7, it is evident that the WHO algorithm demonstrates considerably shorter execution times in comparison to the DE-BGWO algorithm. This observation underscores the superior efficiency of the WHO algorithm in terms of computational speed.
Comparison of Runtime.

Comparison of runtime with DE-BGWO.
In connect dataset, when the threshold is set at 31.2%, the DE-BGWO algorithm takes 22492 seconds to complete the mining process, whereas the proposed WHO algorithm accomplishes the task in just 1362 seconds, representing approximately 7% of the DE-BGWO algorithm’s runtime. When the threshold is raised to 31.4%, the DE-BGWO algorithm requires 23552 seconds to run, while the WHO algorithm runs for 1303 seconds, roughly 6% of the DE-BGWO algorithm’s runtime. As the threshold increases to 31.6%, the WHO algorithm operates for 1520 seconds, whereas DE-BGWO takes 25276 seconds, making DE-BGWO approximately 16.63 times slower than WHO. At a threshold of 31.8%, the WHO algorithm runs for 1533 seconds, while DE-BGWO runs for 23944 seconds, making DE-BGWO roughly 15.62 times slower than WHO. Finally, with a threshold of 32%, the WHO algorithm completes its process in 1459 seconds, whereas DE-BGWO takes 23909 seconds, making DE-BGWO approximately 16.38 times slower than WHO.
In the accident 8% dataset, when the thresholds are set at 13.3%, 13.5%, 13.7%, 13.9%, and 14.1%, the DE-BGWO algorithm’s runtimes are 53.35, 54.89, 53.22, 54.18, and 55.40 times longer than that of the WHO algorithm, respectively. This indicates that the proposed WHO algorithm not only improves efficiency but also offers significant time savings for handling large-scale tasks. It is particularly well-suited for complex tasks that require efficient processing.
In the chess dataset, the DE-BGWO algorithm’s average runtime is 61.27 times longer than that of the WHO algorithm. When the thresholds are set at 28.3%, 28.5%, 28.7%, 28.9%, and 30.1%, the WHO algorithm’s runtimes are 1.68%, 1.86%, 1.56%, 1.54%, and 1.56% of the DE-BGWO algorithm’s runtime, respectively.
In the mushroom dataset, the DE-BGWO algorithm’s average runtime is 53.74 times longer than that of the WHO algorithm. When the thresholds are set at 14.2%, 14.4%, 14.6%, 14.8%, and 15%, the WHO algorithm’s runtimes are 2.15%, 1.92%, 1.67%, 1.83%, and 1.79% of the DE-BGWO algorithm’s runtime, respectively.
Table 10 presents an analysis of the recall rates for the proposed WHO algorithm and the DE-BGWO algorithm. The recall rate of an algorithm is calculated as the ratio of the number of HUIs mined by the algorithm to the total number of HUIs in the dataset.
Comparison of recall rate with DE-BGWO
From the table, we observe that in the connect dataset, when the thresholds are set at 31.2% and 31.4%, the recall rate of the WHO algorithm is 1.55% and 0.26% lower than that of the DE-BGWO algorithm, respectively. At a threshold of 31.6%, both algorithms achieve the same recall rate of 99.95%. When the threshold is increased to 31.8% and 32%, the WHO algorithm reaches a 100% recall rate, while the DE-BGWO algorithm achieves recall rates of 99.78% and 99.38%, respectively. In the accident 8%, chess, and mushroom datasets, the WHO algorithm is able to mine all high utility itemsets with a recall rate of 100%, while the DE-BGWO algorithm falls short of achieving a 100% recall rate.
In this Chapter, the performance of the proposed WHO is evaluated in terms of convergence, recall rate, and Runtime.
For convergence, the algorithm WHO has the best convergence performance in chess, connect, mushroom, accidents, retail. And the convergence performance in foodmart dataset is ranked 3rd. This is because the average transaction length of the foodmart dataset is 4.42, the distribution of the HUIs is very decentralized, and the proposed method WHO requires extensive exploration to find the HUIs in the initial run of the algorithm. Therefore, one of the advantages of WHO is good convergence performance. The disadvantage is slightly poor convergence in datasets that are too sparse and have a small average transaction length.
In terms of recall rate, the proposed WHO achieves the highest recall rate across all datasets. This indicates that the proposed algorithm has high mining capability and good convergence, and is able to mine a larger number of HUIs in a limited time.
In terms of runtime, in the remaining five datasets except foodmart dataset, the running time of the proposed WHO is much shorter than the other compared algorithms and has the best stability. This indicates that this study can effectively improve the mining efficiency of the algorithm. Therefore, the additional advantages of the proposed WHO are higher efficiency and the runtime is less affected by the threshold value.
In summary, this study can effectively solve the problem that the heuristic-based HUIM algorithms are easy to trap in local optimum, which leads to a large number of missing itemsets. Additionally, this study improves the efficiency of heuristic-based HUIM methods.
High utility itemsets mining has widespread real-world applications in various domains, including retail, e-commerce, market basket analysis, healthcare, logistics and supply chain management, social networks, finance, production, and manufacturing, among others. In the retail industry, it assists businesses in optimizing inventory management and promotional strategies. E-commerce platforms can increase sales volume and customer satisfaction through it. In the healthcare sector, it can be utilized for disease factor analysis. In the financial sector, it can be employed for risk management and transaction analysis. In the realm of social networks, it can be utilized for content recommendation and targeted advertising. These are just a few of the many real-world application areas where HUIM provides valuable insights and assistance across industries.
Conclusion
High utility itemsets mining aims to mine out significant itemsets in the transaction database. In recent years, heuristic algorithms have been widely used in HUIM. In order to solve the problem that the current heuristic-based HUIM method is easy to fall into local optimization and lose a large number of itemsets. This paper proposes a new intelligent optimization algorithm that integrates harris hawk optimization and beluga whale optimization. The initialization strategy of whales based on good point set is proposed and designed, which helps to improve the diversity of the population and can improve the shortcomings of poor quality and stability of the population, which is easy to fall into the local optimization. In order to test the performance of the proposed algorithm, a large number of experiments are conducted on six real datasets of chess, connect, mushroom, accidents, foodmart, and retail in terms of convergence, recall rate, and runtime of the algorithm. Experimental results show that the proposed algorithm outperforms the current state-of-the-art heuristic-based HUIM algorithms. It can be concluded that the advantages of the proposed algorithm WHO are good convergence performance; high mining capability, good convergence, higher efficiency and the runtime is less affected by the threshold value. The disadvantages are slightly poor convergence in datasets that are too sparse and have a small average transaction length. In the future, our research group will continue to develop more efficient heuristic-based HUIM algorithms, like ant lion optimization (ALO) [51]-based and GWO [10]-based HUIM algorithms.
Funding
This work was supported by the National Nature Science Foundation of China (62062004) and the Ningxia Natural Science Foundation Project (2023AAC03315).
Author contributions
Zhihui Gao and Meng Han wrote the main manuscript text. Shujuan Liu, Ang Li and Dongliang Mu helped revise the manuscript format and collect data. All authors reviewed the manuscript.